文件系统元数据的扫描方法和系统与流程
本发明涉及计算机领域,特别涉及一种文件系统元数据的扫描方法和系统。
背景技术:
随着硬件技术的进步,应用冷冻电镜技术解析生物大分子的结构正在成为一个崭新的结构生物学研究方向。近年来,不少研究团队基于冷冻电镜技术在国际顶级学术期刊nature、science、cell等发表了数十篇高分辨率的关于蛋白质三维结构解析的成果,对生命科学的发展产生了重大影响,而冷冻电镜在这其中发挥着举足轻重的作用。
为了重构出高精度的分子结构,冷冻电镜需要拍摄大量二维的高分辨率图像,由于冷冻电镜在拍摄过程中很难避免诸如欠焦等问题,从而会导致丢失一些图像信息,为了避免有效信息的丢失,冷冻电镜通常会在不同的欠焦水平和不同的角度下拍摄大量高分辨率的二维图像加以合成,以弥补单一图像丢失的信息,最终利用所拍摄的大量的高分辨率的二维图像,通过相关的三维重构软件如relion等重构出高分辨率的分子结构。
然而,在重构三维分子结构的过程中,为了构建精确的高分辨率的三维分子结构,冷冻电镜需要从不同的角度拍摄大量的高分辨率的二维图像,细微的角度变化均需要拍摄大量的二维图像,在电镜满负荷工作的情况下,每天会产生数几十tb的电镜数据,以清华大学生命学院电镜平台titan为例,每台titan的拍摄速率7gb/分钟,即每分钟产生7gb左右的图像数据,这样一台电镜在一天中就能产生7gb/分钟*60分钟/小时*24小时=10.08tb的数据,从而导致每年将消耗高达4pb的存储容量。而这仅仅是一台电镜设备一年所采集的电镜数据,国内众多科研机构通常都维护着若干台的电镜设备,如清华大学目前就维护着至少3台电镜设备,每年产生的电镜数据在8pb以上,面对如此海量的电镜数据,如何设计合理的目录结构,以便于用户能够简洁方便的管理自己采集的电镜数据,就显的尤为重要。
目前,比较推崇的一种电镜数据目录组织原则是以一种二元组的方式来对用户采集的电镜数据进行目录组织,该二元组为(电镜设备id,采集实践_用户名),与该二元组对应的目录结构组织方式如图1所示,在图1中,最顶层目录“/shareem”通常是底层存储系统,如gpfs、lustre等文件系统的目录挂载点,在该挂载点下,设置若干个子目录,对应某台电镜所产生的数据,例如,对于/shareem下的子目录titand3172,其下存放的是名称为titand3172的电镜所产生的所有电镜数据,而目录/shareem/titand3172/20140613_zhangyanqing存放的是用户zhangyanqing在2014年6月13日使用电镜titand3172采集的电镜数据。
为了能够及时获取电镜存储系统的消耗情况,系统管理员通常需要在固定的时间周期,如每小时,每天,每周等,对存储系统中每个用户的存储空间使用情况进行统计分析,以便于系统管理员能够及时发现异常情况,如某天的存储消耗量过大或者过小,某个用户占用了过多的存储空间,总存储空间低于阈值等,系统管理员一旦发现存储系统中出现异常情况时,会采取相应的处理措施,以保证电镜存储系统能够稳定高效的运行。
传统的获取电镜存储系统消耗情况的方法通过操作系统自带的命令工具,如linux系统自带的df命令来获取存取系统当前存储空间的使用量和剩余量,但是无法获取每个用户的具体消耗量。若想或者用户每天的消耗量,则需要组合使用其它的命令行工具,如linux的find命令和stat命令,对整个存储系统的所有文件进行扫描后才能够得到每个用户的具体使用情况,而这会引发另一个问题:当存储系统中的文件数量非常巨大时,例如在千万级别,则需要耗时相当长的时间才能够获取最终的每个用户的统计数据。