一种基于卷积对神经网络的图像去噪方法与流程
本发明涉及计算机视觉与数字图像处理领域,尤其涉及一种基于卷积对神经网络的图像去噪方法。
背景技术:
图像去噪,是计算机视觉和图像处理的一个经典且根本的问题,是解决很多相关问题的预处理必备过程,它的目的是从有噪声的图像y中恢复潜在的干净的图像x,该过程可表示为:y=x+n,其中,n通常被认为是加性高斯白噪声(Additive White Gaussian,AWG),这是一个典型的病态的线性的逆问题。为了解决这个问题,早期的很多方法都是通过局部滤波来解决的,譬如高斯滤波、中值滤波、双边滤波等,这些局部滤波方法既没有在全局范围内滤波,也没有考虑到自然图像块与块之间的联系性,因此获得的去噪效果不尽人意。
随着非局部自相似(Nonlocal Self-Similarity,NSS)概念的提出,更多的有效的去噪方法被提出。其中最早且最有影响力的方法是非局部均值(Nonlocal Means,NLM)去噪算法,它的主要思想是在一个全局范围内滑动的搜索框里寻找NSS块,通过欧氏距离来估计块与块之间的相关性,并用权重来表示,则图像块的每个像素值通过权重平均来计算。之后,将NSS引入变换域中,诞生了另外一个重要的方法叫三维块匹配(Block-matching and 3D filtering,BM3D)算法,先是建立一个3D的立方的NSS图像块,然后在稀疏的3D变换域中对图像块进行协同滤波。除了在变换域中建模,另外一种常用的去噪方法是求解低秩矩阵,其中有代表性的方法是加权核范数最小化(Weighted NuclearNorm Minimize,WNNM),它是利用NSS噪声图像块来求解决定核范数的权重,进而通过奇异值分解等步骤获得潜在的低秩矩阵,即为去噪后的干净图像。然而,低秩的过程并不能完全去除噪声,所以去噪效果并没有那么好;另外时间复杂度很高,并不适合实际需要实时去噪的场合。
技术实现要素:
为解决上述技术问题,本发明公开了一种基于卷积对神经网络的图像去噪方法,极大地增强神经网络的学习能力,建立起噪声图像到干净图像的准确映射,可以实现实时去噪。
为实现上述目的,本发明采用以下技术方案:
本发明公开了一种基于卷积对神经网络的图像去噪方法,包括以下步骤:
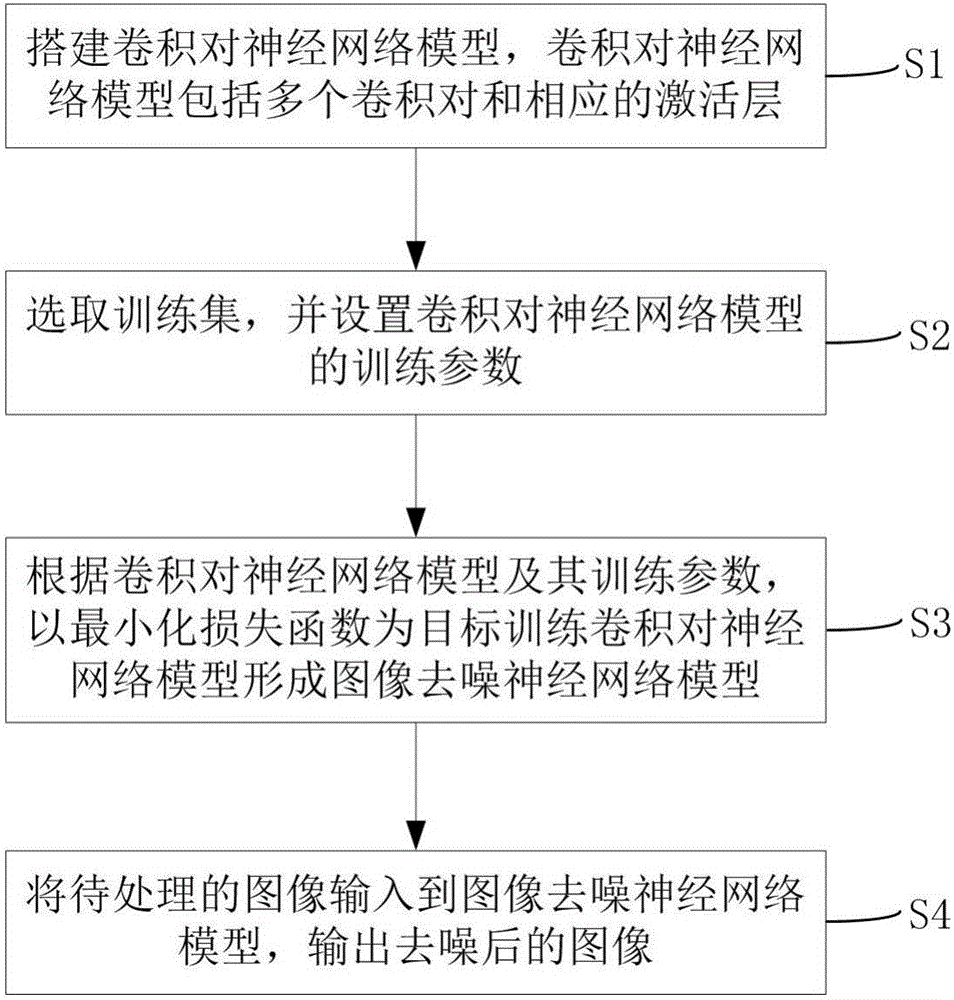
S1:搭建卷积对神经网络模型,所述卷积对神经网络模型包括多个卷积对和相应的激活层;
S2:选取训练集,并设置所述卷积对神经网络模型的训练参数;
S3:根据所述卷积对神经网络模型及其训练参数,以最小化损失函数为目标训练所述卷积对神经网络模型形成图像去噪神经网络模型;
S4:将待处理的图像输入到所述图像去噪神经网络模型,输出去噪后的图像。
优选地,步骤S1中的所述卷积对是由一个卷积核大于1×1的卷积层和一个卷积核为1×1的卷积层组成。
优选地,卷积核大于1×1的卷积层的卷积核大小为3×3、5×5、7×7、9×9或11×11。
优选地,步骤S1中搭建的所述卷积对神经网络模型中在多个所述卷积对后还添加一个1×1的卷积层和相应的激活层。
优选地,所述卷积对神经网络模型包括3个卷积对和一个1×1的卷积层、以及每个卷积层后相应的激活层,其中3个卷积对中的第一个卷积对由卷积核大小分别为11×11和1×1的两层卷积层组成,第二个卷积对和第三个卷积对均由卷积核大小分别为5×5和1×1的两层卷积层组成。
