基于在线识别组装设备对象协议库的数据采集方法与流程
本发明涉及工业数据采集技术领域,特别涉及一种基于在线识别组装设备对象协议库的数据采集方法。
背景技术:
随着中国制造2025、互联网+以及工业4.0在全球的铺开,智能化已势不可挡,而工业数据的实时获取对智能化发展的影响极为重大。因此,在这种智能化的大环境下,工业数据的实施获取变得尤为重要,从环境监测到道路桥梁,从工厂生产到数据检验,都离不开工业数据的获取,这些工业数据与工业物联网的建设以及工业数据的采集是密不可分的。
由于工业数据的采集具有多样化、复杂化的特点,不同的生产厂家生产出的生产设备、通讯接口以及通讯协议各不相同,在实际应用中具有较为严重的缺陷:一是,由于软件系统以及设备通讯协议的不一致,在实际应用过程中,需要将分标准通讯协议转换为标准通讯协议,这就造成了系统通讯连接以及数据交换的成本增大,而且从设备安装实施到数据采集,整个过程复杂。二是,由于企业中一般存在不同领域的知识断层,导致工业数据采集系统不能被充分的使用,存在严重的资源浪费现象。
技术实现要素:
本发明的目的在于提供一种基于在线识别组装设备对象协议库的数据采集方法,以解决现有的工业数据采集过程复杂的问题。
为实现以上目的,本发明采用的技术方案为:提供一种在线识别组装设备对象协议放入数据采集方法,该方法包括:
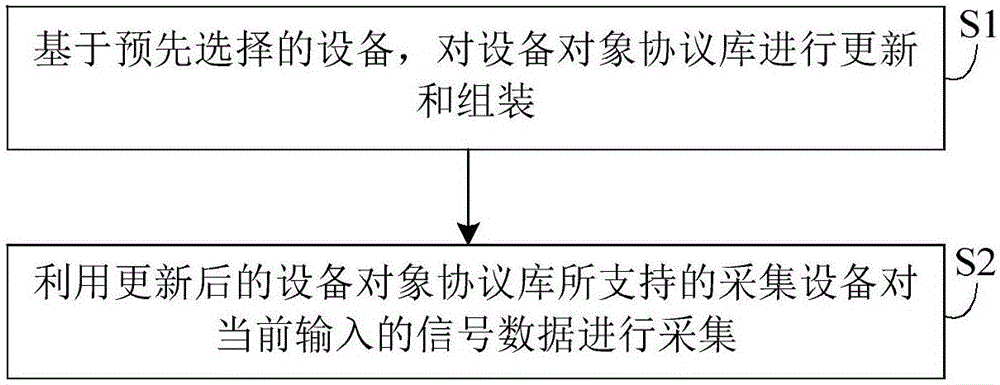
基于预先选择的设备,对设备对象协议库进行更新和组装;
利用更新后的设备对象协议库所支持的采集设备对当前输入的信号数据进行采集。
与现有技术相比,本发明存在以下技术效果:通过对当前采集设备的身份进行识别,在采集设备的身份识别成功时,采集设备将获取的设备对象协议库更新到本地库,并利用设备对象协议库中所支持的采集设备对传入的工业数据进行采集,减少了现场实施可配置的复杂度,大幅度的降低了行业用户采集工业数据的成本。
附图说明
图1是本发明一实施例中的基于在线识别组装设备对象协议库的数据采集方法的流程示意图;
图2是本发明一实施例中的步骤S1的细分步骤的流程示意图;
图3是本发明一实施例中的步骤S2的细分步骤的流程示意图;
图4是本发明一实施例中的设备对象协议库在线更新组装的原理图。
具体实施方式
下面结合图1至图4所示,对本发明做进一步详细叙述。
如图1所示,本实施例公开了一种基于在线识别设备对象协议库的数据采集方法,该方法包括如下步骤S1至S2:
S1、基于预先选择的设备,对设备对象协议库进行更新和组装;
S2、利用更新后的设备对象协议库所支持的采集设备对当前输入的信号数据进行采集。
具体地,本实施例实际上通过一种数据采集一体化程序对整个工业数据的采集过程进行控制,在实际应用中,通过获取预先选择设备的身份识别信息,并对设备的身份识别信息进行验证,在验证成功的情况下,该设备会获取设备对象协议库并更新到本地库中,在对工业数据进行采集时。因此,只要是设备对象协议库所支持的设备都可以对工业数据进行采集,整个采集过程的前提是该设备需要得到设备对象协议库的在线支持。整个实施过程简单,降低了设备配置的复杂性。
具体提,如图2、图4所示,步骤S1具体包括如下细分步骤S11至S12:
S11、基于预先选择的设备,对设备对象协议库进行在线更新;
S12、基于GCI模式,对更新后的设备对象协议库进行组装。
需要说明的是,本实施例中要求设备对象协议库符合GCI模式(Generic Callable Interface,GCI)。
具体地,步骤S11具体包括如下步骤:
获取预先选择设备得对象编码以及访问协议编码;
根据设备的对象编码以及访问协议编码,基于预设的算法函数生成采集设备的身份识别码;
通过设备对象协议库对设备的身份识别码进行校验,并在校验成功时提供设备获取设备对象协议库以更新到本地的权限。
具体地,对设备对象协议库进行在线更新的过程进行说明如下:
