非结构化医疗文本无监督症状自动识别方法、系统、装置与流程
本发明属于文本挖掘领域,具体涉及了一种非结构化医疗文本无监督症状自动识别方法、系统、装置。
背景技术:
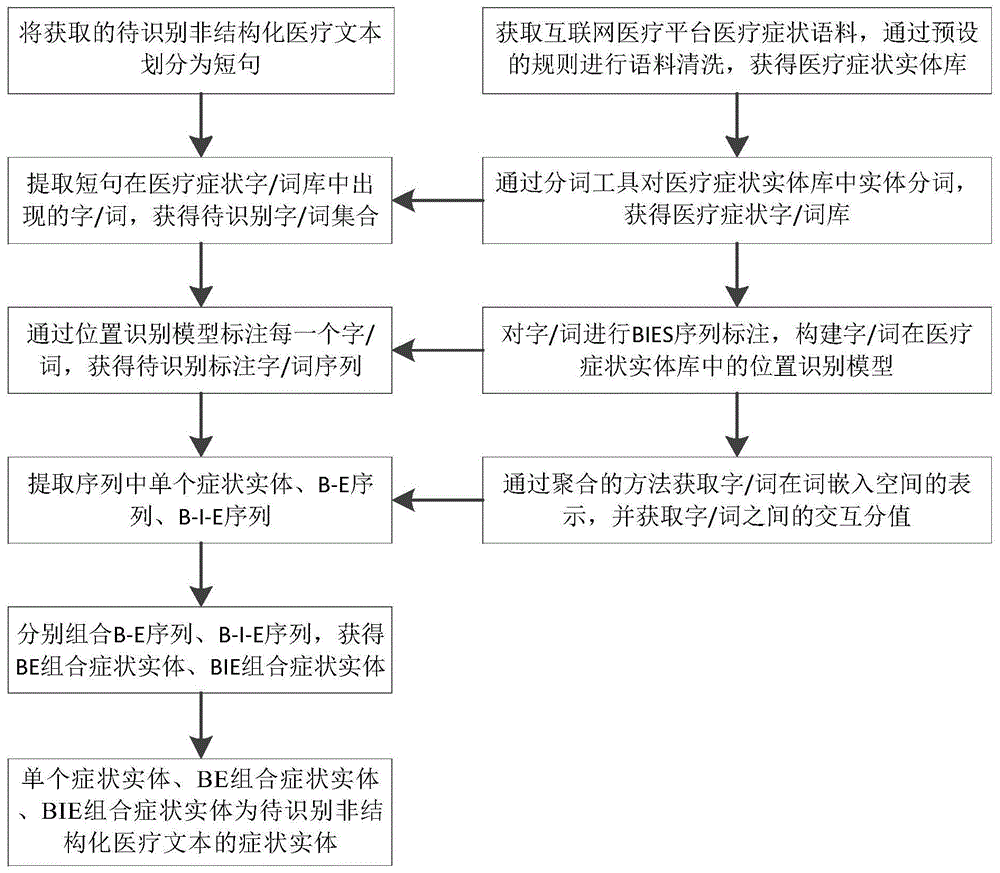
:更准确地诊断出疾病,更快速地找到疾病问题的解决方案,是医学界乃至全世界不断追求的目标。近年来,生物医学出版物和互联网医疗应用的数量稳步增长,通过多种形式提供了空前数量的信息。随着现有知识的加速增长,特别是生物医学文献和学科边界的打破,手工跟踪所有新的相关发现,即使是专门的主题的相关发现,已经变得不可行。此外,大部分的生物医学文本以及医疗病患数据并不是很有用,而一些关键知识中的大部分仍然以非结构化文本信息的形式埋藏着,这样的非结构化文本信息中却蕴藏着大量的科学事实和患者最直接、最真实的健康信息和病例信息,并且这样的数据也有着广泛的参与人群,有着巨大的医学价值。提高对于大规模信息的利用率,充分的挖掘其中潜藏的价值,得到的结果可以为用户提供更加丰富的医疗服务。比如,构建医疗知识图谱,在此基础上开发相关的应用,或者对病患信息进行并发症的检索,有助于医生为用户提供更加精确的诊断,也有助于专家扩充自己的知识积累。目前,在医疗和计算机领域,针对各种的医学文献、生物医学出版物以及电子病历报告等的数据挖掘方法已有不少,但是其中许多方法都需要特征工程和专家知识来获得良好的性能,无法完全自动化。此外,对于极其不规范的、含有大量不完整口语表达的非结构化文本数据的挖掘分析工作却不是很多。近年来,基于深度学习的词嵌入技术被认为是一种更加先进的无监督处理虚拟信息的方法。词嵌入是一个术语,用于定义一组用于语言建模和特征学习的方法,其中词表中的词汇被映射成连续的高维空间中的向量,通常是几百维。在这种表示中,语料库中共享相似上下文的单词位于单词嵌入向量空间中非常接近的位置。除了表示单词的分布特征外,词向量还可以捕获文本中单词的语义和顺序信息,比基于频率的方法提供了更丰富的向量表示。目前中文电子病历信息的识别仍属于起步阶段。在深度学习技术发展以来,基于深度神经网络的命名实体识别成为主流技术,一些学者采用了双向lstm网络作为编码器,用单向lstm网络作为解码器对电子新闻文本进行识别取得了不错的效果。一些学者采用各种深度学习算法进行识别,最后采用卷积神经网络的模型得到了一个相对比较好的效果。虽然这些方法表现出了词嵌入的通用性,且可以调用当前的自然语言处理工具进行文本分析,但是仍然缺少能够以完全无监督的方式自动从非结构化文本抽取信息的方法。而且,基于深度学习的方法具有很高的不可解释性,这对于医学领域来说是个很大的弊端,目前还没有计算复杂度低且具有一定可解释性的医疗文本挖掘方法。因此,急需能够自动分析文本来源、提取事实和知识并生成概括表示的新方法,以捕获疾病症状最相关的信息。技术实现要素:为了解决现有技术中的上述问题,即现有医疗文本疾病症状自动识别方法计算复杂度高、具有很高的不可解释性的问题,本发明提供了一种非结构化医疗文本无监督症状自动识别方法,该症状自动识别方法包括:步骤s10,获取互联网医疗平台医疗症状语料,并通过预设的规则进行语料数据清洗,获得医疗症状实体库;步骤s20,通过分词工具对所述医疗症状实体库中实体进行分词,并通过bies序列标注策略对分词后的医疗症状字/词库中每一个字/词进行标注,构建字/词在医疗症状实体库中的位置识别模型;步骤s30,通过聚合的方法获取所述医疗症状字/词库中每一个字/词在词嵌入空间的表示,并计算所述词嵌入空间中字/词之间的交互分值;步骤s40,将待识别非结构化医疗文本划分为短句,并提取所述短句在所述医疗症状字/词库中出现过的字/词,获得待识别字/词集合;步骤s50,通过所述位置识别模型对所述待识别字/词集合中每一个字/词进行标注,获得待识别标注字/词序列;步骤s60,基于所述待识别标注字/词序列、词嵌入空间中字/词之间的交互分值,获取待识别非结构化医疗文本的症状实体。