一种图像匹配点对筛选方法与流程
本发明涉及计算机视觉技术领域,特别是指一种图像匹配点对筛选方法。
背景技术:
在计算机视觉领域,对模型进行鲁棒性估计有着十分重要的意义。模型的鲁棒性估计是指在包含异常值的数据集中计算模型参数,主要应用于运动估计、三维重建、目标识别与跟踪,以及图像拼接等方面。例如,对于图像拼接,一般是先找到两个图像之间的匹配点对,然后对由所有匹配点对所构成的数据集进行鲁棒性估计,从而剔除偏差较大的外点,保留符合模型的内点。
在众多模型估计算法中,fishler等在1981年引入的ransac(randomsampleconsensus,随机抽样一致)算法以其良好的操作性和强大的鲁棒性,成为计算机领域应用最广的模型估计方法。
ransac算法能够在有大量外点(即不符合模型的点)的数据中找到正确模型,但是在外点数量较多或者模型复杂的情况下,会导致计算量非常大。近年来,为了提高ransac算法的效率及性能,研究人员在这方面做了很多工作。一种途径是对采用预检验的方法,将得到的模型先在小部分数据上而不是所有数据上进行检验,只有当模型通过预检验时才进入下一步骤。比较经典有chumo提出的基于td,d测试的randomizedransac算法,该算法先对得到模型进行td,d测试,通过则计算所有数据点的误差,否则重新采样。陈付幸等在此基础上进行改进并提出了tc,d测试算法,优化了预处理模型。但是,这类方法的优越性依赖于预判条件的设置,若正确模型通过预检验的概率较低,则会比ransac算法需要更多的迭代。另一种途径是对数据采样模式进行改进,根据先验知识对样本进行有区别的采样,比较有代表性的是chumo提出的prosac(progressivesampleconsensus)算法,这种算法根据先验概率对匹配点进行排序,抽取最高概率的最小子集,但是该方法过度依赖于先验知识,在实际操作中,获得完全正确的先验知识往往非常困难,而且误差的存在也会导致额外的运算。
技术实现要素:
有鉴于此,本发明的目的在于提出一种图像匹配点对筛选方法,该方法能够简化模型构建的过程,提高匹配点对筛选的效率和精度。
基于上述目的,本发明提供的技术方案是:
一种图像匹配点对筛选方法,其应用于由两个图像间的匹配点对所组成的样本集,样本集中的每一个样本点表示一个匹配点对,该方法包括以下步骤:
(1)根据匹配点对的特征距离为样本集中的每一个样本点赋予先验概率;
(2)从样本集中逐次获取内点集,将当次所得内点集与前次所得的最大内点集相比较,直至某次所得内点集在紧随其后的连续m次比较中均为最大内点集,以此内点集为第一极大内点集;
(3)再次从样本集中逐次获取内点集,将当次所得内点集与已有的最大内点集相比较,直至某次所得内点集在紧随其后的连续n次比较中均为最大内点集,以此内点集为第二极大内点集;至此,第二极大内点集中的样本点所表示的匹配点对即为两个图形间的有效匹配点对;
上述步骤中,所述最大内点集是指元素个数最多的内点集;
步骤(2)中每个内点集的获取方式为:
(201)根据预设模型对样本点个数的要求,依先验概率从样本集中抽取若干样本点,构成一个用于求解预设模型具体参数的最小子集;
(202)由步骤(201)中的最小子集求解出预设模型的一组具体参数;
(203)用由步骤(202)中的具体参数所确定的预设模型对样本集中的所有样本点进行逐个校验,得到符合模型的内点集;
步骤(3)中每个内点集的获取方式为:
(301)根据预设模型对样本点个数的要求,从当次已有的最大内点集中以等概率方式选取一个用于求解预设模型具体参数的最小子集;
(302)由步骤(301)中的最小子集求解出预设模型的一组具体参数;
(303)用由步骤(302)中的具体参数所确定的预设模型对样本集中的所有样本点进行逐个校验,得到符合模型的内点集。
可选地,特征距离为匹配点对中两点的相关性系数,先验概率为特征距离的倒数的归一化值。
