基于多种智能算法的车辆路径规划仿真实验平台的制作方法
本发明涉及路径规划领域,尤其涉及基于多种智能算法的车辆路径规划仿真实验平台。
背景技术:
随着经济全球化的到来,制造业、零售业和电子商务催生了现代物流的快速发展。现代物流信息技术广泛应用,管理信息系统、物流信息平台、物流配送系统的建设快速推进。车辆路径规划是城市物流配送的重要环节,也是物流配送信息系统建立的基础和重要模块。
物流配送中心往往面临着各种货运车辆资源的约束,一个实际的约束是具有有限的多种车型,每种车型的车辆数固定和每种类型的车辆的容量限制,该问题是典型的具有固定车辆数的多车型车辆路径问题(heterogeneousfixedfleetvehicleroutingproblem,hffvrp),而如何在物流配送中经济合理的安排车辆路径,对于发展低成本、高效率的物流产业至关重要。
蚁群算法由marcodorigo于1992年在他的博士论文中提出。蚁群算法是一个分布式的多agent系统,它在问题空间的多点同时开始进行独立的解搜索,不仅增加了算法的可靠性,也使得算法具有较强的全局搜索能力。该算法现已被大量应用于数据分析、机器人协作问题求解、电力、通信、水利、采矿、化工、建筑、交通等领域。但该算法收敛速度慢、易陷入局部最优。
k-means聚类算法由j.b,macqueen1967年提出的。k-means聚类算法快速、简单,对大数据集有较高的效率并且是可伸缩性的,时间复杂度近于线性,而且适合挖掘大规模数据集。该算法是数据挖掘的重要分支,同时也是实际应用中最常用的聚类算法之一。但该算法对初始聚类中心的选取具有极大的依赖性使算法常陷入局部最小解,对噪声和孤立点数据敏感。
遗传算法由美国的j.holland教授1975年首先提出。遗传算法是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力,采用概率化的寻优方法,能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则。该算法已被人们广泛地应用于组合优化、机器学习、信号处理、自适应控制和人工生命等领域。但该算法在适应度函数选择不当的情况下有可能收敛于局部最优,而不能达到全局最优。
退火算法由n.metropolis等人于1953年提出。退火算法计算过程简单,通用,鲁棒性强,适用于并行处理,可用于求解复杂的非线性优化问题。该算法的应用很广泛,可以较高的效率求解最大截问题、0-1背包问题、图着色问题、调度问题等。但该算法收敛速度慢,执行时间长,算法性能与初始值有关且参数敏感。
技术实现要素:
鉴于以上算法各有不足,本发明提供一种基于多种智能算法的车辆路径规划仿真实验平台,以解决现有技术路径规划复杂的技术问题。
一种基于多种智能算法的车辆路径规划仿真实验平台,该平台包括数据生成单元、智能算法单元、数据输出单元和仿真运行单元;所述数据生成单元确定仿真平台运行的具体输入数据;智能算法单元指定用于计算最优路径的算法;数据输出单元将智能算法计算得到的最优路径的具体数据输出,并发送到用户邮箱,同时存储每一次的计算结果;仿真运行单元将得到的输出数据进行动画演示。
所述数据生成单元包括:选择数据模块、坐标生成模块和测试数据下载模块;所述选择数据模块选择平台提供的默认数据或通过自行填写数据,然后在所述坐标生成模块生成对应的坐标图;所述测试数据下载模块供用户下载json格式的输入数据进行查看。
所述智能算法单元中的算法包括内置算法和自定义算法。所述内置算法包括:改进的遗传退火算法、改进的蚁群算法和基于有限状态机的聚类随机算法.