在一些优选的实施例中,步骤s20中“通过bies序列标注策略对分词后的医疗症状字/词库中每一个字/词的位置进行标注,构建字/词在医疗症状实体库中的位置识别模型”,其方法为:步骤s21,将所述医疗症状实体库中分词后未拆分的实体作为单个症状实体词,并标注s;将所述医疗症状实体库中被拆分为多个字/词的实体的首位字/词标注为b,末尾字/词标注为e,中间字/词标注为i;步骤s22,基于标注后的医疗症状字/词库,构建字/词在医疗症状实体库中的位置识别模型。在一些优选的实施例中,步骤s30中“通过聚合的方法获取所述医疗症状字/词库中每一个字/词在词嵌入空间的表示”,其方法为:步骤s311,以所述医疗症状字/词库中字/词为节点,直接上下文关系为边,构建异质文本图;步骤s312,通过聚合所述异质文本图中节点附近的一阶邻居节点获得每个字/词在词嵌入空间的表示。在一些优选的实施例中,步骤s30中“计算所述词嵌入空间中字/词之间的交互分值”,其方法为:步骤s321,通过聚类算法结合近邻算法获取所述词嵌入空间中相邻字/词的数量和簇占用率;步骤s322,基于所述词嵌入空间中相邻字/词的数量和簇占用率,通过向量相似性度量法获取词嵌入空间中字/词之间的交互分值。在一些优选的实施例中,步骤s321中“通过聚类算法结合近邻算法获取所述词嵌入空间中相邻字/词的数量和簇占用率”,其方法为:步骤s3211,基于所述词嵌入空间,分别建立两两字/词之间的向量,获得向量集合,并通过聚类算法对所述向量集合进行聚类,获得每个字/词的聚类类别特征;步骤s3212,基于所述每个字/词的聚类类别特征、字/词和向量建立索引,获得三个特征的一一映射关系;对所述向量集合中任一向量,通过近邻算法获取其距离最近的k个向量,并获取k个向量对应每个聚类类别的离散概率分布;步骤s3213,基于所述三个特征的一一映射关系、k个向量对应每个聚类类别的离散概率分布,获得相邻字/词的数量和簇占用率。在一些优选的实施例中,步骤s322中“通过向量相似性度量法获取词嵌入空间中字/词之间的交互分值”,其方法为:步骤s3221,基于所述相邻字/词的数量和簇占用率构建离散概率分布矩阵,并分别计算词嵌入空间中两两字/词之间的距离;步骤s3222,基于所述词嵌入空间中两两字/词之间的距离,通过预设的得分函数计算词嵌入空间中字/词之间的交互分值。在一些优选的实施例中,步骤s60中“基于所述待识别标注字/词序列、词嵌入空间中字/词之间的交互分值,获取待识别非结构化医疗文本的症状实体”,其方法为:步骤s61,提取所述待识别标注字/词序列标注为s的字/词,获得单个症状实体、剩余带标注字/词序列;步骤s62,判断所述剩余带标注字/词序列长度是否大于1,是则使用正向匹配和反向回溯算法遍历所述剩余带标注字/词序列,获取连续的b-i-e序列、b-e序列;步骤s63,组合所述b-e序列,获得be组合症状实体;分别获取每个b-i-e序列中间字/词和首位字/词、末尾字/词的交互分值并计算均值,所述均值大于设定阈值的中间字/词与首位字/词、末尾字/词组合,获得bie组合症状实体;步骤s64,所述单个症状实体、be组合症状实体、bie组合症状实体为待识别非结构化医疗文本的症状实体。