优选地,所述训练集包括多张噪声图像和相应的干净图像,步骤S2还包括:将所述噪声图像分割成38×38的噪声图像块,将所述干净图像分割成20×20的干净图像块。
优选地,步骤S3中的损失函数L(θ)为均方误差函数:
其中,MSE为均方误差,Xi、Yi分别为选取的所述训练集中的图像的噪声 图像块和干净图像块,θ表示权重;n表示图像块的个数;F函数表示训练出的噪声图像到干净图像的映射。
优选地,步骤S3中在训练所述卷积对神经网络模型过程中,所述卷积对神经网络模型的权重的初始值由高斯随机函数生成,最小化损失函数采用Adam优化方法。
优选地,步骤S3中的所述图像去噪神经网络模型是根据最小化损失函数获得的卷积层的权重来建立的。
优选地,步骤S2中所述训练集中选取包含多种噪声方差的多张图像,步骤S3中对多种噪声方差的多张图像分别训练所述卷积对神经网络模型形成多种对应的噪声方差下的所述图像去噪神经网络模型,步骤S4中将待处理的图像输入到相应的噪声方差下的所述图像去噪神经网络模型,输出去噪后的图像。
与现有技术相比,本发明的有益效果在于:本发明的图像去噪方法基于深度网络的学习,通过引入卷积对,极大地增强神经网络的学习能力,建立起噪声图像到干净图像的准确映射,可以实现实时去噪;将图像去噪过程分为模型训练过程和去噪过程,能够显著提高图像去噪的峰值信噪比(PSNR)和视觉效果,减少去噪时间,应用在图像处理方面的预处理过程和独立的图像去噪领域,能有效地提升图像去噪的效率和质量。
在进一步的方案中,本发明搭建的卷积对神经网络模型中的卷积对选用合适大小的卷积核的卷积层,使得不需要引入池化层就能够便于训练并有足够的能力获得很好的去噪效果,从而避免因为引入池化层使得参数减少而导致的模型不精确、效果变差等问题。
在更进一步的方案中,本发明针对多种不同的噪声方差训练卷积对神经网络模型形成对应的噪声方差下的图像去噪神经网络模型,并通过与待处理的图像相对应的噪声方差下的图像去噪神经网络模型对待处理的图像进行去噪,去噪速度快。
附图说明
图1是本发明优选实施例的基于卷积对神经网络的图像去噪方法的流程图;
图2是本发明优选实施例的卷积对神经网络模型的内部构造示意图。
具体实施方式
下面对照附图并结合优选的实施方式对本发明作进一步说明。
本发明的基于卷积对神经网络的图像去噪方法,通过引入卷积对的神经网络,引入卷积层和激活层,借助卷积层的学习能力和激活层的筛选能力获取好的特征,极大地增强神经网络的学习能力,准确地学习出从噪声图像到干净图像的映射以建立起输入到输出的映射,从而能够通过学习到的映射进行干净图像的预测和估计。
如图1所示,本发明的优选实施例的基于卷积对神经网络的图像去噪方法,包括以下步骤:
S1:搭建卷积对神经网络模型,所述卷积对神经网络模型包括多个卷积对和相应的激活层;