所述数据输出单元包括:计算最短路径模块、发送邮件模块和数据存储模块;所述计算最短路径模块计算出本次输入数据的最优路径;所述发送邮件模块在智能算法计算出最优路径的结果后将数据发送到用户邮箱并提供观看仿真动画演示的链接;所述数据存储模块将每一次的输入数据、所用智能算法和最优路径计算结果存储进数据库并在前端展示。
所述仿真运行单元包括动画演示模块和路径图展示模块;所述动画演示模块根据得到的输出数据进行车辆调度物资的仿真实验,显示供应地与需求地物资的减少与增加的数量,用虚线标明当前运行路径,并在演示结束时显示本次车辆路径规划的最短路径和最短路径的计算时间;所述路径图展示模块显示每一辆车的运行路径以及在动画演示过程中的当前运行路径。
所述填写数据包括:供应地数量和拥有物资数量、需求地数量和所需物资数量、车辆数量和每辆车的运载量。
所述计算最优路径包括:获取输入数据、计算最优路径和生成输出数据文件;
所述获取输入数据包括数据生成单元生成的具体数据、选择的智能算法、运行次数和用户邮箱;所述计算最优路径根据指定的算法与运行次数来计算出最优解、最短路径平均值和运行时间平均值;所述生成输出数据文件会将每辆车的路径以json格式生成一个文本文件,并将数据传回前端以供动画演示。
所述发送邮件包括:数据量、最短路径的平均值、最优解、最优解出现的次数、本次数据运行的次数、平均运行时间和提供动画演示的链接。
本发明可用于进行各种车辆规划路径的仿真运算,仿真程度高,成本低。
附图说明
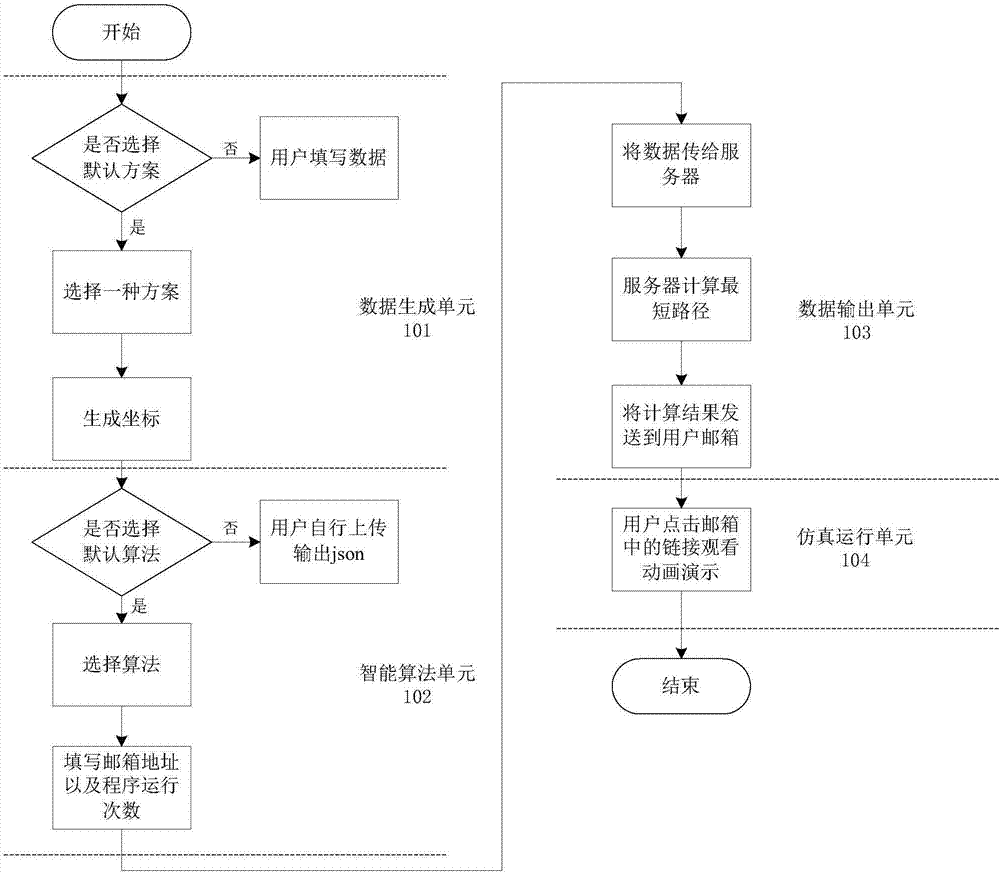
图1为本发明实施例车辆路径规划仿真实验平台运行流程图;
图2为蚁群算法流程图;
图3为蚁群算法的蚁群觅食示意图;
图4为蚁群算法的算法示意图;
图5为蚁群算法的仿真示意图;
图6为k-means聚类算法流程图;
图7为遗传退火算法的第一条染色体示意图;
图8为遗传退火算法的不可行解的判断流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1所示为本发明实施例提供的车辆路径规划仿真实验平台的结构流程图,所述平台包括:数据生成单元101、智能算法单元102、数据输出单元103和仿真运行单元104。
数据生成单元101又包括选择数据模块、坐标生成模块和测试数据下载模块,所述选择数据模块提供了7种默认数据供选择,也可自定义数据,然后坐标生成模块根据选择的数据在网格图中生成相应的坐标图,所述测试数据下载模块可下载json格式的完整输入数据。
每一种默认数据包括供应地数量、需求地数量和车辆数量,默认数据包括332、553、884、10105、202010、252515、303020,自定义数据需指定供应地、需求地和车辆的数量,每个供应地的初始物资数量、每个需求地的物资需求量和每辆车的运载量可由平台自动生成,也可由用户指定。
智能算法单元102又包括选择内置算法模块和上传算法模块,所述选择内置算法模块包括遗传退火算法、蚁群算法和k-means聚类算法三种算法,所述上传算法模块可以上传与内置算法不同的其他算法。
如图2所示为本发明实施例提供的蚁群算法流程图,所述方法包括以下步骤:
前提假设:
(1)救援物资只有一种。
(2)所有供应地的供应量之和大于等于所有需求地的需求量之和。
