一种利用植物维生素C合成途径构建生产维生素C大肠杆菌菌株的方法与流程
本发明属于微生物合成生物学领域,具体涉及一种利用植物维生素c合成途径构建大肠杆菌菌株合成维生素c的方法。
背景技术:
维生素c(简写vc),又名抗坏血酸,是一种水溶性维生素。人类、猿猴、天竺鼠和一些鱼类、鸟类无法自行合成维生素c,需通过食物来供应身体所需。vc是一种必需维生素,参与胶原蛋白的合成,可预防动脉硬化;vc是一种强抗氧化剂,具有保护细胞、解毒和保护肝脏作用;vc还可用于增强肌体免疫力,预防感冒等急、慢性传染病,还可用于病后恢复期、创伤愈合期及过敏性疾病的辅助治疗,vc缺乏引起坏血病,造成牙龈萎缩、出血等等病症。人类vc的主要食物来源:柑桔类水果、蔬菜等。食物中的vc能被人体小肠吸收,分布到体内所有的水溶性结构中,普通成人体内vc代谢活性池中vc量1500mg左右。
维生素c主要应用在制药、保健品、软饮料及饲料添加等领域,主要消费市场在欧美等发达国家。目前,全球vc市场需求量约12万吨。我国是全球最大的c生产国和出口国,每年出口超过10亿美元。但是,每当人们提到vc产业,自然就会联想到无情的价格战,以罗氏(roche)为主的跨国公司试图挤垮中国的vc企业,从1996年至2001年,出现两次降价狂潮,使vc价格从12美元/kg降到2001年的2.8美元/kg,使我国20多家企业被迫停产。在几轮竞争中,由于中国企业首创“两步发酵法”生产vc核心技术,在人力等成本上也有明显竞争优势,保住了vc产业的一席之地,使国内企业与roche(dsm)和basf形成了三足鼎立之势。但是vc产业化技术的研发工作并没有停息,如:eastman与genencor合作开发的生化触媒法,即用多个酶进行多步转化,从玉米制造维生素c。其他国际大厂也都在不断降低制造成本,如巴斯夫除了致力于将目前的制造工艺进行优化外,也在开发或引进新的低成本制造工艺。目前,欧美厂商目前都在积极探索vc新的合成路径。国内在“二步发酵法”生产vc研究和应用领域均处于世界领先水平,但新的途径研究投入不足,在细菌“一步发酵法”合成vc研究领域已经处于明显劣势。
在二步发酵法中,依次在d-山梨醇脱氢酶(sldh)、l-山梨糖脱氢酶(sdh)及l-山梨酮脱氢酶(sndh)的作用下,可以有效地将d-山梨醇转化为维生素c的前体物质2-klg(尹光琳等,微生物学报,1980,20(3),246-251)。细菌山梨醇“一步发酵法”研发工作走在最前列的首推dsm,取得一系列领先成果,包括葡糖杆菌gluconobacteroxydansdsm17078全部kga代谢密切相关的基因(l-山梨酮脱氢酶基因、d-山梨醇脱氢酶基因,以及l-山梨糖脱氢酶基因a、b、c、d)的分离克隆(usptopatent,20110250636),及以上基因敲除或过表达对kga生物合成的影响;糖转运蛋白基因sts24和sts01的敲除或过表达对kga生物合成的影响(unitedstatespatent5437989);pqq生物合成基因对kga合成的影响(yuan等bmcbiotechnology,2016,16,1-14);以及其他基因(vcs01和vcs08等)对kga合成的影响(europeanpatentapplicationep1103603)。此外,还尝试了多种技术手段对葡糖杆菌进行基因改良,取得了理想的研究效果。申报相关国际发明专利30多项,专利覆盖了50多个细菌相关基因以及10多个细菌种类的利用,包括大肠杆菌、假单胞菌、泛菌、谷氨酸棒杆菌、普通酮古龙酸菌、氧化葡萄糖酸杆菌、醋细菌和葡糖醋杆菌等。
大部分的植物和动物都可以通过一系列的酶促反应转化d-葡萄糖合成维生素c。在真核生物中,维生素c可以通过两个不同的生化途径合成。在鼠类及其它的哺乳动物中,葡萄糖通过一个复杂途径转化成l-古洛糖酸-1,4-内酯。这一途径是由终端酶l-古洛糖酸-1,4-内酯氧化酶在动物界中的普遍存在推断而来的。而在人类及其它一些动物中,编码l-古洛糖酸-1,4-内酯氧化酶的基因发生了突变,造成其合成维生素c能力的丧失。大多数的植物细胞中都有大量维生素c的合成,它在过氧化物、臭氧及自由基的解毒方面起着至关重要的作用。另外,维生素c在通过水溶性抗氧化剂(α-生育酚)、玉米黄质和ph介导的psii活性的再生调节光合作用活性的过程中是必不可少的。植物细胞可以积累大量的维生素c,特别是在绿色组织和贮藏器官中。因为在植物细胞中存在由d-半乳糖生成维生素c的完整合成途径,目前研究人员已经开始尝试利用植物细胞或微藻培养物通过发酵生产维生素c。据报道,running等人分离得到的小球藻突变体产维生素c的产量从0.64mg/g干细胞提高到45mg/g细胞(journalofappliedphycology,1994,6(2),99-104),但是这与工业上采用的经典二步发酵法的高产量尚无竞争性。进一步提高利用植物细胞或藻类一步生产维生素c的产量需要进行系统的代谢工程改造,然而植物中维生素c合成途径的研究进展非常缓慢使得代谢工程改造很难操作。
植物中初始的维生素c合成模型是根据动物中的合成机理建立的。然而,植物细胞中是不含l-古洛糖酸-1,4-内酯氧化酶的,多年来一直未得到植物中维生素c合成途径的直接证据,直到后来利用拟南芥中影响维生素c生物合成突变体的鉴定,提出了经过gdp-甘露糖和l-半乳糖的维生素c从头合成途径。在随后的几年间,研究者提出了植物细胞中还可能存在一些其它的维生素c合成途径,但目前对这些新合成途径的认识比较有限。
植物细胞中维生素c从葡萄糖开始合成途径涉及10个酶,拟南芥中这10个酶包括:athxk1、atpgi、atdin9、atpmm、atvtc1、atgme、atvtc2、atvtc4、atgaldh和atgldh(conklin,genetics,2000,154,847-856)。葡萄糖在己糖激酶hxk催化下转化为葡萄糖-6-磷酸,再经磷酸葡萄糖异构酶pgi转化为果糖-6-磷酸,磷酸甘露糖异构酶(pmi或din9)将果糖-6-磷酸转化为d-甘露糖-6-磷酸,在甘露糖变位酶(pmm)催化下转化为d-甘露糖-1-磷酸,进一步经过gdp-甘露糖焦磷酸化酶(vtc1)催化形成gdp-d-甘露糖,再经过gdp-甘露糖-3’5’异构酶(gme)作用下合成gdp-l-半乳糖。gdp-l-半乳糖通过半乳糖途径合成vc,其中需要gdp-l-半乳糖磷酸化酶(vtc2)将gdp-l-半乳糖转化为l-甘露糖-1-磷酸,l-半乳糖-1-磷酸酯酶(vtc4)将l-甘露糖-1-磷酸转化为l-半乳糖,l-半乳糖脱氢酶(galdh)将l-半乳糖转化为l-半乳糖-1,4-内酯,最后在l-半乳糖-1,4-内酯脱氢酶(gldh)作用下合成维生素c。植物中维生素c合成途径的发现使得实现由葡萄糖、淀粉或者纤维素直接发酵生产维生素c成为可能。
技术实现要素:
本发明的目的在于提供一种利用大肠杆菌生产维生素c的方法,该方法通过将植物维生素c合成途径中的11个基因转化到大肠杆菌中,使大肠杆菌能够直接利用葡萄糖为碳源,转化为维生素c。
为达到上述目的,本发明的技术方案是。
