一种脑电信号的压缩方法及装置与流程
本发明涉及数据压缩处理技术,尤其涉及一种脑电信号的压缩方法及装置。
背景技术:
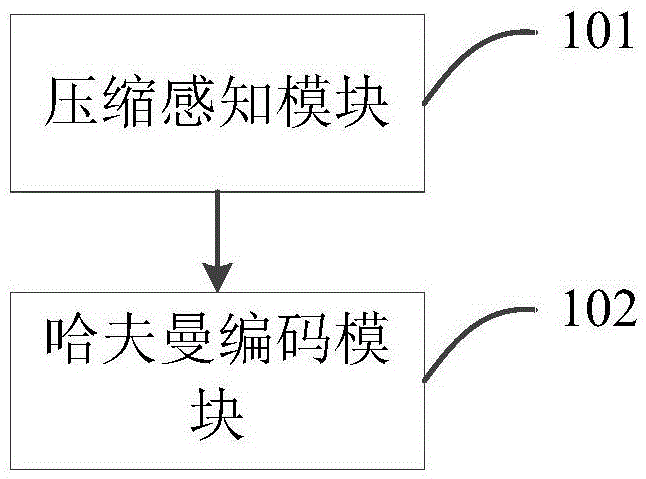
:技术词解释:huffman编码:哈夫曼编码。随着微电子和生物医学技术的不断发展,对目标对象进行生理信号的监测(例如目标对象的脑电eeg信号的监测)逐渐成为了常态。对于所述脑电信号,其是脑神经细胞的电生理活动在大脑皮层或头皮表面的总体反应,包含了大量的生理和疾病信息;通常,其需要长时间地进行测量和数据采集,才能从采集到的数据中提取到相关有用的信息,以利于后续的疾病分析。而为了能够对目标对象进行长时间的脑电信号测量,则需要患者长时间地携带相应的测量设备,而这则对测量设备的便携性提出了要求。然而,由于脑电信号的长时间测量和记录,其会产生大量的数据,这样则会导致目前的测量设备需要设计足够容量的存储空间才能对大量数据进行全部存储,而这则会导致随身携带的测量设备的体积和重量较大,降低其携带便利性,因此,设计一种对脑电数据进行压缩的方案是目前迫切需要解决的问题。技术实现要素:为了解决上述技术问题,本发明的目的是提供一种脑电信号的压缩方法及装置,以减少脑电信号数据的存储空间。一方面,本发明实施例所采用的技术方案是:一种脑电信号的压缩方法,包括以下步骤:将输入的脑电数据与第一矩阵相乘后得到第二矩阵,其中,所述脑电数据为n*1矩阵,所述第一矩阵为m*n矩阵,所述第二矩阵为m*1矩阵,n大于m;对第二矩阵中所包含的数据进行哈夫曼编码后得到压缩数据。进一步,所述第一矩阵为稀疏矩阵;所述将输入的脑电数据与第一矩阵相乘后得到第二矩阵这一步骤,其具体为:通过m个并行的判断累加单元对输入的脑电数据进行判断累加处理后得到第二矩阵,其中,所述判断累加单元用于若第一矩阵第i行中第j个元素为1时,则将脑电数据中第j个数据与前一个总和进行相加后得到当前的总和,若第一矩阵第i行中第j个元素为0时,则将前一个总和作为当前的总和。进一步,所述对第二矩阵中所包含的数据进行哈夫曼编码后得到压缩数据这一步骤,其包括:通过统计排序单元从而采用边输入边统计排序的方式来对第二矩阵中的字符进行个数统计,并且按照字符的个数来对字符进行排序;通过编码单元来根据第二矩阵中的字符所对应的特征值以及字符的个数,对排序后的字符进行哈夫曼编码后,通过数据输出单元将编码后得到的数据输出。进一步,所述编码单元采用两级流水线来实现,其中,所述两级流水线中的一级流水线用于执行哈夫曼编码中的求和处理操作,所述两级流水线中的另一级流水线用于执行哈夫曼编码中的排序处理操作。进一步,所述数据输出单元具体用于先输出字符编码表,然后再输出编码后得到的数据。另一方面,本发明实施例所采用的技术方案是:一种脑电信号的压缩装置,包括:压缩感知模块,用于将输入的脑电数据与第一矩阵相乘后得到第二矩阵,其中,所述脑电数据为n*1矩阵,所述第一矩阵为m*n矩阵,所述第二矩阵为m*1矩阵,n大于m;哈夫曼编码模块,用于对第二矩阵中所包含的数据进行哈夫曼编码后得到压缩数据。进一步,所述第一矩阵为稀疏矩阵;所述压缩感知模块包括m个判断累加单元,所述压缩感知模块具体用于通过m个并行的判断累加单元对输入的脑电数据进行判断累加处理后得到第二矩阵,其中,所述判断累加单元用于若第一矩阵第i行中第j个元素为1时,则将脑电数据中第j个数据与前一个总和进行相加后得到当前的总和,若第一矩阵第i行中第j个元素为0时,则将前一个总和作为当前的总和。进一步,所述哈夫曼编码模块包括:统计排序单元,用于采用边输入边统计排序的方式来对第二矩阵中的字符进行个数统计,并且按照字符的个数来对字符进行排序;编码单元,用于根据第二矩阵中的字符所对应的特征值以及字符的个数,对排序后的字符进行哈夫曼编码;数据输出单元,用于将编码后得到的数据输出。进一步,所述编码单元采用两级流水线来实现,其中,所述两级流水线中的一级流水线用于执行哈夫曼编码中的求和处理操作,所述两级流水线中的另一级流水线用于执行哈夫曼编码中的排序处理操作。