(3)不同卡车运载量可以不同。
(4)所有卡车速度都为1,即卡车所走路长与花费时间在数值上相等。
(5)卡车初始位置任意,救援完成后不需返回原位置。
(6)卡车可多次出发救援,任何一个供应地、需求地可被多次访问。
(7)目标为要用最少的时间来完成物资调度任务。
此外,为了叙述方便,下文中物资的装运以及物资的卸载分别用装货和卸货表示。
数学模型:
符号定义如下:物资种类数量为a,供应地数量为m,需求地数量为n,卡车数量为k,设第m个供应地的总物资量为sm,当前物资量为sm,第n个需求地的需求量为dn,当前需求量为dn;第k辆卡车的速度为bk,当前运载量为fk,最大运载量为gk,从第m个供应地装货量为zkm,在第n个需求地卸货量为xkn,从开始行动到完成任务停止的时间为tk,全部调度任务完成时间为t。
目标函数与约束条件为:
t=maxktk(1)
a=1(2)
bk=1(4)
hk≤fk≤gk(5)
zkm<min{gk,sm)(6)
xkn<min{fk,dn}(7)
(1)式是目标函数,表示全部调度任务完成的标志是所有卡车都停止;
(2)式表示物资种类只有1种;
(3)式表示所有供应地的供应量之和大于等于所有需求地的需求量之和;
(4)式表示所有卡车速度均为1;
(5)式表示第k辆卡车卸货量小于等于当前运载量,当前运载量小于等于卡车的最大运载量;
(6)式表示第k辆卡车从第m个供应地装货的量应小于最大装货量和该供应地的当前物资量中的较小者;
(7)式表示第k辆卡车在第n个需求地卸货的量为卡车当前运载量和该需求地当前需求量中的较小者。
算法思想及步骤:
蚁群在觅食时,虽然个体的行动规则简单,但个体与个体通过信息素(一种自身释放的化学物质)的交流,经过一定时间就可以找到一条从蚁巢通往食物的最短路径。如图3所示,食物在右方,蚂蚁通向食物的路有2条,开始时蚂蚁会随机的选择路线1或路线2,但是当经过一段时间后,路长较短的线路1上残留的信息素浓度会高于路线2,后面的蚂蚁在选择路线时,会优先选择信息素浓度高的路线。经过一定的时间,就会出现大量蚂蚁往返于线路1的现象。本文将每辆卡车都看作一个蚁群系统,大量蚂蚁从卡车位置出发去寻找下一个目标地点,通过环境信息素的累积,经过一定时间就可以得到卡车的最优路径。所以每一辆卡车作为一个蚁群系统,拥有属于自己的“食物”,也就是自己负责的需求地,那么我们就需要找到一个合适的“食物”分配方法。
算法的核心思想可以分为如下三步:
(1)在将总问题的所有任务划分为k个单车子任务,其中每个子问题包含一辆卡车以及多个需求地,卡车可以到任意的供应地装运物资并送往由它负责的需求地,子问题被解决的标志为该卡车所负责的需求地的需求全部得到满足。
(2)是给划分好的k个单车子任务规定一个执行序列。由于各个卡车实际行动是并发的,且卡车可以到任意的供应地装运物资,所以各个卡车也就是各个蚁群系统之间存在一定的影响,对于相同的子任务划分来说,不同的计算序列会影响最终的结果。
(3)是用蚁群算法来执行每个子任务。根据问题模型,规定好蚂蚁的行动规则,设置蚂蚁的数量,以距离作为期望因子,信息素量作为启发因子,建立距离矩阵与信息素矩阵,并设置信息素矩阵的更新方式,通过蚂蚁来模拟执行任务,得到卡车完成该子任务所走的最优路径,并计算出花费时间。