一种利用植物的维生素c合成途径创制一步发酵合成维生素c大肠杆菌菌株的方法:将植物的维生素c合成的基因构建多基因单顺反子组成的原核表达载体;将所述原核表达载体转化到大肠杆菌中。
优选地,所述植物的维生素c合成的基因来源于草莓。
优选地,所述植物的维生素c合成的基因通过多基因定点突变方法消除了基因中常用的限制性内切酶位点。这些位点包括ecori、sali、bamhi、kpni,xbai、saci和hindiii。
优选地,多基因单顺反子组成的原核表达载体由t7表达系统组成,11个改造的维生素c合成基因全部使用t7启动子和终止子控制,构建基因表达元件。
所述维生素c合成的原核表达载体的构建方法为:利用改良的“重叠延伸pcr技术”构建维生素c合成所有11个基因的表达盒。在pcambia-1301载体的基础上,通过在ecori和hindiii限制性内切酶切点间插入的多克隆位点片段,可以构成多基因表达单元,该载体的ecori和sali,sali和bamhi,bamhi和kpni,kpni和xbai,xbai和hindiii限制性内切酶切点之间均可以插入基因表达盒,从而构成多基因表达载体。
所述构建的大肠杆菌表达载体pyb2130通过电击法导入到大肠杆菌中。
优选地,所述大肠杆菌包括bl21(de3)等所有含有t7rna聚合酶的菌株。
本发明的有益效果如下。
1,当大肠杆菌获得植物的维生素c合成基因后能够合成维生素c。
2,通过本发明构建的大肠杆菌菌株可以直接将葡萄糖转化为维生素c。
3,该套体系操作简单,避免了使用两步发酵过程的麻烦。
附图说明
图1为本发明实施例中构建的维生素c原核表达载体pyb2130。
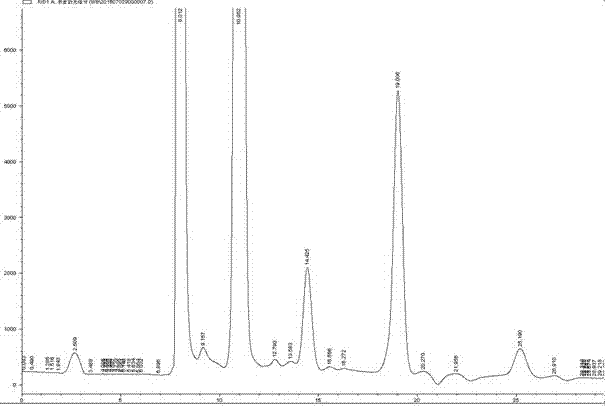
图2为本发明实施例中大肠杆菌发酵后检测。
具体实施方式
以下实施例中涉及的构建维生素c合成原核表达载体pyb2130,其具体的构建方法如下。
草莓果实总rna,cdna合成试剂盒为clontech公司产品;dna柱回收试剂盒购置amersham公司;试剂rna抽提试剂盒rneasyplantminikit为qiagen公司产品;各种限制性内切酶和t4dnaligase均购自上海takara公司。总rna采用qiagen公司的rneasyplantminikit提取。
取约50µl草莓草莓果实总rna进行cdna合成,cdna的合成按clontech公司smartcdnalibraryconstructionkit说明书操作进行第一链合成。
1、构建改造的草莓己糖磷酸激酶基因(fvhxk1)。
从草莓中克隆己糖磷酸激酶基因并利用定点突变方法将90位xhoi限制性内切酶位点;229位hindiii限制性内切酶位点;632位saci限制性内切酶位点;720位kpni限制性内切酶位点;935和1148位bgii限制性内切酶位点;1238位bamhi限制性内切酶位点;1342位ecori限制性内切酶位点消除。
以合成的cdna第一链为模板,扩增引物:hxk1:atggggaaggtggcggtgggt(seqidno.1所示),hxk2:ttaggagtcctcgacaccaag(seqidno.2所示)。pcr反应条件:98℃预变性3min;94℃变性30s,60℃退火30s,72℃延伸90s,30个循环;72℃保温10min。pcr结束后,采用酚:氯仿抽提,再加入2倍体积的无水乙醇进行沉淀。沉淀用30µl水溶解,取1µl为模板。
90位xhoi限制性内切酶位突变引物:90z:gagattgaaaagcttgagga(seqidno.3所示);90f:tcctcaagcttttcaatctc(seqidno.4所示)。
229位hindiii限制性内切酶位突变引物:229z:agcaagcctaagatgctcatcag(seqidno.5所示);229f:ctgatgagcatcttaggcttgct(seqidno.6所示)。
632位saci限制性内切酶位突变引物:632z:cagagttcaccaaatcagtgga(seqidno.7所示);632f:tccactgatttggtgaactctg(seqidno.8所示)。
720位kpni限制性内切酶位突变引物:720z:aggtaacacaatccgcatgt(seqidno.9所示);720f:acatgcggattgtgttacct(seqidno.10所示)。
935位bglii限制性内切酶位突变引物:935z:agaactttgagaagattatttc(seqidno.11所示);935f:gaaataatcttctcaaagttct(seqidno.12所示)。
1148位bglii限制性内切酶位突变引物:1148z:gaaggatatcttagagacct(seqidno.13所示);1148f:aggtctctaagatatccttc(seqidno.14所示)。
1238位bamhi限制性内切酶位突变引物:1238z:ctgggattctgggagtcctta(seqidno.15所示);1238f:taaggactcccagaatcccag(seqidno.16所示)。
以引物hxk1和90f;90z和229f;229z和632f;632z和720f;720z和935f;935z和1148f;1148z和1238f;1238z和hxk2进行pcr扩增,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,1min。共25个循环,pcr结束后,dna片断用10%丙烯酰胺胶回收,将上述8个回收片断取10-100ng为模板混合,以hxk1和hxk2为引物将上述片断拼接,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,2min。共25个循环。pcr结束后,dna柱回收pcr片断。将片段进行ta克隆,获得质粒t1,并将质粒t1高效转化到大肠杆菌dh5α感受态细胞中。
2、构建改造的草莓己糖磷酸异构酶(pgi)基因fvpgi。
从草莓中克隆草莓己糖磷酸异构酶并利用定点突变方法将264位xbai限制性内切酶位点;293位saci限制性内切酶位点;1126位bamhi限制性内切酶位点;1294位sphi限制性内切酶位点;1504位bgii限制性内切酶位点消除。
扩增引物为:pgi1:5’-atggcatctatctctggtatctgttc-3’(seqidno.17所示)pgi2:5’-taggagtacagtgcatcgacgttg-3’(seqidno.18所示)。pcr反应条件:98℃预变性3min;94℃变性30s,60℃退火30s,72℃延伸120s,30个循环;72℃保温10min。pcr结束后,采用酚:氯仿抽提,再加入2倍体积的无水乙醇进行沉淀。沉淀用30µl水溶解,取1µl为模板。
264位xbai和293位saci限制性内切酶位突变引物:264z:tcttgactggctgtaccagcacaaggagttcg(seqidno.19所示);264f:cgaactccttgtgctggtacagccagtcaaga(seqidno.20所示)。