进一步,所述数据输出单元具体用于先输出字符编码表,然后再输出编码后得到的数据。本发明实施例所具有的有益结果:上述本发明实施例先通过矩阵乘法操作,从而对脑电数据进行基于压缩感知的一级压缩,然后再对一级压缩后的数据进行哈夫曼编码,这样能够减少脑电信号的数据量,从而降低传输功耗和存储消耗。此外进一步,由于压缩感知模块采用稀疏矩阵作为压缩矩阵(即所述第一矩阵),并且利用m个并行的判断累加单元便能实现,这样能够大大降低压缩感知模块的电路设计复杂度,减少计算功耗;再者,由于哈夫曼编码模块中的符号统计单元采用边输入边统计排序的方式,来对一级压缩后的数据进行统计排序,且编码单元采用两级流水线的设计来实现,这样可大大降低编码周期,从而降低数据压缩时延。附图说明图1是本发明实施例一种脑电信号的压缩装置的结构框图;图2是本发明实施例一种脑电信号的压缩方法的步骤流程图;图3是本发明实施例中压缩感知模块的一具体实施例结构示意图;图4是本发明实施例中统计排序单元的原理示意图;图5是本发明实施例中编码单元的原理示意图;图6是本发明实施例中两级流水设计与没有两级流水设计的编码周期对比图;图7是本发明实施例中哈夫曼编码的第一具体实施例编码示意图;图8是本发明实施例中哈夫曼编码的第二具体实施例编码示意图;图9是本发明实施例中哈夫曼编码的第三具体实施例编码示意图。具体实施方式下面结合附图和具体实施例对本发明做进一步的详细说明。对于以下实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定,实施例中的各步骤的执行顺序均可根据本领域技术人员的理解来进行适应性调整。为了减少脑电信号数据的存储空间,即减少脑电信号的数据量,本发明实施例提供了一种脑电信号的压缩装置,如图1所示,其包括有:压缩感知模块101,用于将输入的脑电数据与第一矩阵相乘后得到第二矩阵,其中,所述脑电数据为n*1矩阵,所述第一矩阵为m*n矩阵,所述第二矩阵为m*1矩阵,n大于m;哈夫曼编码模块102,用于对第二矩阵中所包含的数据进行哈夫曼编码后得到压缩数据。优选地,所述第一矩阵为稀疏矩阵;所述压缩感知模块101包括m个判断累加单元,所述压缩感知模块101具体用于通过m个并行的判断累加单元对输入的脑电数据进行判断累加处理后得到第二矩阵,其中,所述判断累加单元用于若第一矩阵第i行中第j个元素为1时,则将脑电数据中第j个数据与前一个总和进行相加后得到当前的总和,若第一矩阵第i行中第j个元素为0时,则将前一个总和作为当前的总和。优选地,所述哈夫曼编码模块102包括:统计排序单元,用于采用边输入边统计排序的方式来对第二矩阵中的字符进行个数统计,并且按照字符的个数来对字符进行排序;编码单元,用于根据第二矩阵中的字符所对应的特征值以及字符的个数,对排序后的字符进行哈夫曼编码;数据输出单元,用于将编码后得到的数据输出。优选地,所述编码单元采用两级流水线来实现,其中,所述两级流水线中的一级流水线用于执行哈夫曼编码中的求和处理操作,所述两级流水线中的另一级流水线用于执行哈夫曼编码中的排序处理操作;和/或,所述数据输出单元具体用于先输出字符编码表,然后再输出编码后得到的数据。基于上述的装置,本发明实施例还提供了一种脑电信号的压缩方法,如图2所示,其具体包括的步骤如下所示。步骤s201、压缩感知模块将输入的脑电数据与第一矩阵相乘后得到第二矩阵,其中,所述脑电数据为n*1矩阵x,所述第一矩阵为m*n矩阵a,所述第二矩阵为m*1矩阵y,n大于m。可见,所述第二矩阵y=a*x;其中,矩阵x的行数为n,列数为1;矩阵a的行数为m,列数为n;矩阵y的行数为m,列数为1。也就是说,脑电数据按顺序输入至所述压缩感知模块中,所述压缩感知模块将n个需要压缩的脑电数据进行压缩处理后,得到m个压缩数据,即压缩后的数据量为m。