其中第一步需要循环执行u次,在每一次的执行过程中判断是否需要剪枝;若第一步产生的子任务划分没有被剪枝的话,就在此基础上循环执行第二步v次,在该过程中使用禁忌表来避免重复计算;若第二步产生的序列不在禁忌表中,则在此基础上执行第三步,得到tu,v并记录下来。最后取耗时最少的一次作为第k辆卡车所花费的时间。即:
tk=minu,vtu,v(8)
算法核心思想如图4所示。
子任务的划分以及确定子任务的执行序列:
对于第u次子任务划分下的第v条子任务序列来说,我们需要求解出tu,v,若tu,v。所以本文在这里采取这样的方法:随机生成u个子任务划分,对于每个子任务划分,再随机生成v个子任务序列,然后通过蚁群算法计算出在此次子任务划分和子任务序列下的最终结果,取最优的子任务划分以及子任务执行序列最为最终的方案。
该过程的算法文字描述如下:
(1)初始化u=0,v=0,定义t为无穷大。
(2)u=u+1,随机产生第u次的子任务划分。
(3)v=v+1,在第u次的子任务划分下随机产生第v条子任务序列。
(4)用蚁群算法求解得到tu,v。
(5)若tu,v<t,则t=tu,v。
(6)若v≤v,转(3)。
(7)若u≤u转(2)。
(8)结束。
为了提高搜索效率,我们加入了分支定界法和禁忌搜索的思想。
在进行子任务划分时,可能会出现非常差的划分方案,而本文未改进前的算法会对此次划分情况进行不同子任务序列的计算,这就造成了大量计算时间的浪费,由于子任务划分的循环需要达到一定规模才会有较好的结果,所以如果在非最优解的子任务划分上浪费时间的话,整个算法耗时会非常长。所以本文采用分支定界法的思想,在对每个子任务划分方案进行求解时,会根据剪枝函数来判断是否需要计算该次的子任务划分。先根据该方案的序列1求解,若结果明显比当前最优解差(路长为当前最优解的2倍以上),则跳过对该子任务划分方案的计算。通过加入分支定界法的思想,可以避免大量的无意义的计算,提高搜索效率。
在确定子任务的执行序列过程中,可能会重复出现某些子任务序列。本文加入禁忌搜索的思想,将已计算过的序列添加到禁忌表中来避免重复计算。
蚁群算法解决单车子问题
蚁群算法关键是根据信息素矩阵和启发信息矩阵生成可行解以及信息素矩阵的更新。由前文可知,子任务目标为满足所有所属需求地的需求并且路长最小,所以采用地点间的距离作为启发信息。对于蚁群信息素的更新,我们采用分组更新的方式,即每组蚂蚁运行后更新一次信息素。设储存最优路径的蚂蚁为bestant,称为最优蚂蚁。
新建一组蚂蚁模型来模拟小车在复制的城市模型上完成调度任务,并且记录这一组中的最优蚂蚁,根据最优蚂蚁的结果判断是否需要更新bestant。在一组蚂蚁模拟任务完成后,更新信息素矩阵。我们定义maxphrm为标准的信息素量,length为蚂蚁走过的路长,phrm为原信息素量,newphrm为新留下来的信息素,ρ为信息素衰减因子。由于蚂蚁走过路程越长,留下的信息素会越少,所以newphrm=maxphrm/length,信息素矩阵的更新公式为phrm=phrm*ρ+newphrm。以下为算法流程描述:
(1)初始化蚂蚁组数q=0,蚂蚁数量p=0
(2)新建一只蚂蚁,p=p+1
(3)根据卡车初始化该蚂蚁的信息(位置,运载量)
(4)复制城市模型,让该蚂蚁在复制模型上模拟卡车完成调度任务