以清华大学大学生物计算平台管理的一个电镜存储系统shareem为例,其总容量为2.5p,其中包含了约2400万个与电镜相关的数据文件,shareem总共由4个io节点构成,通过iozone的测试发现,该存储系统的iops(input/outputoperationspersecond)约为4000次/秒,即每秒中能够够在shareem上进行约4000次的io操作,但这是4个io节点聚合吞吐量,平均每个io节点的iops为1000次/秒,因此,若对shareem上的2400万个电镜数据进行一次用户空间使用统计,由于find操作和stat操作存在严格的先后顺序,即必须通过find操作找出所有的文件路径后,才能对每个文件进行stat操作获取文件的元数据信息,因此,1个文件的分析需要进行2次的io操作,2400万个文件,总共需要进行4800万次io操作,而完成4800万次io操作,以每秒进行1000次io操作的速度进行扫描,总共耗时48000秒,即总共耗时约13个小时左右。
事实上,由于find命令和stat命令是单进程执行的,加上运行find命令和stat命令所在的主机上其它进程对于shareem操作的影响,在扫描
shareem时,通常很难以1000次/秒的iops速度进行扫描,实际的测试发现,使用find命令和stat命令进行shareem扫描时,iops只能达到400次/秒左右,一次的shareem扫描,需要耗时30个小时以上,而系统管理员通常无法接受30个小时的扫描时间,原因在于当发现异常情况时,往往已经错过了最佳的补救时间,因此,如何实现对电镜数据文件元数据的快速扫描,对于电镜数据的管理的尤为重要。
技术实现要素:
本发明提供了一种文件系统元数据的扫描方法和系统,可以实现对文件系统元数据的快速扫描,节省处理时间。
本发明提供一种文件系统元数据的扫描方法,包括:
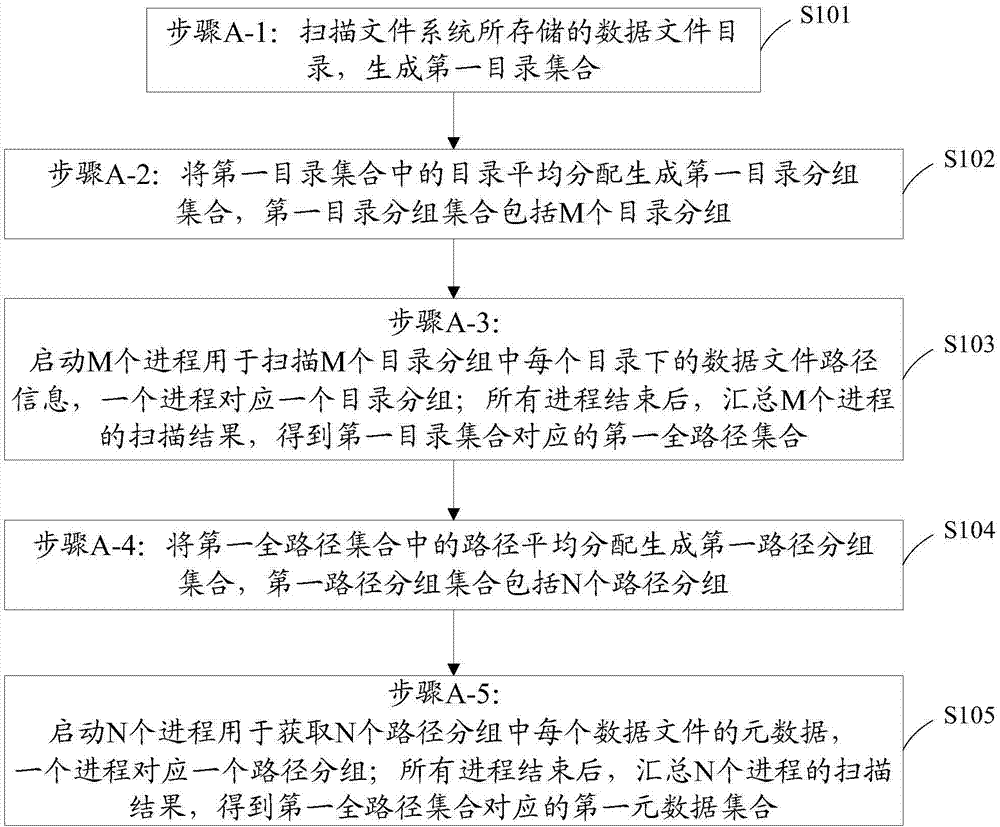
步骤a-1:扫描文件系统所存储的数据文件目录,生成第一目录集合;
步骤a-2:将第一目录集合中的目录平均分配生成第一目录分组集合,第一目录分组集合包括m个目录分组;
步骤a-3:启动m个进程用于扫描m个目录分组中每个目录下的数据文件路径信息,一个进程对应一个目录分组;所有进程结束后,汇总m个进程的扫描结果,得到第一目录集合对应的第一全路径集合;
步骤a-4:将第一全路径集合中的路径平均分配生成第一路径分组集合,第一路径分组集合包括n个路径分组;
步骤a-5:启动n个进程用于获取n个路径分组中每个数据文件的元数据,一个进程对应一个路径分组;所有进程结束后,汇总n个进程的扫描结果,得到第一全路径集合对应的第一元数据集合。
本发明还提供一种文件系统元数据的扫描系统,包括
目录扫描模块:扫描文件系统所存储的数据文件目录,生成第一目录集合;
目录分组模块:将第一目录集合中的目录平均分配生成第一目录分组集合,第一目录分组集合包括n个目录分组;
路径扫描模块:启动n个进程用于扫描n个目录分组中每个目录下的数据文件路径信息,一个进程对应一个目录分组;所有进程结束后,汇总n个进程的扫描结果,得到第一目录集合对应的第一全路径集合;
路径分组模块:将第一全路径集合中的路径平均分配生成第一路径分组集合,第一路径分组集合包括n个路径分组;
元数据扫描模块:启动n个进程用于获取n个路径分组中每个数据文件的元数据,一个进程对应一个路径分组;所有进程结束后,汇总n个进程的扫描结果,得到第一全路径集合对应的第一元数据集合。
本发明提供的文件系统元数据的扫描方法和系统,将扫描普通的单进程扫描更改为分步多进程扫描,提高了整体处理效率,节省了收集文件系统元数据的所需时间,符合文件系统的监控和管理要求。
附图说明
图1为本发明电镜数据存储的二元组文件名称对应的目录结构示意图;
图2为本发明文件系统元数据的扫描方法第一实施例;
图3为本发明文件系统元数据的扫描方法第二实施例;
图4为本发明文件系统元数据的扫描系统第一实施例;
图5为本发明文件系统元数据的扫描系统第二实施例。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用来区别类似的对象,而不必用于描述特定的顺序和先后次序。应该理解,这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。