首先获取选择设备的对象编码DID以及访问协议编码PID,利用预设的算法函数f(DID,PID)生成该设备的身份证识别码ID,然后利用设备对象协议库对设备的身份证识别码ID进行校验,在校验成功时,允许该合法的设备将设备对象协议库更新到本地库中。
具体地,步骤S12具体包括如下步骤:
利用GCI模式中的设备对象协议库组件对类数组和算法组进行封装以形成统一调用接口;
利用宿主对象回调统一调用接口以实现所述更新后的设备对象协议库的组装。
需要说明的是,GCI模式由类属组、算法组、统一调度接口以及宿主对象四部分组成,由于本实施例中所说的设备对象协议库的设计符合GCI模式,因此,本实施例利用GCI模式对设备对象协议库进行在线组装。
具体地,如图3所示,步骤S2具体包括如下步骤S21至S23:
S21、对当前输入的信号数据进行解码;
S22、基于经验值瞬间校正法对解码后数据中的跳变量进行校正;
S23、通过所述预先选择的设备对校正后的解码数据进行采集。
需要说明的是,该处的跳变量是指与正常范围值相比较后发现突变、异常情况的值。而当出现跳变量时需要对跳变量进行校正,以保证信息的完整性和可靠性。因为如果不对跳变量进行处理,直接进行采集,那么该跳变值将会影响整个数据采集的正确性,如果将该跳变值忽略不进行采集,那么会影响数据采集的完整性。因此,本实施例中对跳变量进行校正可以保证数据采集的完整性和可靠性。
具体地,步骤S21包括:
判断输入的携带有数据信号的数据包是否完整;
如果数据包完整,则对完整的数据包进行解码处理;
如果数据包不完整,则对不完整的数据包进行修正处理。
需要说明的是,这里的数据包不完整一般包括两种情况:粘包和断包。粘包是指两个数据包粘在一起,断包是指一个数据包被分成两个数据包,如果对这两种数据包进行解码容易出现数据丢失现象,因此,需要对这两种情况的数据包进行修正,以保证解码后得到的数据时完整的。其中,针对粘包现象的修正过程是将两个粘在一起的数据分离开来,针对断包现象的修正过程是将同一个数据包断开的两部分或者多个部分合并在一起。
具体地,步骤S22具体包括如下步骤:
截取当前跳变量的跳变值以及跳变时间戳;
根据跳变时间戳获取预定时间段的经验值;
采用中值权法对经验值进行处理,得到经验值得权值;
根据经验值得权值,基于加权均值法对当前的跳变量进行校正。
其中,对采用经验值瞬间校正法对跳变量进行处理的具体过程说明如下:
当采集的信号数据出现跳变时,截取此时刻的跳变值Vt和时间戳T,将跳变值Vt与前述的正常范围值相比较,如果跳变值Vt在该正常范围内时,则不需要进行校正。如果不在该正常范围内,则判断该跳变值Vt需要进行校正。校正的过程如下:
(1)根据时间戳T获取一组特定时间段的经验值(T,T–n*To),To指的是向前时间偏移量,n指时间偏移量倍数,即Vn=V(T,T–n*To);
(2)采用中值法获取加权值,即对经验值Vn进行排序并获取中值序号队列(S1,…,Smid,…,Sn),即可通过算法βi∈(S1,…,Smid,Smid-1,…,Smid-n/2)获取权值;
(3)采用加权均值法进行计算:Vf=∑(Vi*βi)/∑βi,其中Vi∈(V1,Vn);Vf是校正得到的结果值。
具体地,本实施例公开的方法在步骤S21之前,还包括:
对当前输入的信号数据进行适配处理,以过滤掉不属于所述选择设备采集范畴的信号数据。
需要说明的是,本实施例中的当前输入的数据进行适配处理,避免对不属于该设备采集的数据进行采集,以避免浪费资源,降低设备的利用率。
具体地,本实施例中的步骤步骤S23包括:
获取空闲的数据库链接以及传输通道;
采集设备通过空闲的数据库链接以及传输通道将解码后的数据存入到本地数据库和/或上传至数据汇聚网关。
通过空闲的数据库链接以及传输通道,避免通过忙碌的传输通道进行数据传输导致数据无法传输的现象。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明的范围内。本发明要求的保护范围由所附的权利要求书及其等同物界定。
- 还没有人留言评论。精彩留言会获得点赞!