(5)根据该蚂蚁的路长判断是否更新bestant
(6)若p<p,转(3)
(7)更新信息素矩阵。
(8)若q<q,转(2)
(9)结束
上述流程的步骤(4)即蚂蚁模拟卡车进行物资调度的过程如下:首先判断蚂蚁下一步去供应地还是需求地。若蚂蚁此时没有货物,则下一步去供应地装货;若蚂蚁此时仍有货物,则下一步去需求地卸货。选择目的地则是用轮盘赌的方法,根据信息素矩阵和启发信息矩阵,来计算去到每个地点的概率,并选出目的地,完成装货或者卸货。装货时,在子任务中应避免不必要的过量装货,即蚂蚁载货量不应超过子任务中剩余需求量,否则会影响其他子任务的计算过程。所以蚂蚁装货量应为子任务总需求量、蚂蚁最大装载量和供应量的最小值。完成装货或者卸货后,再次进行目的地的选择。重复以上过程直到所有需求地的都得到满足即可。
对于不同的数据量来说,参数的选取是不同的,但是其中又有一定的规律可循。在这里本文针对一组随机(5,5,3)数据(5个供应地,5个需求地,3辆卡车,与算例分析中的第一组(5,5,3)相同)来说明一下参数的选取方式。
对于参数p和q,q代表蚂蚁的组数,p代表每组蚂蚁的数量,也就是说p*q是蚂蚁的总数量,在p*q固定不变的情况下,q与p的比值的变化会影响最终解的情况。由于信息素矩阵的更新是以组为单位的,即每跑完一组蚂蚁,更新一次信息素矩阵,所以q与p的比值越大,说明信息素矩阵更新次数越多,花费时间越长,取得更好的解的概率也会变大。
下面所有表格中“结果”表示30次解中较优的15次的平均值,“时间”表示30次计算所花费的平均时间。
表1:不同q/p值对结果和时间的影响
表2:不同q*p值对结果和时间的影响
从表1可以看出,q与p的比值在3左右的时候30次结果的平均值已经非常好,而且计算时间相对较少。从表2可以看出,p*q的值为30左右的时候30次结果的平均值已经非常好,而且计算时间相对较少。
对于u和v,u代表随机子任务划分循环次数,v代表随机产生子任务序列循环次数,u*v表示总的子任务执行数。与p,q的选取规律是一样的。下面给出表格分析:
表3:不同u/v值对结果和时间的影响
表4:不同α*β值对结果和时间的影响
从表3可以看出,u和v的比值对计算时间几乎没有影响,对结果有一定的影响,比值为5的时候效果最好。从表4可以看出,u,v的比值为5左右且u,v的乘积为1600左右时,结果达到最优且计算时间较短。
从以上分析可以得出结论,这4个参数的取值都会对结果产生影响。在实际计算中,我们可以采取上面的方式来选取合适的参数。
算例分析
以下表格中“单位”表示城市或者卡车,“属性”表示某单位的信息。
单位中mi(i=1,2...m)表示供应地,nj(j=1,2...n)表示需求地,tk(k=1,2...k)表示卡车。属性中x表示单位的横坐标,y表示单位的纵坐标,num表示城市的供应量(num为正)或者城市的需求量(num为负)或者卡车的最大运载量。
运行结果中的“完成总任务所花费时间”为所有卡车中最后一个完成任务的卡车所走的路程。因为问题假设各个卡车的速度相同,所以完成总任务所花费时间和最后一个完成任务的卡车所走的路程成正比,因此我们做这样的代替。
算例运行的服务器配置为:2个64位的e5-2620v32.4ghz(6核)的cpu,物理内存16gb。