本发明的另一方面,提出了一种非结构化医疗文本无监督症状自动识别系统,该症状自动识别系统包括输入模块、医疗症状实体库、医疗症状字/词库、位置识别模块、交互分值获取模块、症状实体提取模块、输出模块;所述输入模块,配置为将待识别非结构化医疗文本划分为短句,并提取所述短句在所述医疗症状字/词库中出现过的字/词,获得待识别字/词集合并输入;所述医疗症状实体库,配置为获取互联网医疗平台医疗症状语料,并通过预设的规则进行语料数据清洗,获得医疗症状实体库;所述医疗症状字/词库,配置为通过分词工具对所述医疗症状实体库中实体进行分词,获得医疗症状字/词库;所述位置识别模型,配置为通过bies序列标注策略对医疗症状字/词库中每一个字/词进行标注后构建位置识别模型,并通过所述位置识别模型对所述待识别字/词集合中每一个字/词进行标注,获得待识别标注字/词序列;所述交互分值获取模块,配置为通过聚合的方法获取所述医疗症状字/词库中每一个字/词在词嵌入空间的表示,并计算所述词嵌入空间中字/词之间的交互分值;所述症状实体获取模块,配置为基于待识别标注字/词序列、词嵌入空间中字/词之间的交互分值,获取单个症状实体、be组合症状实体、bie组合症状实体;所述输出模块,配置为输出获取的单个症状实体、be组合症状实体、bie组合症状实体作为待识别非结构化医疗文本的症状实体。本发明的第三方面,提出了一种存储装置,其中存储有多条程序,所述程序适于由处理器加载并执行以实现上述的非结构化医疗文本无监督症状自动识别方法。本发明的第四方面,提出了一种处理装置,包括处理器、存储装置;所述处理器,适于执行各条程序;所述存储装置,适于存储多条程序;所述程序适于由处理器加载并执行以实现上述的非结构化医疗文本无监督症状自动识别方法。本发明的有益效果:(1)本发明非结构化医疗文本无监督症状自动识别方法,利用自动获取的症状词典,综合考虑实体之间交互关系,充分挖掘症状实体之间的潜在关系,形成具有良好泛化能力的预测模型,可以有效识别未见症状,避免了采用深度学习方法中的不可解释性问题,模型计算复杂度低、精度高、鲁棒性好。(2)本发明方法实现医学症状实体的无监督自动抽取,同时以症状为线索可以强有力地支持医学智能辅助诊断服务以及医学知识图谱的自动构建,不需要专家和手工的管理,可以自动地对训练数据进行标注,节约了大量人力、物力成本,还可以最大程度地减轻人工标注数据的错误率高、效率低的问题。附图说明通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本申请的其它特征、目的和优点将会变得更明显:图1是本发明非结构化医疗文本无监督症状自动识别方法的流程示意图;图2是本发明非结构化医疗文本无监督症状自动识别方法一种实施例的位置识别模型构建流程示意图;图3是本发明非结构化医疗文本无监督症状自动识别方法一种实施例的获取词嵌入空间中字/词之间交互分值的流程示意图;图4是本发明非结构化医疗文本无监督症状自动识别方法一种实施例的异质文本图;图5是本发明非结构化医疗文本无监督症状自动识别方法一种实施例的获取待识别非结构化医疗文本症状实体的流程示意图。具体实施方式下面结合附图和实施例对本申请作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。