在本实施例中,所述第一矩阵优选采用稀疏矩阵来实现;所述将输入的脑电数据与第一矩阵相乘后得到第二矩阵这一步骤,其具体为:通过m个并行的判断累加单元对输入的脑电数据进行判断累加处理后得到第二矩阵,其中,所述判断累加单元用于若第一矩阵第i行中第j个元素为1时,则将脑电数据中第j个数据与前一个总和进行相加后得到当前的总和,若第一矩阵第i行中第j个元素为0时,则将前一个总和作为当前的总和。具体地,如图3所示,所述压缩感知模块优选采用m个并行的判断累加单元ja来实现,而对于第i个判断累加单元jai,其具体用于若第一矩阵a第i行中第j个元素为1时,则将脑电数据中第j个数据与前一个总和进行相加后得到当前的总和,若第一矩阵第i行中第j个元素为0时,则将前一个总和作为当前的总和。例如,对于第1个判断累加单元ja1,其具体用于在第j次的判断累加过程中,若第一矩阵a中第1行中第j个元素为1时,则将脑电数据中第j个数据与前一个总和(即第j-1个总和)进行相加后得到当前的总和,即得到第j个总和,若第一矩阵a中第1行中第j个元素为0时,则将前一个总和,即第j-1个总和作为当前的总和,即第j个总和,而在第j+1次的判断累加过程中,若第一矩阵a第1行中第j+1个元素为1时,则将脑电数据中第j+1个数据与前一个总和(即第j个总和)进行相加后得到当前的总和,即得到第j+1个总和,若第一矩阵a中第1行中第j+1个元素为0时,则将前一个总和,即第j个总和作为当前的总和,即第j+1个总和,这样如此类推,当执行完第n次的判断累加流程后,第1个判断累加单元所输出的数据即为y矩阵中的第1个压缩数据;同样地,对于第2个判断累加单元ja2,其具体用于在第j次的判断累加过程中,若第一矩阵a中第2行中第j个元素为1时,则将脑电数据中第j个数据与前一个总和(即第j-1个总和)进行相加后得到当前的总和,即得到第j个总和,若第一矩阵a中第2行中第j个元素为0时,则将前一个总和,即第j-1个总和作为当前的总和,即第j个总和,而在第j+1次的判断累加过程中,若第一矩阵a第2行中第j+1个元素为1时,则将脑电数据中第j+1个数据与前一个总和(即第j个总和)进行相加后得到当前的总和,即得到第j+1个总和,若第一矩阵a中第2行中第j+1个元素为0时,则将前一个总和,即第j个总和作为当前的总和,即第j+1个总和,这样如此类推,当执行完第n次的判断累加流程后,第2个判断累加单元所输出的数据即为y矩阵中的第2个压缩数据;如此类推,在m个并行的判断累加单元ja分别同时执行n次的判断累加流程后,便可输出压缩数据矩阵,即m*1矩阵y。由此可得,压缩感知模块通过包含的m个并行的判断累加单元ja,对输入的数据完成简单的判断累加,一个周期输入一个脑电数据,那么在n个周期后,即n个数据输入完成后,便得到压缩后的m个压缩后数据,其中,ja的判断累加条件则由预置的稀疏随机二值矩阵(即矩阵a,由于矩阵a为稀疏矩阵,因此其矩阵中的元素仅包含0和1)中的元素来确定,元素为0时则不累加,元素为1时则累加,这样通过所述压缩感知模块来实现一级压缩,能够在大大减少数据量的基础上,降低电路设计复杂度,从而减少计算功耗。进一步优选地,所述稀疏矩阵中每一列的稀疏度约为0.1*m。步骤s202、通过统计排序单元从而采用边输入边统计排序的方式来对第二矩阵中的字符进行个数统计,并且按照字符的个数来对字符进行排序。具体地,将一级压缩数据y按顺序输入哈夫曼编码模块,数据输入有两个通道,一方面将输入的数据暂存在存储器中,以用于后面编码输出,另一方面则输入到统计排序单元进行统计排序,进一步地,所述统计排序单元将输入的数据(即第二矩阵的数据)按4bit为单位进行划分后进行字符的统计排序,其中,所述统计排序原理示意框图可参考图4,所述统计排序单元中的排序模块会根据输入的数据定位至该数据所属的第一寄存器,并将该第一寄存器中所存储的数值加1,即相当于对输入的相同数据进行个数统计,即对字符的个数进行统计,例如,输入的数据为4,即字符为4,那么则定位至字符为4所属的第一寄存器f1,并且将第一寄存器f1中的数值加1,以实现字符4的个数统计