1126位bamhi限制性内切酶位突变引物:1126z:ggaaccaaggatatggttgttct(seqidno.21所示);1126f:agaacaaccatatccttggttcc(seqidno.22所示)。
1294位sphi限制性内切酶位突变引物:1294z:ggagcacggatcagcttgca(seqidno.23所示);1294f:tgcaagctgatccgtgctcc(seqidno.24所示)。
1504位bglii限制性内切酶位突变引物:1504z:gaagaagtaacacctagaact(seqidno.25所示);1504f:agttctaggtgttacttcttc(seqidno.26所示)。
以引物pgi1和264f;264z和1126f;1126z和1294f;1294z和1504f;1504z和pgi2进行pcr扩增,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,1min。共25个循环,pcr结束后,dna片断用10%丙烯酰胺胶回收,将上述8个回收片断取10-100ng为模板混合,以pgi1和pgi2为引物将上述片断拼接,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,2min。共25个循环。pcr结束后,dna柱回收pcr片断。将片段进行ta克隆,获得质粒t2,并将质粒t2高效转化到大肠杆菌dh5α感受态细胞中。
3、构建改造的草莓磷酸甘露糖异构酶(pmi)基因fvpmi。
从草莓中克隆甘露糖异构酶基因并利用定点突变方法将817位hindiii限制性内切酶位点;1038位kpni限制性内切酶位点;1110和1221位psti限制性内切酶位点消除。
以合成的cdna第一链为模板,扩增引物为:pmi1:5’-atggagaagtccatgatcgagaagtc-3’(seqidno.27所示)pmi2:5’-ttatggcagctggaagaacatggagt-3’(seqidno.28所示)。pcr反应条件:98℃预变性3min;94℃变性30s,60℃退火30s,72℃延伸90s,30个循环;72℃保温10min。pcr结束后,采用酚:氯仿抽提,再加入2倍体积的无水乙醇进行沉淀。沉淀用30µl水溶解,取1µl为模板。
817位hindiii限制性内切酶位突变引物:817z:ctcaactatgtcaaggtt(seqidno.29所示);817f:aaccttgacatagttgag(seqidno.30所示)。
1038位kpni和1110位psti限制性内切酶位突变引物:1038z:ggttcctcccaccttttgacgagtttgaggtcgatcggtgccatcttccccagggagaatcagtggaatttcctgaag(seqidno.31所示);1038f:cttcaggaaattccactgattctccctggggaagatggcaccgatcgacctcaaactcgtcaaaaggtgggaggaacc(seqidno.32所示)。
1221位psti限制性内切酶位突变引物:1221z:cttttcgtgcctgaaggt(seqidno.33所示);1221f:accttcaggcacgaaaag(seqidno.34所示)。
以引物pmi1和817f;817z和1038f;1038z和1221f;1221z和720f;720z和935f;935z和1148f;1148z和1238f;1238z和pmi2进行pcr扩增,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,1min。共25个循环,pcr结束后,dna片断用10%丙烯酰胺胶回收,将上述8个回收片断取10-100ng为模板混合,以pmi1和pmi2为引物将上述片断拼接,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,2min。共25个循环。pcr结束后,dna柱回收pcr片断。将片段进行ta克隆,获得质粒t3,并将质粒t3高效转化到大肠杆菌dh5α感受态细胞中。
4、构建改造的草莓磷酸甘露糖变位酶(pmm)基因fvpmm。
从草莓中克隆磷酸甘露糖变位酶基因并利用定点突变方法将139位bamhi限制性内切酶位点;537位hindiii限制性内切酶位点消除。
以合成的cdna第一链为模板,扩增引物为:pmm1:5’-atggctgtcatgaagcctggtgtc-3’(seqidno.35所示)pmm2:5’-ttaggaagagaagaacagagccttaac-3’(seqidno.36所示)。pcr反应条件:98℃预变性3min;94℃变性30s,60℃退火30s,72℃延伸60s,30个循环;72℃保温10min。pcr结束后,采用酚:氯仿抽提,再加入2倍体积的无水乙醇进行沉淀。沉淀用30µl水溶解,取1µl为模板。
139位bamhi限制性内切酶位突变引物:139z:cagtgggcattgttggaggaacc(seqidno.37所示);139f:ggttcctccaacaatgcccactg(seqidno.38所示)。
537位hindiii限制性内切酶位突变引物:537z:gatatgctttgatgtttttcctc(seqidno.39所示);537f:gaggaaaaacatcaaagcatatc(seqidno.40所示)。
以引物pmm1和139f;139z和537f;537z和pmm2进行pcr扩增,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,1min。共25个循环,pcr结束后,dna片断用10%丙烯酰胺胶回收,将上述8个回收片断取10-100ng为模板混合,以pmm1和pmm2为引物将上述片断拼接,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,2min。共25个循环。pcr结束后,dna柱回收pcr片断。将片段进行ta克隆,获得质粒t4,并将质粒t4高效转化到大肠杆菌dh5α感受态细胞中。
5、构建改造的草莓gdp-d-甘露糖焦磷酸化酶(gmpase,vtc1)基因fvvtc。
从草莓中克隆gdp-d-甘露糖焦磷酸化酶基因并利用定点突变方法将367位ecori限制性内切酶位点;904位sphi限制性内切酶位点消除。
以合成的cdna第一链为模板,扩增引物为:vtc1z:5’-atgaaggcactgattctggtcggt-3’(seqidno.41所示)vtc1f:5’-ttacatgacgatctcaggcttc-3’(seqidno.42所示)。pcr反应条件:98℃预变性3min;94℃变性30s,60℃退火30s,72℃延伸60s,30个循环;72℃保温10min。pcr结束后,采用酚:氯仿抽提,再加入2倍体积的无水乙醇进行沉淀。沉淀用30µl水溶解,取1µl为模板。