本发明的一种非结构化医疗文本无监督症状自动识别方法,该症状自动识别方法包括:步骤s10,获取互联网医疗平台医疗症状语料,并通过预设的规则进行语料数据清洗,获得医疗症状实体库;步骤s20,通过分词工具对所述医疗症状实体库中实体进行分词,并通过bies序列标注策略对分词后的医疗症状字/词库中每一个字/词进行标注,构建字/词在医疗症状实体库中的位置识别模型;步骤s30,通过聚合的方法获取所述医疗症状字/词库中每一个字/词在词嵌入空间的表示,并计算所述词嵌入空间中字/词之间的交互分值;步骤s40,将待识别非结构化医疗文本划分为短句,并提取所述短句在所述医疗症状字/词库中出现过的字/词,获得待识别字/词集合;步骤s50,通过所述位置识别模型对所述待识别字/词集合中每一个字/词进行标注,获得待识别标注字/词序列;步骤s60,基于所述待识别标注字/词序列、词嵌入空间中字/词之间的交互分值,获取待识别非结构化医疗文本的症状实体。为了更清晰地对本发明非结构化医疗文本无监督症状自动识别方法进行说明,下面结合图1对本发明方法实施例中各步骤展开详述。本发明一种实施例的非结构化医疗文本无监督症状自动识别方法,包括步骤s10-步骤s60,各步骤详细描述如下:步骤s10,获取互联网医疗平台医疗症状语料,并通过预设的规则进行语料数据清洗,获得医疗症状实体库。本发明一个实施例中,选择的互联网站为春雨医生、名医在线、微医和39健康网,基于这些网站,分析网页结构,收集网页中只包含症状实体信息的词条,而不是症状描述语句。例如:‘月经、排卵、胎动、无胎动、肚子疼、白带异常、21-羟化酶缺陷症’,而不是‘有时候,身体的某些症状并非一定就是某种疾病导致的,身体在亚健康状态,疲劳状态,运动过度,饮食影响,疾病康复阶段等,也会出现一些类似疾病的症状,需要加以辨别。’之类的病情描述信息。对收集到的医疗症状数据使用预设的规则进行清洗,构成医疗症状实体库。例如:‘全身发热!<http://qiye.tianya.cn//blog/inforea>发热门诊’,将其处理为:‘全身发热’。按照上述的数据处理方法,将所有的医疗症状数据全部整理为只包含症状实体的序列,获得医疗症状实体库。步骤s20,通过分词工具对所述医疗症状实体库中实体进行分词,并通过bies序列标注策略对分词后的医疗症状字/词库中每一个字/词进行标注,构建字/词在医疗症状实体库中的位置识别模型。如图2所示,为本发明非结构化医疗文本无监督症状自动识别方法一种实施例的位置识别模型构建流程示意图,其具体过程如下:通过分词工具对医疗症状实体库中实体进行分词,构成初步的医疗症状字/词库,例如症状实体“鼻端弥漫性潮红”被分为“鼻端弥漫性潮红”。步骤s21,将所述医疗症状实体库中分词后未拆分的实体作为单个症状实体词,并标注为s;将所述医疗症状实体库中被拆分为多个字/词的实体的首位字/词标注为b,末尾字/词标注为e,中间字/词标注为i。对于词条来说,一般会分为两种:一种是不可分原子词,不可分原子词经过分词器之后不会被分开,例如:‘感冒’,‘发热’等等;另一种是组合词,组合词本身由多个原子词组合在一起构成整个词条的,这样的词条经过分词器之后,会被分词器分割成多个原子词。经过普通分词器分词之后没有被分开的原子词,作为单个症状实体,将其标注为‘s’。例如,‘发热’这种没有被分词的原子词,其标注为‘s’。经过普通分词器分词之后被分成多个字/词的实体,使用‘b’标注首位字/词,用‘e’标注末尾字/词,用‘i’标注所有中间字/词(若只存在两个字/词,则只标注首位和末尾字/词)。