五个供应地五个需求地三辆卡车
表5:(5,5,3)单位信息
表6:优化前30次计算结果
表5给出了(5,5,3)的具体单位信息,表6是优化前30次计算结果的分布情况。优化前平均计算时间为:31.86s,其中最优结果的卡车路径为:
t1:m5(+2)→n4(-1)→n5(-1)→m2(+2)→n5(-2)→m2(+2)→n5(-2)
t2:m1(+1)→n3(-1)→m4(+1)→n3(-1)
t3:m4(+3)→n2(-3)→m4(+2)→n1(-2)
路径信息中供应地后的括号内的正数代表卡车在此供应地装货,需求地后的括号内的负数代表卡车在此需求地卸货,比如:卡车t1先从初始位置去了供应地m5,装了2个单位的物资,然后去了需求地n4,卸载了1个单位物资。
表7:优化后30次计算结果
表7给出了优化后的30次计算结果的分布情况。优化后平均计算时间为:12.26s,其中最优结果的卡车路径为:
t1:m5(+2)→n4(-1)→n5(-1)→m2(+2)→n5(-2)→m2(+2)→n5(-2)
t2:m1(+1)→n3(-1)→m4(+1)→n3(-1)
t3:m4(+3)→n2(-3)→m4(+2)→n1(-2)
图5中给出了最优解的仿真示意图,图中路线旁边的括号内的数对表示卡车名字以及该卡车在该路线终点处装货(正数)或卸货(负数)的数量。
通过以上算例分析可以看出,在加入分支定界法的思想后,30次计算结果的分布情况几乎无变化,但是计算过程所需的时间大大缩短,效率得到了明显的提高。
其他算例数据:
表8中的算例所给的单位信息均为计算机随机生成,这里只给出算例的信息,单位信息不再详细给出。
其中,“优化前平均计算时间”表示没有在算法中加入分支定界法前30次计算所花费的平均时间,“优化后平均计算时间”表示加入分支定界法后30次计算所花费的平均时间。
表8:算例分析
通过表8给出的算例分析可以看出,对于不同规模的数据量,算法都可以在可接受的时间范围内给出较优解,符合启发式算法的特性,并且对于各个程序随机生成的算例而言,加入分支定界法的思想后,计算效率都得到了非常明显的提高。
如图6所示为本发明实施例提供的k-means聚类算法流程图,所述方法包括以下步骤:
前提假设:
(1)任一供应点或需求点都可以被多次。访问
(2)总供应量不小于总需求量,车速完全相同,荷载均为2。
(3)车辆在规划期开始时,并不一定在某个供应点或需求点。
(4)根据需要,车辆可以前往两个供应点装货后,再去1个或2个需求点卸货。
(5)装,卸货时间不计。
(6)任意两点间的距离为欧氏距离
算法主流程:
本算法的总思路是根据用户指定的聚类参数和循环上限,进行多次“先聚类分派,后一次装货卸货,同时空闲货车弥补”的时间模拟,最后输出取最优的一次模拟的解。其中聚类参数是一个三元组。而循环上限n则是一个正整数。
“先聚类分派”,指的是先使用k-means聚类算法,将供应点,需求点和货车分别聚类为个供应点群,个需求点群和个货车点群。然后将供应点群和货车点群分派给每个需求点群,使得每个需求点群都有一个分派供应队和分派车队。其方法则是构造两个0-1随机矩阵,一个行,列;另一个行,列。两个矩阵中第i列第j行的值若为1,则视为第j个供应点群或货车点群中的供应点或货车加入第i个需求点群的分派供应队或分派车队。