;然后,将寄存器f1中所存储的数值与其他字符所属的寄存器中所存储的数值进行一一比较(利用统计排序单元中的比较模块来实现),从而得到数据在输入的整组数据中的新次序,然后新字符h的次序输出至统计排序单元中的排序模块进行存储,以更新字符为4所属的第二寄存器f2中的数值,以实现数据4的次序更新,即第二寄存器所存储的数值表示为对应字符的当前次序,此时一个数据的输入和统计排序已完成,如此类推,对输入的每一个数据(即第二矩阵的数据)进行上述统计排序的循环操作,直至第二矩阵的数据输入完毕,即完成数据的输入和字符统计排序。例如,当第二矩阵中所包含的数据中共有0、1、2、3、4这5个字符时,即第二矩阵的数据中所包含的字符有0、1、2、3、4,那么对第二矩阵的数据进行字符统计排序后得出的结果如以下表1所示:表1数字次序个数40361130222603203415可见,对第二矩阵中的数值相同的数据进行个数统计后得出数字(即字符)0的个数(权值)为20,数字1的个数为30,数字2的个数为26,数字3的个数为15,数字4的个数为36,因此,按照每个字符的个数来对这些字符进行从大到小排序后得出数字4的次序为0,数字1的次序为1,数字2的次序为2,数字0的次序为3,数字3的次序为4;所述数字即相当于字符,个数即相当于权值。其中,图4中的num_order_list表示字符排名列表,用于存储当前字符的次序;num_cnt_eig表示权值特征值列表,用于存储当前字符对应的权值和特征值;num_order_last表示字符当前次序;data_in表示数据输入;num_order_new表示新次序;data表示数据。步骤s203、通过编码单元来根据第二矩阵中的字符所对应的特征值以及字符的个数,对排序后的字符进行哈夫曼编码。具体地,在步骤s202完成数据输入及字符的统计排序后,将排序后的字符输入编码单元进行编码处理,其中,所述编码原理示意框图可如图5所示,所述编码单元在实现哈夫曼编码的过程,先将次序最低的两位字符,以及字符所对应的权值(个数)进行相加,得到一个新字符h,以及新字符h所对应的新权值,同时将次序最低的两位字符对应的特征值相或后得到新字符h所对应的新特征值(通过cnt_eig_processor,即权值特征值处理模块,来实现),然后,一方面将新字符h的权值与其它寄存器相比较得到新字符h的次序,即一方面将新字符h的权值与其他输入的字符的当前权值进行比较,从而得到新字符h的次序(通过编码单元中的比较模块cmp_unit来实现),如,次序最低的两位字符为3和0,那么3和0相加后得到的总和为3,且此时新字符3所对应的权值为35,因此,将新字符3所对应的权值35与其他字符4、1、2所对应的权值36、30、26进行比较后,得出新字符3的次序为1,而字符1、2的次序变为2、3,而新次序和新字符的权值特征值传输至编码单元的排序模块sort_unit中存储;另一方面编码模块coding_unit根据相加两个字符的特征值,即新字符h所对应的特征值,对字符进行编码,其中,次序最低的两位字符中权值较大的字符0,其编码为1,权值较小的字符3,其编码为0。优选地,本实施例中的编码单元,其采用两级流水线来实现,其中,所述两级流水线中的一级流水线用于执行哈夫曼编码中的求和处理操作,所述两级流水线中的另一级流水线用于执行哈夫曼编码中的排序处理操作。如图6所示,传统没有设计流水线的编码单元中,其一个编码周期仅能执行求和操作或者排序操作,而本发明实施例中所采用的编码单元,由于其设计了两级流水线,因此,除第一个编码周期仅执行求和操作外,后续的编码周期均是能实现求和操作和排序操作的并行执行,可见相较于传统的编码单元,本实施例的编码单元缩短近一半的编码周期。步骤s204、通过数据输出单元将编码后得到的数据输出。具体地,所述数据输出单元具体用于先输出字符编码表,然后再输出编码后得到的数据;在完成数据编码后,数据输出单元先输出字符编码表,然后再按照字符编码表,将数据以huffman的编码串行输出,即串行输出编码后得到的数据。