文件系统是系统软件,存储系统的硬件设备通过文件系统进行管理。需要指出的是,本申请的文件系统包括并行文件系统和非并行文件系统。
如图1所示,本发明的文件系统元数据的扫描方法,包括:
步骤a-1(s101):扫描文件系统所存储的数据文件目录,生成第一目录集合;
步骤a-2(s102):将第一目录集合中的目录平均分配生成第一目录分组集合,第一目录分组集合包括m个目录分组;
步骤a-3(s103):启动m个进程用于扫描m个目录分组中每个目录下的数据文件路径信息,一个进程对应一个目录分组;所有进程结束后,汇总m个进程的扫描结果,得到第一目录集合对应的第一全路径集合;
步骤a-4(s104):将第一全路径集合中的路径平均分配生成第一路径分组集合,第一路径分组集合包括n个路径分组;
步骤a-5(s104):启动n个进程用于获取n个路径分组中每个数据文件的元数据,一个进程对应一个路径分组;所有进程结束后,汇总n个进程的扫描结果,得到第一全路径集合对应的第一元数据集合。
在步骤a-1和步骤a-3中,通过操作系统命令,如linux系统的find命令获取数据文件的目录和路径信息,也可以通过主流编程语言,如python、java等的api接口获取数据文件的目录和路径信息。
在步骤a-5中,通过操作系统命令,如linux系统的stat命令获取数据文件的元数据信息,也可以通过主流编程语言,如python、java等的api接口获取数据文件的元数据信息。
本发明提供的文件系统元数据的扫描方法,将扫描普通的单进程扫描更改为分步多进程扫描,如图1所示,包括目录扫描、路径扫描和元数据扫描,其中路径扫描和元数据扫描采用多进程并行扫描,如此提高了整体处理效率,节省了收集文件系统元数据的所需时间,符合文件系统的监控和管理要求。
其中,并行扫描的进程总数m、n取值,优先设置与文件系统剩余iops和进程平均iops相关。
可以令m(n)=取整(当前文件系统剩余iops/进程平均iops)。
假设:当前文件系统剩余的iops为8000次/秒,单进程执行步骤a-3能达到400次/秒,那么根据公式可知,m取20。
假设:当前文件系统剩余的iops为8000次/秒,单进程执行步骤a-5能达到200次/秒,那么根据公式可知,n取40。
如此,可利用文件系统高iops特性,实现对目录和路径的快速扫描,平均分配目录分组和路径分组,可以使每个进程的运行时间均衡,进一步节省扫描时间。
图1中的元数据至少包含数据文件的最近修改时间信息、最近访问时间信息、最近更改时间信息、数据文件全路径信息、数据文件所属用户、数据文件所属用户组、和/或数据文件大小。
举例说明:元数据格式可以为:
m#a#c#f#u#g#s
其中,m表示最近修改时间,a表示最近访问时间,c表示最近改变时间,f:表示文件全路径信息,u表示文件所属用户,g表示文件所属用户组,s表示文件大小。#表示第一分隔符,第一分隔符也可以是其他分隔符,每两个元数据信息之间的分隔符与第一分隔符不同,例如当第一分隔符为“#”时,元数据信息之间的分隔符可以为“,”。
基于以上元数据信息,进一步地,图1在步骤a-5之后,还可以包括:
步骤a-6:对第一元数据集合中的元数据信息进行统计分析,得到每个用户占用的存储空间或存储空间占比、每个用户组占用的存储空间或存储空间占比、总存储空间的使用占比、和/或每个文件夹占用的存储空间或存储空间占比。或者其他基于元数据的监控和管理。
在很多时候,数据的目录结构如图1所示,以二元组的方式来组织,则数据文件都存储在三级目录下,基于该目录结构,将图1的方法扩展如图2所示:
步骤b-1(s201):扫描文件系统中指定目录深度的数据文件目录,生成第一目录集合;
步骤a-2(s202):将第一目录集合中的目录平均分配生成第一目录分组集合,第一目录分组集合包括m个目录分组;