367位ecori限制性内切酶位突变引物:367z:tggattccataaatcccatg(seqidno.43所示);367f:catgggatttatggaatcca(seqidno.44所示)。
904位sphi限制性内切酶位突变引物:904z:tcggatcaagaagcttgcttg(seqidno.45所示);904f:caagcaagcttcttgatccga(seqidno.46所示)。
以引物vtc1z和367f;367z和904f;904z和vtc1f进行pcr扩增,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,1min。共25个循环,pcr结束后,dna片断用10%丙烯酰胺胶回收,将上述8个回收片断取10-100ng为模板混合,以vtc1z和vtc1f为引物将上述片断拼接,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,2min。共25个循环。pcr结束后,dna柱回收pcr片断。将片段进行ta克隆,获得质粒t5,并将质粒t5高效转化到大肠杆菌dh5α感受态细胞中。
6、构建改造的草莓gdp-d-甘露糖-3,5-表异构酶(gme)fvgme。
从草莓中克隆gdp-d-甘露糖-3,5-表异构酶基因并利用定点突变方法将217位ecori限制性内切酶位点;667位psti限制性内切酶位点消除。
以合成的cdna第一链为模板,扩增引物为:gme1:5’-atgggttctgctggtgagtctg-3’(seqidno.47所示)gme2:5’-ttactccttaccatcagcagcac-3’(seqidno.48所示)。pcr反应条件:98℃预变性3min;94℃变性30s,60℃退火30s,72℃延伸60s,30个循环;72℃保温10min。pcr结束后,采用酚:氯仿抽提,再加入2倍体积的无水乙醇进行沉淀。沉淀用30µl水溶解,取1µl为模板。
217位ecori限制性内切酶位突变引物:217z:gagttccatcttgtggatctcag(seqidno.49所示);217f:ctgagatccacaagatggaactc(seqidno.50所示)。
667位psti限制性内切酶位突变引物:667z:ctgaagaaaggctctcacatccac(seqidno.51所示);667f:gtggatgtgagagcctttcttcag(seqidno.52所示)。
以引物gme1和217f;217z和667f;667z和gme2进行pcr扩增,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,1min。共25个循环,pcr结束后,dna片断用10%丙烯酰胺胶回收,将上述8个回收片断取10-100ng为模板混合,以gme1和gme2为引物将上述片断拼接,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,2min。共25个循环。pcr结束后,dna柱回收pcr片断。将片段进行ta克隆,获得质粒t6,并将质粒t6高效转化到大肠杆菌dh5α感受态细胞中。
7、构建改造的草莓gdp-l-半乳糖磷酸化酶(ggp,vtc2)基因fvvtc2。
从草莓中克隆gdp-l-半乳糖磷酸化酶基因并利用定点突变方法将258位sphi限制性内切酶位点;624位hindiii限制性内切酶位点;1070位ndei限制性内切酶位点;1236位bamhi限制性内切酶位点;1337位psti限制性内切酶位点消除。
以合成的cdna第一链为模板,扩增引物为:vtc2z:5’-atgatgctgaagatcaagcgtg-3’(seqidno.53所示);vtc2f:5’-ttactggagaaccagacactcct-3’(seqidno.54所示)。pcr反应条件:98℃预变性3min;94℃变性30s,60℃退火30s,72℃延伸90s,30个循环;72℃保温10min。pcr结束后,采用酚:氯仿抽提,再加入2倍体积的无水乙醇进行沉淀。沉淀用30µl水溶解,取1µl为模板。
258位sphi限制性内切酶位突变引物:258z:gcttgcagaaagggctatttc(seqidno.55所示);258f:gaaatagccctttctgcaagc(seqidno.56所示)。
624位hindiii限制性内切酶位突变引物:624z:gaaaccttcttgcttgcacttc(seqidno.57所示);624f:gaagtgcaagcaagaaggtttc(seqidno.58所示)。
1070位ndei限制性内切酶位突变引物:1070z:caccacatgtccactaatttc(seqidno.59所示);1070f:gaaattagtggacatgtggtg(seqidno.60所示)。
1236位kpni限制性内切酶位突变引物:1236z:gaggaaccagatgtcaatcctc(seqidno.61所示);1236f:gaggattgacatctggttcctc(seqidno.62所示)。
以引物vtc2z和258f;258z和624f;624z和1070f;1070z和1236f;1236z和vtc2f进行pcr扩增,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,1min。共25个循环,pcr结束后,dna片断用10%丙烯酰胺胶回收,将上述8个回收片断取10-100ng为模板混合,以vtc2z和vtc2f为引物将上述片断拼接,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,2min。共25个循环。pcr结束后,dna柱回收pcr片断。将片段进行ta克隆,获得质粒t7,并将质粒t7高效转化到大肠杆菌dh5α感受态细胞中。
8、构建改造的草莓l-半乳糖-1-磷酸酶(gpp,vtc4)基因fvvtc4。
从草莓中克隆l-半乳糖-1-磷酸酶基因并利用定点突变方法将42位psti限制性内切酶位点;161位saci限制性内切酶位点;270位bamhi限制性内切酶位点消除。
以合成的cdna第一链为模板,扩增引物:vtc4z:atggctgaaaatgattcgcttgctctgttcttggcctctgcagt(seqidno.63所示),vtc4f:ttaggagtcctcgacaccaag(seqidno.64所示)。pcr反应条件:98℃预变性3min;94℃变性30s,60℃退火30s,72℃延伸90s,30个循环;72℃保温10min。pcr结束后,采用酚:氯仿抽提,再加入2倍体积的无水乙醇进行沉淀。沉淀用30µl水溶解,取1µl为模板。
161位saci限制性内切酶位突变引物:161z:gagttcatatttaatcatctca(seqidno.65所示);161f:tgagatgattaaatatgaactc(seqidno.66所示)。