可选地,m的取值范围为28~32;n的取值范围为57~63。
从上面的叙述可以看出,本发明的特点及有益效果在于:
1、现有技术通常是在得到样本点的先验概率之后直接选取先验概率最高的若干样本点构成最小子集,这样,算法会过度依赖于先验概率,即,对先验知识准确性的要求极高。而在实际工作中,要获得准确的先验概率往往是困难的,因此,现有技术的做法很有可能会在最小子集中包含误差较大的样本点,这时,去除这些样本点就需要更多的运算次数,使运算效率低于原始ransac算法的效率。有鉴于此,本发明方法不直接选取先验概率最高的前几个样本点作为最小子集,而是从整个样本集中进行多次随机抽取,每次抽取中,每个样本点被抽到的概率由其先验概率决定,这样,先验概率高的点有较大的可能被抽取,先验概率低的点则以较小的可能被抽取。可见,本发明方法降低了对先验概率的依赖程度,平衡了错误的先验概率对算法的影响,从而在提高算法的效率的同时,保证了算法的稳定性。
2、现有技术中的ransac算法认为每次采样-检验之间是独立的,上一次的计算结果对以后的检验没有影响。事实上,在没有任何误差的情况下,样本集中只有一个正确模型以及该模型所对应的内点集,所有用从该内点集中选择的最小子集所估计得到的模型就是该模型。基于这一思想,发明人发现,即使在样本集存在误差的情况下,一旦找到正确模型,也可以让新的采样只在该正确模型所对应的内点集中进行,这样可使找到正确模型的概率大大提高,从而使样本采样和模型更新进入一个良性循环,提高获取正确模型概率,减少迭代次数,提前得到最优模型。
总之,本发明方法在考虑先验知识对采样模式的影响的同时,还引入了检验结果对采样的约束,从而简化了构建模型的迭代步骤,提高了获取正确模型的效率。实验证明,本发明方法的运行效率和精度相较于现有技术都有较大提高。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
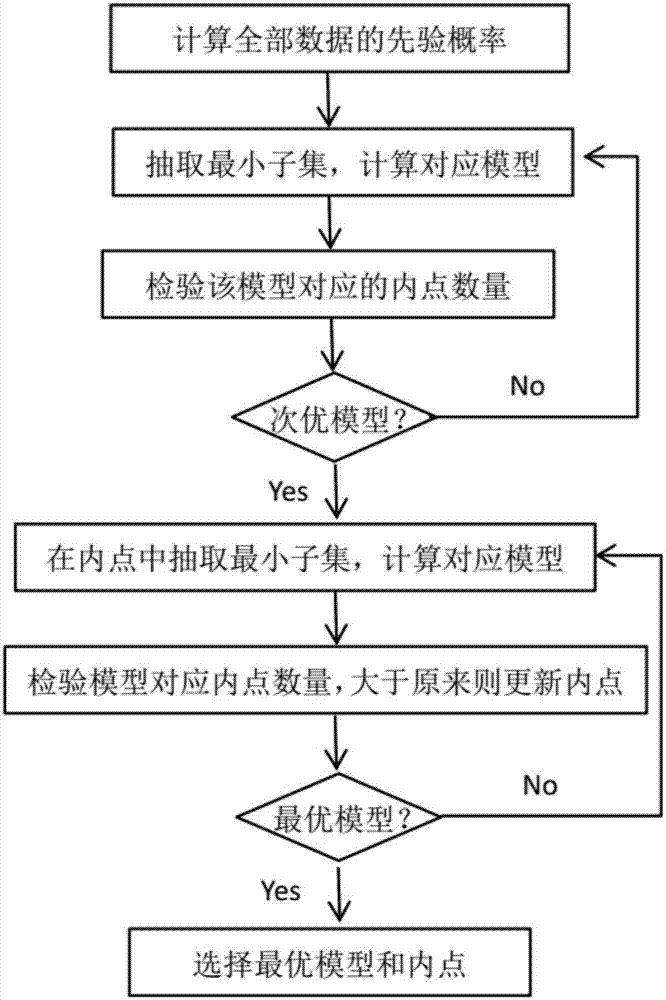
图1为本发明实施例的一个方法流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明做进一步的详细说明。
一种图像匹配点对筛选方法,其应用于由两个图像间的匹配点对所组成的样本集,样本集中的每一个样本点表示一个匹配点对,该方法包括以下步骤:
(1)根据匹配点对的特征距离为样本集中的每一个样本点赋予先验概率;
(2)从样本集中逐次获取内点集,将当次所得内点集与前次所得的最大内点集相比较,直至某次所得内点集在紧随其后的连续m次比较中均为最大内点集,以此内点集为第一极大内点集;
(3)再次从样本集中逐次获取内点集,将当次所得内点集与已有的最大内点集相比较,直至某次所得内点集在紧随其后的连续n次比较中均为最大内点集,以此内点集为第二极大内点集;至此,第二极大内点集中的样本点所表示的匹配点对即为两个图形间的有效匹配点对;
上述步骤中,最大内点集是指元素个数最多的内点集;
步骤(2)中每个内点集的获取方式为:
(201)根据预设模型对样本点个数的要求,依先验概率从样本集中抽取若干样本点,构成一个用于求解预设模型具体参数的最小子集;
(202)由步骤(201)中的最小子集求解出预设模型的一组具体参数;
(203)用由步骤(202)中的具体参数所确定的预设模型对样本集中的所有样本点进行逐个校验,得到符合模型的内点集;
步骤(3)中每个内点集的获取方式为:
(301)根据预设模型对样本点个数的要求,从当次已有的最大内点集中以等概率方式选取一个用于求解预设模型具体参数的最小子集;
(302)由步骤(301)中的最小子集求解出预设模型的一组具体参数;
(303)用由步骤(302)中的具体参数所确定的预设模型对样本集中的所有样本点进行逐个校验,得到符合模型的内点集。
