一种基于自然语言分析技术的信息推送系统的制作方法
本发明涉及推荐引擎领域,尤其涉及一种基于自然语言分析技术的信息推送系统。
背景技术:
当今社会,每天生产大量的新闻资讯内容,并设置相对独特的原创图文、视频栏目,新闻编辑团队从中筛选出相对优质、热门的资讯内容推送给用户,或者,聚合第三方新闻平台的资源,根据用户的阅读行为记录来推送给用户个性化资讯内容,前者的推送方式缺点在于,推送规则单一,将优质、热门的资讯内容推送给每一个人必然是不能贴合用户需求的;后者的推送方式缺点在于,聚合第三方新闻平台的资源,聚合成本较高,且用户的阅读习惯受到该第三方新闻平台的限制,无法深入挖掘用户潜在兴趣。
互联网上各种信息掺杂,且更新速度非常快,需要投入大量的人力来进行编辑和筛选工作,运营成本非常高;对用户的阅读兴趣分析不够精准,推送给用户的资讯内容没有和用户需求相贴合,长此以往会导致用户阅读兴趣下降,用户量减少。
技术实现要素:
为克服现有技术的不足,本发明的目的是:提供一种基于自然语言分析技术的信息推送系统,通过算法对文章进行热度分析,在内容编选方面减少人工干预,对个性化推荐效果进行自我修正,提高推荐结果的准确度。
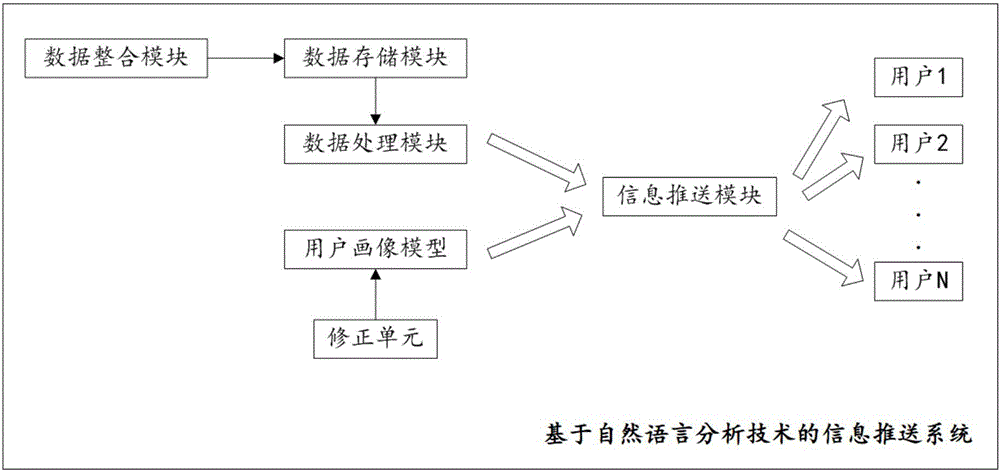
为了解决背景技术中的技术问题,本发明提供了一种基于自然语言分析技术的信息推送系统,包括以下模块:
数据整合模块,用于对全网资讯信息进行24小时不间断采集;
数据存储模块,用于将所述数据整合模块采集的资讯信息存储到数据库;
数据处理模块,用于对采集入库的数据进行正文抽取、聚类、去杂质、排版优化,并进行热度分析,组成专题;
用户画像模型,通过用户在客户端的行为和操作,建立起用户区分度模型,学习了解用户的阅读兴趣信息,进而对用户的阅读偏好进行预测;
信息推送模块,用于根据用户的阅读偏好,与数据库中的资讯内容进行智能化匹配,并将匹配中的信息推送给用户。
进一步地,所述用户画像模型还包括修正单元,用于跟进用户喜好的变化,修正用户的阅读偏好结果。
具体地,所述数据处理模块通过自然语言语义分类技术与关键词配置规则的结合,实现对信息的细化分析并分类。
本发明的基于自然语言分析技术的信息推送系统还包括接口模块,所述接口模块包括管理数据接口单元、应用系统数据接口单元和索引数据接口单元。
采用上述技术方案,本发明的基于自然语言分析技术的信息推送系统以资讯聚合客户端为载体,在整合优化全网资讯文章的基础上,通过算法语义分析,对文章进行正文抽取、聚类、去杂质、排版优化,并对文章热度进行分析,同时根据用户阅读行为建立每个用户的个人画像,然后针对不同用户画像里的兴趣、地域、收入等个人信息,建立起用户个性化推荐模型,再通过大数据、人工智能等手段,在尽可能短的时间内学习了解用户的兴趣偏好,并对用户的阅读喜好进行预测,最终有针对性的推送出与用户阅读偏好相匹配的的优质资讯信息。从而达到既大大减少人力成本,又能根据用户需求来推送资讯信息的目的。
附图说明
为了更清楚地说明本发明的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
图1是本发明实施例提供的基于自然语言分析技术的信息推送系统的系统框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例:图1是本发明实施例提供的基于自然语言分析技术的信息推送系统的系统框图,从图中可以看出,所述基于自然语言分析技术的信息推送系统包括以下模块:
数据整合模块,用于对全网资讯信息进行24小时不间断采集;
数据存储模块,用于将所述数据整合模块采集的资讯信息存储到数据库;
数据处理模块,用于对采集入库的数据进行正文抽取、聚类、去杂质、排版优化,并进行热度分析,组成专题;
用户画像模型,通过用户在客户端的行为和操作,建立起用户区分度模型,学习了解用户的阅读兴趣信息,进而对用户的阅读偏好进行预测;
信息推送模块,用于根据用户的阅读偏好,与数据库中的资讯内容进行智能化匹配,并将匹配中的信息推送给用户。
进一步地,所述用户画像模型还包括修正单元,用于跟进用户喜好的变化,修正用户的阅读偏好结果。
具体地,所述数据处理模块通过自然语言语义分类技术与关键词配置规则的结合,实现对信息的细化分析并分类。
本实施例提供的基于自然语言分析技术的信息推送系统还包括接口模块,所述接口模块包括管理数据接口单元、应用系统数据接口单元和索引数据接口单元。
本发明涉及一种基于自然语言智能分析处理的推荐引擎技术。首先,数据后台会24小时不间断采集全网数据,并对采来的数据进行正文抽取、聚类、去杂质、排版优化、热度分析等智能分析处理,经过优化处理后的数据会进入备用内容库。当用户打开客户端后,后台会根据用户的一系列阅读行为和操作建立起不同的用户画像,并持续进行自我修正:本发明以最短的学习时间,对用户的阅读偏好进行学习预测,并会持续的对用户行为进行分析,及时跟进用户喜好的变化,提高资讯推荐的准确程度,最终根据用户画像中记录的用户信息来从内容库中匹配用户可能感兴趣的资讯信息,有针对性的推送给用户。
本发明针对现有的人工编辑推荐运营成本大以及个性化推荐质量不高的问题,在整合全网资讯内容的基础上,通过算法语义分析,对文章进行正文抽取、聚类、去杂质、排版优化,并对文章热度进行分析,组建专题,无需像现在的媒体那样安排大量编辑对内容进行人工编选,既保证了内容的质量,又减少了人工运营成本,然后再将算法处理过的文章与大数据分析得出的用户阅读偏好相匹配,推送给用户感兴趣的文章。
以上所揭露的仅为本发明的几种较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!