270位bamhi限制性内切酶位突变引物:270z:gtggaacccctggatggcac(seqidno.67所示);270f:gtgccatccaggggttccac(seqidno.68所示)。
以引物vtc4z和161f;161z和270f;270z和vtc4f进行pcr扩增,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,1min。共25个循环,pcr结束后,dna片断用10%丙烯酰胺胶回收,将上述8个回收片断取10-100ng为模板混合,以vtc4z和vtc4f为引物将上述片断拼接,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,2min。共25个循环。
pcr结束后,dna柱回收pcr片断。将片段进行ta克隆,获得质粒t8,并将质粒t8高效转化到大肠杆菌dh5α感受态细胞中。
9、构建改造的草莓l-半乳糖醛酸内酯脱氢酶(galdh)基因fvgaldh。
从草莓中克隆l-半乳糖醛酸内酯脱氢酶基因并利用定点突变方法将678位ndei限制性内切酶位点消除。
以合成的cdna第一链为模板,扩增引物为:galdh1:5’-atgactatccactactctgtcg-3’(seqidno.69所示)galdh2:5’-ttaggactgctggataccagaag-3’(seqidno.70所示)。pcr反应条件:98℃预变性3min;94℃变性30s,60℃退火30s,72℃延伸60s,30个循环;72℃保温10min。pcr结束后,采用酚:氯仿抽提,再加入2倍体积的无水乙醇进行沉淀。沉淀用30µl水溶解,取1µl为模板。
678位xhoi限制性内切酶位突变引物:678z:ctttaggaattttcacatatgt(seqidno.71所示);678f:acatatgtgaaaattcctaaag(seqidno.72所示)。
以引物galdh1和678f;678z和galdh2进行pcr扩增,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,1min。共25个循环,pcr结束后,dna片断用10%丙烯酰胺胶回收,将上述8个回收片断取10-100ng为模板混合,以galdh1和galdh2为引物将上述片断拼接,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,2min。共25个循环。pcr结束后,dna柱回收pcr片断。将片段进行ta克隆,获得质粒t9,并将质粒t9高效转化到大肠杆菌dh5α感受态细胞中。
10、构建改造的草莓l-半乳糖脱氢酶(gldh)基因fvgldh。
从草莓克隆l-半乳糖脱氢酶基因并利用定点突变方法将12和263位saci限制性内切酶位点;340位xhoi限制性内切酶位点;602位ecori限制性内切酶位点;611和1625位psti限制性内切酶位点;1320位bgii限制性内切酶位点;1419位hindiii限制性内切酶位点消除。
以合成的cdna第一链为模板,扩增引物为:gldhz:5’-atgcaacgagcactgactctgaag-3’(seqidno.73所示)gldhf:5’-ttagatggtgtcagaggatggga-3’(seqidno.74所示)。pcr反应条件:98℃预变性3min;94℃变性30s,60℃退火30s,72℃延伸120s,30个循环;72℃保温10min。pcr结束后,采用酚:氯仿抽提,再加入2倍体积的无水乙醇进行沉淀。沉淀用30µl水溶解,取1µl为模板。
263位saci限制性内切酶位突变引物:263z:gagttccacaccgtctctaac(seqidno.75所示);263f:gttagagacggtgtggaactc(seqidno.76所示)。
340位xhoi限制性内切酶位突变引物:340z:gagctggagaaagtggtcaag(seqidno.77所示);340f:cttgaccactttctccagctc(seqidno.78所示)。
602位ecori限制性内切酶位突变引物:602z:gaactctgcaggttggtgcacatggtac(seqidno.79所示);602f:gtaccatgtgcaccaacctgcagagttc(seqidno.80所示)。
1320位bglii限制性内切酶位突变引物:1320z:agttctaaaacagctaatag(seqidno.81所示);1320f:ctattagctgttttagaact(seqidno.82所示)。
1419位bglii限制性内切酶位突变引物:1419z:aaggttaaaggaggatgatata(seqidno.83所示);1419f:tatatcatcctcctttaacctt(seqidno.84所示)。
1625位psti限制性内切酶位突变引物:1625z:caaagaacagcttaccactctgaag(seqidno.85所示);1625f:cttcagagtggtaagctgttctttg(seqidno.86所示)。
以引物gldhz和263f;263z和340f;340z和602f;602z和1320f;1320z和1419f;1419z和1625f;1625z和gldhf进行pcr扩增,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,1min。共25个循环,pcr结束后,dna片断用10%丙烯酰胺胶回收,将上述8个回收片断取10-100ng为模板混合,以gldhz和gldhf为引物将上述片断拼接,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,2min。共25个循环。pcr结束后,dna柱回收pcr片断。将片段进行ta克隆,获得质粒t10,并将质粒t10高效转化到大肠杆菌dh5α感受态细胞中。
11、构建改造的草莓脱氢抗坏血酸还原酶(dhar)基因fvdhar。
从草莓中克隆脱氢抗坏血酸还原酶基因并利用定点突变方法将33位psti限制性内切酶位点;339位bamhi限制性内切酶位点;453和521位hindiii限制性内切酶位点消除。
以合成的cdna第一链为模板,扩增引物为:dharz:5’-atggctcttgaggttgctgccaaggctgctggag-3’(seqidno.87所示)dharf:5’-ttacttaggattgaccttaggttc-3’(seqidno.88所示)。pcr反应条件:98℃预变性3min;94℃变性30s,60℃退火30s,72℃延伸60s,30个循环;72℃保温10min。pcr结束后,采用酚:氯仿抽提,再加入2倍体积的无水乙醇进行沉淀。沉淀用30µl水溶解,取1µl为模板。
339位bamhi限制性内切酶位突变引物:339z:gacattcctcaagagcaaggaacc(seqidno.89所示);339f:ggttccttgctcttgaggaatgtc(seqidno.90所示)。