对于上述各模块/单元,它们均可利用软件和/或硬件来实现,其根据实际情况/需要来选取便可。而为了对上述步骤s203中所述的哈夫曼编码进行进一步的详细阐述,以下提供一具体编码实施例来进行详细阐述。对于哈夫曼编码,其中所涉及的字符所对应的特征值是生成二叉树的关键,因此,在编码流程之前,需要对特征值及其算法进行说明。编码初始,分别将0-9这十个字符的特征值设定为:字符0所对应的特征值为0000000001;字符1所对应的特征值为0000000010;字符2所对应的特征值为0000000100;字符3所对应的特征值为0000001000;字符4所对应的特征值为0000010000;字符5所对应的特征值为0000100000;字符6所对应的特征值为0001000000;字符7所对应的特征值为0010000000;字符8所对应的特征值为0100000000;字符9所对应的特征值为1000000000。即相当于,对于特征值,在其对应的字符所表示的位置上置1,其他位置上置为0。为了清楚对哈夫曼编码进行说明,以下将用5个数字(字符)来说明特征值的用法及整个哈夫曼编码的处理过程。在编码前,将特征值分别分配给0-4这五个数字:字符0所对应的特征值为00001;字符1所对应的特征值为00010;字符2所对应的特征值为00100;字符3所对应的特征值为01000;字符4所对应的特征值为10000。假定,输入完成后0-4这五个数字的次序、个数、字长、编码分别如下表2和表3所示:表2表3其中,上述个数、特征值存在num_cnt_eig中。第一步:将最低两位执行一次加操作,权值相加,特征值同时执行或操作。此时,权值较小的数字3编码为0,权值较大的数字0编码为1;同时数字3和0的字长分别加1,具体如图7所示。第二步:再次取最低两位相加,权值相加,特征值同时执行或操作。此时,权值较小的数字2编码为0,权值较大的数字1编码为1;同时数字2和1的字长分别加1,具体如图8所示。第三步:次序最低的字符所对应的特征值01001可以分解出01000和00001,因此,判断出数字3和0需编码为0,而次低位的数字4则编码为1;同时数字3、0和4的字长分别加1,具体如图9所示。第四步:最后一次加操作可以不执行,只需要根据最低位特征值00110分解出00100和00010判断2和1需要编码0,由次低位特征值11001分解出10000、01001和00001判断4、3和0需要编码1;同时数字2、1、4、3和0的字长加1,具体如以下表4所示。表4可见,最终得到的编码为0:101;1:01;2:00;3:100;4:11。由上述可得,本发明实施例通过矩阵乘法操作,从而对脑电数据进行基于压缩感知的一级压缩,然后再对一级压缩后的数据进行哈夫曼编码,这样能够减少脑电信号的数据量,从而降低传输功耗和存储消耗。进一步地,本发明实施例还包括的优点有:1、利用稀疏矩阵来对输入的脑电数据完成矩阵乘法操作,由于矩阵的稀疏二值特性,矩阵元素为0或1,所以压缩感知模块中的电路仅需利用m个并行的判断累加单元来实现简单乘法累加操作,便能完成第一级的压缩,大大降低电路复杂度,减少计算功耗;2、哈夫曼编码模块中的统计排序单元,采用了数据边输入边排序的方式来对输入的数据进行字符个数的统计及排序,这样数据在输入完成的同时也完成了数据的字符统计排序,大大减少编码所需周期数;3、哈夫曼编码模块在编码处理过程中,采用二级流水线设计,大大降低编码周期,降低数据压缩时延;4、哈夫曼编码模块中的编码操作利用特征值来快速构造huffman树,为huffman树赋予数字特性,更贴近数字电路的构成方式。总体来说,本发明实施例采用一级有损压缩和二级无损压缩的结合,能够在很低的计算消耗下实现高压缩比,达到提高了脑电信号的压缩率,减少数据存储量,减少了数据传输功耗的效果。以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1