例如:‘白色念珠菌感染’,将第一个词‘白色’标注为‘b’代表开始的位置,将最后一个词‘感染’标注为‘e’代表结束的位置,将所有中间出现的字/词全部标注为‘i’;如果只存在两个字/词,例如‘白带异常’,则将‘白带’标注为‘b’,将‘异常’标注为‘e’。标注符号可以进行替换,本发明仅此为例进行说明,在此不再一一详述其他标注符号。重复以上的步骤,将所有的症状字/词库中的字/词全部通过bies的自动标注策略进行标注。步骤s22,基于标注后的医疗症状字/词库,构建字/词在医疗症状实体库中的位置识别模型。根据症状字/词标注语料库中症状实体组成要素(字/词)的位置信息,建立字/词在症状实体中的位置识别模型,在本发明一个实施例中,采用双向lstm编码网络(包括前向lstm层、后向lstm层、级联层)对每个字/词的语义信息进行捕获,通过单词嵌入层将one-hot表示的单词转换为嵌入向量。因此,字/词序列如式(1)所示:w={w1,...wt,wt+1,...wn}式(1)其中,wt是字/词序列中第t个字/词的向量,n是字/词序列的长度。使用单向lstm结构作为解码层产生标注序列,最后的softmax层基于lstm解码层的输出计算标准化的字/词标注的概率,如式(2)所示:其中,是指第i个字/词序列中第t个字/词的lstm层的输出,nt是总共的标注数量。步骤s30,通过聚合的方法获取所述医疗症状字/词库中每一个字/词在词嵌入空间的表示,并计算所述词嵌入空间中字/词之间的交互分值。如图3所示,为本发明非结构化医疗文本无监督症状自动识别方法一种实施例的获取词嵌入空间中字/词之间交互分值的流程示意图,其具体过程如下:步骤s311,以所述医疗症状字/词库中字/词为节点,直接上下文关系为边,构建异质文本图。如图4所示,为本发明非结构化医疗文本无监督症状自动识别方法一种实施例的异质文本图,症状字/词序列:‘便秘伴剧烈疼痛’、‘剧烈咳嗽’、‘伴有失眠’,可根据直接上下文关系将它们构成异质文本图。步骤s312,通过聚合所述异质文本图中节点附近的一阶邻居节点获得每个字/词在词嵌入空间的表示。本发明一个实施例中,采用graphsage算法训练步骤s311得到的异质文本图,通过聚合每个节点附近的一阶邻居节点获得每个节点具有直接上下文关系的嵌入表示。步骤s321,通过聚类算法结合近邻算法获取所述词嵌入空间中相邻字/词的数量和簇占用率。步骤s3211,基于所述词嵌入空间,分别建立两两字/词之间的向量,获得向量集合,并通过聚类算法对所述向量集合进行聚类,获得每个字/词的聚类类别特征。建立字/词与字/词向量的索引,例如:{‘发热’:w1,‘感冒’:w2},w1和w2是分别对应于‘发热’和‘感冒’的词向量。步骤s3212,基于所述每个字/词的聚类类别特征、字/词和向量建立索引,获得三个特征的一一映射关系;对所述向量集合中任一向量,通过近邻算法获取其距离最近的k个向量,并获取k个向量对应每个聚类类别的离散概率分布。建立三个特征的一一映射关系,例如:[[‘发热’,w1,c1],[‘感冒’,w2,c2]],c1和c2是‘发热’和‘感冒’经过聚类算法之后获得的聚类类别特征。步骤s3213,基于所述三个特征的一一映射关系、k个向量对应每个聚类类别的离散概率分布,获得相邻字/词的数量和簇占用率。步骤s322,基于所述词嵌入空间中相邻字/词的数量和簇占用率,通过向量相似性度量法获取词嵌入空间中字/词之间的交互分值。步骤s3221,基于所述相邻字/词的数量和簇占用率构建离散概率分布矩阵,并分别计算词嵌入空间中两两字/词之间的距离。