453位hindiii限制性内切酶位突变引物:453z:gtcactgctgctgatctaaccttg(seqidno.91所示);453f:caaggttagatcagcagcagtgac(seqidno.92所示)。
521位hindiii限制性内切酶位突变引物:521z:ctaaaggtttgacccattaccat(seqidno.93所示);521f:atggtaatgggtcaaacctttag(seqidno.94所示)。
以引物dharz和339f;339z和453f;453z和521f;521z和dharf进行pcr扩增,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,1min。共25个循环,pcr结束后,dna片断用10%丙烯酰胺胶回收,将上述8个回收片断取10-100ng为模板混合,以dharz和dharf为引物将上述片断拼接,扩增条件为:94℃预热1min;94℃,30s,60℃,30s,72℃,2min。共25个循环。pcr结束后,dna柱回收pcr片断。将片段进行ta克隆,获得质粒t11,并将质粒t11高效转化到大肠杆菌dh5α感受态细胞中。
实施例1,构建葡萄糖合成维生素c原核表达载体。
将上述11个改造的维生素c合成基因全部使用t7启动子和终止子控制,构建基因表达元件。首先,我们利用“重叠延伸pcr技术”构建维生素c合成所有11个基因的表达盒。启动子、基因和终止子之间不含限制性内切酶位点。构建的大肠杆菌表达单元为:t7fvhxk1s、t7fvpgis、t7fvpmis、t7fvpmms、t7fvvtc1s、t7fvgmes、t7fvvtc2s、t7fvvtc4s、t7fvgaldhs、t7fvgldhs、t7fvdhars。
t7启动子序列为:gaattcctcgagcgatcccgcgaaattaatacgactcactataggggaattgtgagcggataacaattcccctctagaaataattttgtttaactttaagaaggagatatacc(seqidno.95所示)。
t7终止子序列为:ctagcataaccccttggggcctctaaacgggtcttgaggggttttttggtcgacggtgacgttgagcatggtaagctt(seqidno.96所示)。
构建的表达单元在puc18载体上两两拼接,完成后消除内在的酶切位点,然后依次插入载体pcambia-1301,最终构建成大肠杆菌维生素c合成载体pyb2130。
实施例2,葡萄糖合成维生素c原核表达载体pyb2130大肠杆菌转化
1)大肠杆菌感受态细胞制备。
大肠杆菌菌株为bl21(de3),或bl21-ai等含有t7rna聚合酶的菌株。挑取单菌在25mllb培养基37℃培养过夜,取5ml菌液转接到100mllb培养基,培养至od600=0.7-0.8,菌液冰上放置10分钟,5000rpm离心10min,4℃,收集菌体,加入100ml无菌双蒸水清洗两次。加入4ml10%甘油悬浮菌体,转到50ml离心管。5500rpm离心10min,4℃。收集菌体,加入500µl10%甘油悬浮菌体,转到1.5ml离心管。
2)维生素c原核表达载体yb2130经电击法导人大肠杆菌中。
取70µl农杆菌感受态细胞,加入1µl表达载体pyb2130。混匀,转到0.1cm电击杯中。电击参数:200ω,1.7kv,2.5f,电击后立即加入800µlsoc培养液。培养1小时后,取100µl涂50µg/l卡那霉素抗性板筛选转化子,37℃培养。筛选生长良好的菌落培养后-70℃甘油管冻存。
3)验证大肠杆菌利用葡萄糖合成维生素c。
将在-70℃甘油管冻存的工程菌接种于装有所需培养基的小试管中,接种含卡那霉素(kmp,30mg/l)的3mllb试管,在30℃培养过夜,过夜菌再以2%接种50ml含抗生素的lb摇瓶,在30℃培养2-6h后,加入iptg或iptg+0.2%阿拉伯糖诱导培养24-72小时,转速均为200r/min。加入葡萄糖终浓度10mg/ml。测定发酵终止液的菌体光密度值和维生素c的含量。
4)维生素c含量hplc检测。
取10ml发酵菌液,离心收集菌体,液氮研磨,加0.1%草酸1ml,冰浴1小时,超声处理5min。10000rpm离心10min,取上清,过0.45μm滤膜。发酵上清样品用等体积0.2%草酸稀释,过0.45μm滤膜。
高效液相(hplc)条件:色谱柱:symmetryshieldrp18柱(5μm,150x4.6mm)。流动相为甲醇:0.1%草酸=5:95,检测波长245nm,柱温为30℃,流速1.0ml/min,外标法定量。样品每次进样10μl,将与标品相同保留时间处的峰的峰面积代入标准曲线方程,计算样品中维生素c的含量。
色谱图结果表明:大肠杆菌诱导培养3天后,可以检测到维生素c,维生素c的含量为0.5-1μg/ml。
序列表
<110>上海市农业科学院
<120>一种利用植物维生素c合成途径构建生产维生素c大肠杆菌菌株的方法
<130>2017
<160>96
<170>patentinversion3.3
<210>1
<211>21
<212>dna
<213>人工序列
<400>1
atggggaaggtggcggtgggt21
<210>2
<211>21
<212>dna
<213>人工序列
<400>2
ttaggagtcctcgacaccaag21
<210>3
<211>20
<212>dna
<213>人工序列
<400>3
gagattgaaaagcttgagga20
<210>4
<211>20
<212>dna
<213>人工序列
<400>4
tcctcaagcttttcaatctc20
<210>5
<211>23
<212>dna
<213>人工序列
<400>5
agcaagcctaagatgctcatcag23
<210>6
<211>23
<212>dna
<213>人工序列
<400>6
ctgatgagcatcttaggcttgct23
<210>7
<211>22
<212>dna
<213>人工序列
<400>7
cagagttcaccaaatcagtgga22
<210>8
<211>22
<212>dna
<213>人工序列
<400>8
tccactgatttggtgaactctg22
<210>9
<211>60
<212>dna
<213>人工序列
<400>9
aggtaacacaatccgcatgt20
<210>10
<211>20
<212>dna
<213>人工序列
<400>10
acatgcggattgtgttacct20
<210>11
<211>22
<212>dna
<213>人工序列
<400>11
agaactttgagaagattatttc22
<210>12
<211>22
<212>dna
<213>人工序列
<400>12
gaaataatcttctcaaagttct22
<210>13
<211>20
<212>dna
<213>人工序列