如图2所示,本发明优选实施例的卷积对神经网络模型包括3个卷积对、1个1×1的卷积层和每个卷积层后的激活层;每个卷积对可以由一个大于1×1的卷积层(卷积核的大小可以是3×3、5×5、7×7、9×9或11×11)和一个1×1的卷积层组成,在本实施例中,第一个卷积对由卷积核大小分别为11×11和1×1的两层卷积层组成,第二个和第三个卷积对都是由卷积核大小分别为5×5和1×1的两层卷积层组成。其中卷积核大小为11×11和5×5的卷积层有很好的提取特征的效果,参数不多使得计算量不大,方便实现;卷积核大小为1×1的卷积层在网络的最后可以增强提取的有效特征,从而增加网络的训练参数能力。其中,本实施例中每个卷积层后的激活层选用双曲正切函数(tanh函数)。
通过本发明优选实施例中建立的卷积对神经网络模型中选取的卷积层的总层数和卷积核大小,在保证神经网络的能力的基础上,避免了在训练过程中出现梯度爆炸、过拟合和计算复杂度等问题;使得在训练本发明优选实施例中的卷积对神经网络模型时,不需引入池化层,就能够便于训练并有足够的能力获得很好的去噪效果,从而避免因为引入池化层使得参数减少而导致的模型不精确、效果变差等问题。
S2:选取训练集,并设置卷积对神经网络模型的训练参数;
本发明优选实施例中选取在超分辨领域常用的高质量的91张图像作为训练集,每张图像分别有对应的噪声图像和干净图像。然后设置卷积对神经网络模型 的训练参数,包括每次输入模型训练的图像块数量、输入图像块和输出图像块的大小、图像深度、学习速率等。为增大数据集,将训练集中的每张图像对应的噪声图像和干净图像分别分割成同一分辨率的图像块;并设置padding为“VALID”(即通过卷积作用,图像的大小会根据卷积核的大小相应减小),假设卷积层的卷积核大小为M×M,图像大小为N×N,则经过一层该卷积层的图像大小变为(N-M+1)×(N-M+1);根据本优选实施例的卷积对神经网络模型,若选取输入噪声图像的大小为N×N,则对应的干净图像的大小为(N-18)×(N-18),增大数据集可以有效地避免训练过程中的过拟合现象。在本实施例中,将训练集中的噪声图像分割成38×38的噪声图像块,将干净图像分割成20×20的干净图像块,使得在训练模型时能够更好地捕捉图像的结构信息和细节信息;每次输入模型训练的图像块的数量为128;由于针对的是灰度图的去噪,图像深度设为1;学习速率设为0.001,每次训练时的衰减速率设为0.9;每训练2000次进行一次测试,观察目前模型的效果以更改模型的相关参数,当迭代大约10000次左右时,学习速率降为0。其中,在选取训练集的同时还可以选取测试集,测试集中可以选择去噪领域常用的10张图像,测试集中的每张图像也同样包含噪声图像和对应的干净图像,在对卷积对神经网络模型进行训练的过程中,可以采用测试集中的图像来对目前模型的效果进行观察。
S3:根据卷积对神经网络模型及其训练参数,以最小化损失函数为目标训练卷积对神经网络模型形成图像去噪神经网络模型;
其中损失函数L(θ)选为均方误差函数(MSE):
其中,MSE为均方误差,Xi、Yi分别为选取的所述训练集中的图像的噪声图像块和干净图像块,θ表示权重;n表示图像块的个数;F函数表示训练出的噪声图像到干净图像的映射;
由于峰值信噪比(PSNR)公式为:
其中,MAX通常是图像的灰度级,一般取255,由上式可以看出,不断最 小化损失函数(MSE)就可以获得高的峰值信噪比(PSNR)值,即图像的质量越高。在本实施例中,最小化损失函数采用Adam优化方法,其中Adam优化方法计算方式是,每时间步长迭代一次,计算一次平均梯度和平均梯度的平方根的衰减量(第一和第二动量估计),第一动量会随着时间不短衰减,由于第一和第二动量的初始值为0,则导致一些权重系数变为0;因此能够有效避免优化过程进入局部最优解,并且加快优化速度,来获得全局最优解。其中卷积对神经网络模型的权重θ的初始值由高斯随机函数生成,足够的随机性能够增强网络的鲁棒性。
根据最小化损失函数获得卷积层的权重,建立有效的图像去噪神经网络模型,该模型去噪速度快,对不同噪声方差下的图像去噪都有很强的鲁棒性,获得PSNR和视觉效果都很好。
S4:将待处理的图像输入到图像去噪神经网络模型,输出去噪后的图像。
在步骤S2中的训练集中可以选取包含多种噪声方差的多张图像,步骤S3中对多种噪声方差的多张图像分别训练卷积对神经网络模型形成多种对应的噪声方差下的图像去噪神经网络模型。步骤S4中将待处理的图像输入到与该图像相应的噪声方差下的图像去噪神经网络模型,即可预测出对应的干净图像,输出去噪后的图像。
在一个实例中,待处理的有噪声的图像的大小为512×512,输出预测的干净图像的大小为494×494,虽然图像大小有所变化,但对于整体来说影响很小,而图像质量提高很多。
在另一个实例中,在噪声方差为30的情况下,一张321×481的噪声图像的PSNR为18.59,经过图像去噪神经网络模型映射后,去噪后的干净图像的PSNR为30.80,极大地提高了图像的质量,视觉效果也令人满意。
根据本发明的图像去噪方法,可以提前训练好各种噪声方差下的图像去噪神经网络模型,图像去噪神经网络模型即是端对端直接由输入噪声图像到输出干净图像的映射,通过图像去噪神经网络模型对图像进行去噪的速度极快,不到0.1秒就获得干净图像,有很强的实用价值,在需要实时去噪的场合将会有广泛的应用。除了速度快、去噪效果好等优点,本发明还有很强的鲁棒性,针对不同的噪声水平和分辨率,去噪的时间和效果基本上没有变化。因此,本发明提供的卷积 对神经网络图像去噪方法的去噪效果好、速度快、鲁棒性强,有很强的实用性和实时性,市场前景广阔,尤其是对实时性要求很好的场合。
本发明优选实施例的图像去噪方法,通过引入卷积对层,极大地增强神经网络的学习能力,建立起噪声图像到干净图像的准确映射。卷积对中11×11和两个5×5的卷积层的效果很好,该大小的卷积核引入的参数不会很多,因此计算量不会很大,但是却能够提取到好的特征;卷积对中的1×1的卷积层实际上就是一个线性变换层,能够增强好的特征在网络中的作用。除了卷积层的引入,本发明还在每个卷积层后面增加了以tanh函数为激活函数的隐藏层。搭建起需要学习的卷积对神经网络模型后,通过不断减小损失函数的数值来训练网络模型的参数,损失函数选用均方误差函数,减小均方误差能够增大PSNR,从而提高图像的质量。对于不同的高斯噪声方差,训练卷积对神经网络模型形成对应的图像去噪神经网络模型以构造噪声图像到干净图像的映射,最终通过建立的有效映射对相应的噪声方差下的图像进行去噪处理,可以获得接近干净的图像。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干等同替代或明显变型,而且性能或用途相同,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!