例如,构建如表1所示的离散概率分布矩阵:表1词汇c1c2......cn发热p1=m1/kp2=m2/kpi=mi/kpn=mn/k其中,c*代表聚类之后的类别;p*是对应于‘发热’最近的k个词中,对于每个聚类类别分别有多少个词向量的离散概率分布,m是指在距离这个词最近的k个词中有m个是属于第c类的。本发明一个实施例中,采用kl散度计算每个词对中两个字/词的kl距离,如式(3)所示:其中,p和q分别指两个字/词的离散概率分布矩阵。步骤s3222,基于所述词嵌入空间中两两字/词之间的距离,通过预设的得分函数计算词嵌入空间中字/词之间的交互分值。通过得到的kl距离计算js散度,如式(4)、式(5)所示:根据嵌入空间中的距离结合打分函数计算出两个字/词之间的交互分值,如式(6)所示:s=exp(-αjsd+β)式(6)其中,α和β是权重和惩罚因子。如图5所示,为本发明非结构化医疗文本无监督症状自动识别方法一种实施例的获取待识别非结构化医疗文本症状实体的流程示意图,其具体过程如下:步骤s40,将待识别非结构化医疗文本划分为短句,并提取所述短句在所述医疗症状字/词库中出现过的字/词,获得待识别字/词集合。对待识别非结构化文本使用标点符号进行分句,根据每一句中的标点符号构成匹配模板,通过每一句的标点符号把待识别非结构化医疗文本分成多个短句,后续所有的操作全部都按照短句为一个单位。例如:‘请问医生,最近一个月来,耳朵一开始有感染之后还好但耳鸣越发痒痛检查不出病因怎么办?’。将其处理为:‘请问医生’,‘最近一个月来’,‘耳朵一开始有感染之后还好但化验有耳鸣越发痒痛检查不出病因怎么办’。将得到的医学症状字/词库加入到分词器的用户词典中,对待识别非结构化文本进行分词,例如:‘请问医生’,‘最近一个月来’,‘耳朵一开始有感染之后还好但耳鸣越发痒痛检查不出病因怎么办’。提取短句在医疗症状字/词库中出现过的字/词,获得待识别字/词集合,例如:‘耳朵开始感染好耳鸣痒痛检查病因’。步骤s50,通过所述位置识别模型对所述待识别字/词集合中每一个字/词进行标注,获得待识别标注字/词序列。步骤s60,基于所述待识别标注字/词序列、词嵌入空间中字/词之间的交互分值,获取待识别非结构化医疗文本的症状实体。步骤s61,提取所述待识别标注字/词序列标注为s的字/词,获得单个症状实体、剩余带标注字/词序列。经过位置识别模型的标注后,检测字/词序列中是否存在‘s’标注的字/词,如果存在,就直接将其作为单个症状实体抽取出来,将剩余字/词序列留作接下来检测bie的语料;如果不存在,则到下一步骤继续处理。例如,标注后序列为‘耳朵开始感染好耳鸣痒痛检查病因biiiseib’。将标注为‘s’的‘耳鸣’抽取出来,将剩余序列‘耳朵开始感染好痒痛检查病因biiieib’留作接下来检测bie的语料进行下一步的处理。步骤s62,判断所述剩余带标注字/词序列长度是否大于1,是则使用正向匹配和反向回溯算法遍历所述剩余带标注字/词序列,获取连续的b-i-e序列、b-e序列。首先,检测每条经过位置识别模型标注的字/词序列,如果同时存在b、e的标注,就将其保留做下一步的操作;如果没有同时存在,则结束抽取过程。例如,剩余序列‘耳朵开始感染好痒痛检查病因biiieib’,其中同时存在‘b’和‘e’标注的字/词,所以进行下一步的操作。其次,将得到的字/词序列从第一个字/词开始正向扫描,如果找到‘e’标注的位置,就记录下来,然后继续正向扫描,查找紧接着这个‘e’标注的词后面是否存在连续出现的‘e’标注的词语,如果存在,就继续扫描直到最后一个连续出现的‘e’标注的词语的位置;如果不存在,那么就停止扫描,结束抽取。