<400>13
gaaggatatcttagagacct20
<210>14
<211>20
<212>dna
<213>人工序列
<400>14
aggtctctaagatatccttc20
<210>15
<211>21
<212>dna
<213>人工序列
<400>15
ctgggattctgggagtcctta21
<210>16
<211>21
<212>dna
<213>人工序列
<400>16
taaggactcccagaatcccag21
<210>17
<211>26
<212>dna
<213>人工序列
<400>17
atggcatctatctctggtatctgttc26
<210>18
<211>25
<212>dna
<213>人工序列
<400>18
taggagtacagtgcatcgacgttgc25
<210>19
<211>32
<212>dna
<213>人工序列
<400>19
tcttgactggctgtaccagcacaaggagttcg32
<210>20
<211>32
<212>dna
<213>人工序列
<400>20
cgaactccttgtgctggtacagccagtcaaga32
<210>21
<211>23
<212>dna
<213>人工序列
<400>21
ggaaccaaggatatggttgttct23
<210>22
<211>23
<212>dna
<213>人工序列
<400>22
agaacaaccatatccttggttcc23
<210>23
<211>20
<212>dna
<213>人工序列
<400>23
ggagcacggatcagcttgca20
<210>24
<211>20
<212>dna
<213>人工序列
<400>24
tgcaagctgatccgtgctcc20
<210>25
<211>21
<212>dna
<213>人工序列
<400>25
gaagaagtaacacctagaact21
<210>26
<211>21
<212>dna
<213>人工序列
<400>26
agttctaggtgttacttcttc21
<210>27
<211>26
<212>dna
<213>人工序列
<400>27
atggagaagtccatgatcgagaagtc26
<210>28
<211>26
<212>dna
<213>人工序列
<400>28
ttatggcagctggaagaacatggagt26
<210>29
<211>18
<212>dna
<213>人工序列
<400>29
ctcaactatgtcaaggtt18
<210>30
<211>18
<212>dna
<213>人工序列
<400>30
aaccttgacatagttgag18
<210>31
<211>76
<212>dna
<213>人工序列
<400>31
ggttcctcccaccttttgacgagtttgaggtcgatcggtgccatcttccccagggagaat60
cagtggaatttcctgaag78
<210>32
<211>78
<212>dna
<213>人工序列
<400>32
cttcaggaaattccactgattctccctggggaagatggcaccgatcgacctcaaactcgt60
caaaaggtgggaggaacc78
<210>33
<211>18
<212>dna
<213>人工序列
<400>33
cttttcgtgcctgaaggt18
<210>34
<211>18
<212>dna
<213>人工序列
<400>34
accttcaggcacgaaaag18
<210>35
<211>25
<212>dna
<213>人工序列
<400>35
atggctgtcatgaagcctggtgtc25
<210>36
<211>27
<212>dna
<213>人工序列
<400>36
ttaggaagagaagaacagagccttaac27
<210>37
<211>22
<212>dna
<213>人工序列
<400>37
cagtgggcattgttggaggaac22
<210>38
<211>22
<212>dna
<213>人工序列
<400>38
ggttcctccaacaatgcccactg22
<210>39
<211>23
<212>dna
<213>人工序列
<400>39
gatatgctttgatgtttttcctc23
<210>40
<211>37
<212>dna
<213>人工序列
<400>40
gaggaaaaacatcaaagcatatc23
<210>41
<211>23
<212>dna
<213>人工序列
<400>41
atgaaggcactgattctggtcgg23
<210>42
<211>23
<212>dna
<213>人工序列
<400>42
ttacatgacgatctcaggcttct23
<210>43
<211>20
<212>dna
<213>人工序列
<400>43
tggattccataaatcccatg20
<210>44
<211>20
<212>dna
<213>人工序列
<400>44
catgggatttatggaatcca20
<210>45
<211>21
<212>dna
<213>人工序列
<400>45
tcggatcaagaagcttgcttg21
<210>46
<211>21
<212>dna
<213>人工序列
<400>46
caagcaagcttcttgatccga21
<210>47
<211>22
<212>dna
<213>人工序列
<400>47
atgggttctgctggtgagtctg22
<210>48
<211>23
<212>dna
<213>人工序列
<400>48
ttactccttaccatcagcagcac23
<210>49
<211>23
<212>dna
<213>人工序列
<400>49
gagttccatcttgtggatctcag23
<210>50
<211>23
<212>dna
<213>人工序列
<400>50
ctgagatccacaagatggaactc23
<210>51
<211>24
<212>dna
<213>人工序列
<400>51
ctgaagaaaggctctcacatccac24
<210>52
<211>24
<212>dna
<213>人工序列
<400>52
gtggatgtgagagcctttcttcag24
<210>53
<211>22
<212>dna
<213>人工序列
<400>53
atgatgctgaagatcaagcgtg22
<210>54
<211>23
<212>dna
<213>人工序列
<400>54
ttactggagaaccagacactcct23
<210>55
<211>21
<212>dna
<213>人工序列
<400>55
gcttgcagaaagggctatttc21