步骤a-3(s203):启动m个进程用于扫描m个目录分组中每个目录下的数据文件路径信息,一个进程对应一个目录分组;所有进程结束后,汇总m个进程的扫描结果,得到第一目录集合对应的第一全路径集合;
步骤b-4(s204):启动单进程扫描文件系统中所有指定目录深度之外的数据文件路径信息,生成第二全路径集合;
步骤b-5(s205):将第二全路径集合并入第一全路径集合;
步骤a-4(s206):将第一全路径集合中的路径平均分配生成第一路径分组集合,第一路径分组集合包括n个路径分组;
步骤a-5(s207):启动n个进程用于获取n个路径分组中每个数据文件的元数据,一个进程对应一个路径分组;所有进程结束后,汇总n个进程的扫描结果,得到第一全路径集合对应的第一元数据集合。
在图2的方法中,如果文件系统严格执行规则目录存储,那么步骤b-4和步骤b-5与可以省去。由于步骤b-1与步骤a-1,相比,只扫描指定深度的目录,节省了扫描其他深度目录的时间,于图1相比,可以进一步节省处理时间。
如图4所示,本发明还包括一种文件系统元数据的扫描系统,包括:
目录扫描模块:扫描文件系统所存储的数据文件目录,生成第一目录集合;
目录分组模块:将第一目录集合中的目录平均分配生成第一目录分组集合,第一目录分组集合包括m个目录分组;
路径扫描模块:启动m个进程用于扫描m个目录分组中每个目录下的数据文件路径信息,一个进程对应一个目录分组;所有进程结束后,汇总m个进程的扫描结果,得到第一目录集合对应的第一全路径集合;
路径分组模块:将第一全路径集合中的路径平均分配生成第一路径分组集合,第一路径分组集合包括n个路径分组;
元数据扫描模块:启动n个进程用于获取n个路径分组中每个数据文件的元数据,一个进程对应一个路径分组;所有进程结束后,汇总n个进程的扫描结果,得到第一全路径集合对应的第一元数据集合。
在图4,m、n取值,优先设置与文件系统剩余iops和进程平均iops相关。
图4中的元数据至少包含数据文件的最近修改时间信息、最近访问时间信息、最近更改时间信息、数据文件全路径信息、数据文件所属用户、数据文件所属用户组、和/或数据文件大小。
基于元数据信息,图4的系统在元数据扫描模块之后还可以包括:
统计分析模块:对第一元数据集合中的元数据信息进行统计分析,得到每个用户占用的存储空间或存储空间占比、每个用户组占用的存储空间或存储空间占比、总存储空间的使用占比、和/或每个文件夹占用的存储空间或存储空间占比。
如图5所示,本发明还包括一种文件系统元数据的扫描系统,包括:
主要目录扫描模块:扫描文件系统中指定目录深度的数据文件目录,汇总扫描结果得到第一目录集合;
主要目录分组模块:将第一目录集合中的目录平均分配生成第一目录分组集合,第一目录分组集合包括m个目录分组;
主要路径扫描模块:启动m个进程用于扫描m个目录分组中每个目录下的数据文件路径信息,一个进程对应一个目录分组;所有进程结束后,汇总m个进程的扫描结果,得到第一目录集合对应的第一全路径集合;
次要路径扫描模块:启动单进程扫描文件系统中所有指定目录深度之外的数据文件路径信息,生成第二全路径集合;
路径汇总模块:将第二全路径集合并入第一全路径集合。
路径分组模块:将第一全路径集合中的路径平均分配生成第一路径分组集合,第一路径分组集合包括n个路径分组;
元数据扫描模块:启动n个进程用于获取n个路径分组中每个数据文件的元数据,一个进程对应一个路径分组;所有进程结束后,汇总n个进程的扫描结果,得到第一全路径集合对应的第一元数据集合。
需要说明的是,本发明的文件系统元数据的扫描系统的实施例,与文件系统元数据的扫描方法的实施例原理相同,相关之处可以互相参照。
此外,本申请的方法和系统的应用对象不仅限于电镜数据的文件系统,对于其他海量数据存储管理领域一样适用,如气象数据的文件系统,卫星数据的文件系统,地震数据的文件系统等。
以上所述仅为本发明的较佳实施例而已,并不用以限定本发明的包含范围,凡在本发明技术方案的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!