例如,对上述得到的字/词序列‘耳朵开始感染好痒痛检查病因biiieib’,经过正向遍历后得到的最后一个‘e’标注的位置为5。再其次,根据正向遍历的序列,从正向遍历第一个‘e’标注的位置开始,开始进行反向回溯,这里有两种情况:(1)如果回溯到第一个字/词时仍没有检测到标注‘b’标注的字/词,那么就舍弃这个序列,结束抽取;(2)如果检测到第一个‘b’标签标注的字/词,就把这个位置记录下来,继续回溯,检测是否存在连续出现的使用标签‘b’标注的词语,如果存在,就继续回溯,将反向回溯最后一个出现的‘b’标签标注的字/词的位置记录下来;如果不存在,就结束回溯。例如,对于上述得到的字/词序列‘耳朵开始感染好痒痛检查病因biiieib’结合正向遍历得到的最后一个‘e’的位置5进行反向回溯,得到最后一个‘b’标注的位置是1。最后,把反向回溯的最后一个‘b’标注的词的位置开始到正向遍历的最后一个‘e’标注的位置的这部分字/词序列截取出来,作为最后一步症状实体识别的字/词序列。在经过上述步骤之后,给定的非结构化医疗文本被处理为b-i-e或b-e的形式,例如:‘耳朵开始感染好痒痛biiie’。步骤s63,组合所述b-e序列,获得be组合症状实体;分别获取每个b-i-e序列中间字/词和首位字/词、末尾字/词的交互分值并计算均值,所述均值大于设定阈值的中间字/词与首位字/词、末尾字/词组合,获得bie组合症状实体。对于连续出现的b-i-e序列,将每个‘i’标注的字/词分别和距离其最近的‘b’标注的字/词组成b-i词对,和距离其最近的‘e’标注的字/词组成i-e词对,并计算它们之间的交互分值。例如:对于‘耳朵开始感染好痒痛biiie’,有b-i词对:(耳朵,开始,0.32),(耳朵,感染,0.56),(耳朵,好,0.12);有i-e词对:(开始,痒痛,0.24),(感染,痒痛,0.63),(好,痒痛,0.13)。对于每个‘i’标注的字/词构成的两个词对b-i和i-e,计算其交互分值的均值,如式(7)所示:其中,simb代表b-i词对的交互分值,sime代表i-e词对的交互分值。本发明一个实施例中,设定阈值为0.5,sim大于此阈值就将‘i’标注的字/词和首尾字/词组合,小于阈值的就舍弃。例如,上述的词对中,交互分值大于0.5的有(耳朵,感染,0.56)和(感染,痒痛,0.63)两个词对,因此,将‘感染’和‘耳朵’、‘痒痛’组合构成‘耳朵感染痒痛’的bie症状实体。步骤s64,所述单个症状实体、be组合症状实体、bie组合症状实体为待识别非结构化医疗文本的症状实体。对每一个字/词序列进行上述的操作,最终获得的单个症状实体、be组合症状实体、bie组合症状实体为待识别非结构化医疗文本的症状实体。本发明第二实施例的非结构化医疗文本无监督症状自动识别系统,该症状自动识别系统包括输入模块、医疗症状实体库、医疗症状字/词库、位置识别模块、交互分值获取模块、症状实体提取模块、输出模块;所述输入模块,配置为将待识别非结构化医疗文本划分为短句,并提取所述短句在所述医疗症状字/词库中出现过的字/词,获得待识别字/词集合并输入;所述医疗症状实体库,配置为获取互联网医疗平台医疗症状语料,并通过预设的规则进行语料数据清洗,获得医疗症状实体库;所述医疗症状字/词库,配置为通过分词工具对所述医疗症状实体库中实体进行分词,获得医疗症状字/词库;所述位置识别模型,配置为通过bies序列标注策略对医疗症状字/词库中每一个字/词进行标注后构建位置识别模型,并