<210>56
<211>21
<212>dna
<213>人工序列
<400>56
gaaatagccctttctgcaagc21
<210>57
<211>22
<212>dna
<213>人工序列
<400>57
gaaaccttcttgcttgcacttc22
<210>58
<211>22
<212>dna
<213>人工序列
<400>58
gaagtgcaagcaagaaggtttc22
<210>59
<211>21
<212>dna
<213>人工序列
<400>59
caccacatgtccactaatttc21
<210>60
<211>21
<212>dna
<213>人工序列
<400>60
gaaattagtggacatgtggtg21
<210>61
<211>22
<212>dna
<213>人工序列
<400>61
gaggaaccagatgtcaatcctc22
<210>62
<211>22
<212>dna
<213>人工序列
<400>62
gaggattgacatctggttcctc22
<210>63
<211>44
<212>dna
<213>人工序列
<400>63
atggctgaaaatgattcgcttgctctgttcttggcctctgcagt44
<210>64
<211>21
<212>dna
<213>人工序列
<400>64
ttaggagtcctcgacaccaag21
<210>65
<211>22
<212>dna
<213>人工序列
<400>65
gagttcatatttaatcatctca22
<210>66
<211>22
<212>dna
<213>人工序列
<400>66
tgagatgattaaatatgaactc22
<210>67
<211>20
<212>dna
<213>人工序列
<400>67
gtggaacccctggatggcac20
<210>68
<211>20
<212>dna
<213>人工序列
<400>68
gtgccatccaggggttccac20
<210>69
<211>22
<212>dna
<213>人工序列
<400>69
atgactatccactactctgtcg22
<210>70
<211>23
<212>dna
<213>人工序列
<400>70
ttaggactgctggataccagaag23
<210>71
<211>22
<212>dna
<213>人工序列
<400>71
ctttaggaattttcacatatgt22
<210>72
<211>22
<212>dna
<213>人工序列
<400>72
acatatgtgaaaattcctaaag22
<210>73
<211>24
<212>dna
<213>人工序列
<400>73
atgcaacgagcactgactctgaag24
<210>74
<211>23
<212>dna
<213>人工序列
<400>74
ttagatggtgtcagaggatggga23
<210>75
<211>21
<212>dna
<213>人工序列
<400>75
gagttccacaccgtctctaac21
<210>76
<211>21
<212>dna
<213>人工序列
<400>76
gttagagacggtgtggaactc21
<210>77
<211>21
<212>dna
<213>人工序列
<400>77
gagctggagaaagtggtcaag21
<210>78
<211>21
<212>dna
<213>人工序列
<400>78
cttgaccactttctccagctc21
<210>79
<211>28
<212>dna
<213>人工序列
<400>79
gaactctgcaggttggtgcacatggtac28
<210>80
<211>28
<212>dna
<213>人工序列
<400>80
gtaccatgtgcaccaacctgcagagttc28
<210>81
<211>20
<212>dna
<213>人工序列
<400>81
agttctaaaacagctaatag20
<210>82
<211>20
<212>dna
<213>人工序列
<400>82
ctattagctgttttagaact20
<210>83
<211>22
<212>dna
<213>人工序列
<400>83
aaggttaaaggaggatgatata22
<210>84
<211>22
<212>dna
<213>人工序列
<400>84
tatatcatcctcctttaacctt22
<210>85
<211>25
<212>dna
<213>人工序列
<400>85
caaagaacagcttaccactctgaag25
<210>86
<211>25
<212>dna
<213>人工序列
<400>86
cttcagagtggtaagctgttctttg25
<210>87
<211>34
<212>dna
<213>人工序列
<400>87
atggctcttgaggttgctgccaaggctgctggag34
<210>88
<211>24
<212>dna
<213>人工序列
<400>88
ttacttaggattgaccttaggttc24
<210>89
<211>24
<212>dna
<213>人工序列
<400>89
gacattcctcaagagcaaggaacc24
<210>90
<211>24
<212>dna
<213>人工序列
<400>90
ggttccttgctcttgaggaatgtc24
<210>91
<211>24
<212>dna
<213>人工序列
<400>91
gtcactgctgctgatctaaccttg24
<210>92
<211>24
<212>dna
<213>人工序列
<400>92
caaggttagatcagcagcagtgac24
<210>93
<211>23
<212>dna
<213>人工序列
<400>93
ctaaaggtttgacccattaccat23
<210>94
<211>23
<212>dna
<213>人工序列
<400>94
atggtaatgggtcaaacctttag23
<210>95
<211>113
<212>dna
<213>人工序列
<400>95
gaattcctcgagcgatcccgcgaaattaatacgactcactataggggaattgtgagcgga60
taacaattcccctctagaaataattttgtttaactttaagaaggagatatacc113
<210>24
<211>78
<212>dna
<213>人工序列
<400>96
ctagcataaccccttggggcctctaaacgggtcttgaggggttttttggtcgacggtgac60
gttgagcatggtaagctt78
- 还没有人留言评论。精彩留言会获得点赞!