本实施例方法步骤(2)基于先验概率得到一个次优模型,接下来步骤(3)所用最小子集的采样不在整个样本集中进行,而是在此次优模型对应的内点集(即第一极大内点集)中进行,并且,如果找到对应内点个数更多的模型,则更新之前得到的最大内点集,并在新的最大内点集中进行最小子集的采样,否则仍在原内点集中采样。如此直到最大内点集在指定次数内不再更新,则认为找到最优模型。
事实上,得到的次优模型只有两种可能,即模型正确(即用于模型估计的最小子集中不含外点)或模型错误。假设次优模型是正确模型,那么基于内点的采样使迭代在正确样本点和正确模型之间进行,在很多正确模型中可以很快找到最优模型;假设次优模型是错误模型,基于内点的采样仍然会得到错误模型,但是基于全部数据的采样和基于内点的采样得到错误模型的概率是相同的,而迭代一旦开始找到正确模型后,就可以进入优化迭代。也就是说,即使在最坏的情况下,本算法也不会比ransac算法采样次数多。
具体地,上述方法中的特征距离可以采用匹配点对中两点的相关性系数来表征,这样,每个样本点的先验概率则可采用特征距离的倒数的归一化值来表示。假设样本集中共有n个样本点,某一样本点k所表示的匹配点对中两点的相关性系数为d(k),则样本点k的先验概率为:
通过实验,上述方法中的m取28~32,n取57~63时可以取得很好的执行效率。
图1所示为一种迭代执行的图像匹配点对筛选方法,其包含以下步骤:
(s001)计算样本集中的每一个样本点的先验概率;
(s002)从样本集中抽取一个最小子集,计算对应的模型;
(s003)以步骤(s002)所得的模型在样本集中校验内点,得到内点集及内点数量;
(s004)重复(s002)至(s003),直到第t次所得内点集在t+30次循环中均为最大内点集,以第t次所得内点集为第一极大内点集,至此得到次优模型;
(s005)在当前已有的最大内点集中抽取最小子集,计算对应的模型;
(s006)以步骤(s005)所得的模型在样本集中校验内点,得到内点集及内点数量;
(s007)重复(s005)至(s006),直到第k次所得内点集在k+60次循环中均为最大内点集,以第k次所得内点集为第二极大内点集,至此得到最优模型;
(s008)第二极大内点集中的样本点所表示的匹配点对即为两个图形间的有效匹配点对。
需要说明的是,步骤(s007)中第一次循环所得到的内点集需要与第一极大内点集比较,即,第二极大内点集必定不小于第一极大内点集。
本领域的技术人员需要理解,本发明中所谓的内点集的大小是指两个内点集所含元素个数的多少,并非是指集合间的包含关系。
针对牛津大学可视几何图形组中的graffiti和wall图像(网址:http://www.robots.ox.ac.uk/~vgg/data/data-aff.html),使用本实施例方法及ransac算法分别进行内点选取,得到的对比实验数据如下表1所示:
表1不同图像ransac算法与本文算法对比
其中,针对wall图像,不同内点比例下本实施例方法及ransac算法的实验对比如下表2所示:
表2不同内点比例ransac算法与本文算法对比(wall)
可见,本实施例方法确实具有更好的精确度和运行效率。
总之,本发明方法按照抽取、估计、检验的思路进行内点筛选,着重对抽取方式进行优化改进。本发明方法在考虑先验知识对采样模式的影响的同时,还引入了检验结果对采样的约束,从而简化了构建模型的迭代步骤,提高了获取正确模型的效率。实验证明,本发明方法的运行效率和精度相较于现有技术都有较大提高。
所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本公开的范围(包括权利要求)被限于这些例子。凡在本发明的精神和原则之内,对以上实施例所做的任何省略、修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!