通过所述位置识别模型对所述待识别字/词集合中每一个字/词进行标注,获得待识别标注字/词序列;所述交互分值获取模块,配置为通过聚合的方法获取所述医疗症状字/词库中每一个字/词在词嵌入空间的表示,并计算所述词嵌入空间中字/词之间的交互分值;所述症状实体获取模块,配置为基于待识别标注字/词序列、词嵌入空间中字/词之间的交互分值,获取单个症状实体、be组合症状实体、bie组合症状实体;所述输出模块,配置为输出获取的单个症状实体、be组合症状实体、bie组合症状实体作为待识别非结构化医疗文本的症状实体。所属
技术领域:
的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统的具体工作过程及有关说明,可以参考前述方法实施例中的对应过程,在此不再赘述。需要说明的是,上述实施例提供的非结构化医疗文本无监督症状自动识别系统,仅以上述各功能模块的划分进行举例说明,在实际应用中,可以根据需要而将上述功能分配由不同的功能模块来完成,即将本发明实施例中的模块或者步骤再分解或者组合,例如,上述实施例的模块可以合并为一个模块,也可以进一步拆分成多个子模块,以完成以上描述的全部或者部分功能。对于本发明实施例中涉及的模块、步骤的名称,仅仅是为了区分各个模块或者步骤,不视为对本发明的不当限定。本发明第三实施例的一种存储装置,其中存储有多条程序,所述程序适于由处理器加载并执行以实现上述的非结构化医疗文本无监督症状自动识别方法。本发明第四实施例的一种处理装置,包括处理器、存储装置;处理器,适于执行各条程序;存储装置,适于存储多条程序;所述程序适于由处理器加载并执行以实现上述的非结构化医疗文本无监督症状自动识别方法。所属
技术领域:
的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的存储装置、处理装置的具体工作过程及有关说明,可以参考前述方法实施例中的对应过程,在此不再赘述。本领域技术人员应该能够意识到,结合本文中所公开的实施例描述的各示例的模块、方法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,软件模块、方法步骤对应的程序可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd-rom、或
技术领域:
内所公知的任意其它形式的存储介质中。为了清楚地说明电子硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以电子硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。本领域技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。术语“第一”、“第二”等是用于区别类似的对象,而不是用于描述或表示特定的顺序或先后次序。术语“包括”或者任何其它类似用语旨在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备/装置不仅包括那些要素,而且还包括没有明确列出的其它要素,或者还包括这些过程、方法、物品或者设备/装置所固有的要素。至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征作出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1