“后一次装货卸货”,指的是本文认为,要最快将物资送到需求地,则每辆货车都希望只要装货,卸货一次,便能完成目标,然后进入“空闲”状态。空闲状态指的是货车被排出原来需求点群的分派车队,原地不动。
显然,“只要装货,卸货一次,便能完成目标”,是不一定能完成的,比如某个需求点群,存在供应队或货车队中供应点或货车点不足的情况。所以这种情况要用“空闲货车弥补”,即一旦出现这种情况,就寻求还有供应余量的供应点或在空闲状态的货车加入其分派供应队或分派车队。然而有可能暂时找不到空闲车辆,则关于此需求点群内的物资调度只能搁浅,等待出现空闲状态的货车。
有了上述思想,则可以进行具体的算法设计。整个算法的具体流程如下。进行n次循环,每次循环都进行“先聚类分派,后一次装货卸货,同时空闲货车弥补”的时间模拟,时间模拟即是模拟每个时间单位的推进,使得货车移动,装货,卸货,进入空闲状态,同时使得需求点群的分派车队不断排出货车,加入空闲货车,加入供应点的过程。当所有需求点满足,时间模拟结束并得到解。之所以要进行n次循环,是因为每次的聚类结果和两个0-1随机矩阵都有着随机性,从而导致分派的结果有着随机性,最终导致解的优秀性不能保证。所以多次随机取最优。
相关定义:
数据规模(sn,dn,tn):sn代表供应点个数,dn表示需求点个数,tn表示货车个数。
本文算例在拥有24个cpu,型号:e5-2620v3@2.4ghz,64位模式下,总计物理内存:15923mb,总计虚拟内存:16263mb配置的服务器下运行。
例如(8,8,4)规模的问题,程序输入信息如下。
表9供应点信息
表10需求点信息
表11货车信息
当聚类参数为(4,4,4),n为300时,程序得到的路径输出示例如下:
t1:start-s6(1)-d5(-1)-s3(2)-d3(-2)-s7(1)-d8(-1)-s5(2)-d6(-1)
t2:start-s1(2)-d5(-2)-s1(2)-d3(-2)-s5(2)-d7(-1)-s8(1)-d1(-1)
t3:start-s1(2)-d5(-2)-s3(2)-d2(-2)-s2(2)-d1(-2)
t4:start-s1(2)-d6(-2)-s3(2)-d3(-1)-s5(0)-d4(-1)-s8(2)-d4(-2)
以货车t1为例:“t1:”后面代表第一个货车的行驶路径,从start,即此车的初始坐标(571,138),s6即第6个供应点,后面的(1)代表装货1个单位,即此车到第6个供应点装货1个单位,d5即第5个需求点,后面的(-1)代表卸货1个单位,即到d5即第5个需求点卸货1个单位,后面以此类推。
接下来,以(20,20,10)的数据规模为例,取聚类参数(7,5,5)不变,更改循环上限,从200到1400,可以观察到程序用时与单个可行解生成时间约成正比,而比例系数为循环上限。而且循环上限越大,解的优秀性与稳定性也得到提升。而在单个解中,生成用时与解的数值成正相关关系。循环上限取得越大,解的稳定性基本越好。循环上限取得越大,解的优秀性更好,计算用时更长。
表12更改循环上限
表13本算法算例结果
表14改进遗传退火算法算例结果
表15改进蚁群算法算例结果
通过与其他算法的运行数据对比,可以发现本算法在数据规模较小的情况下总体效率较差,需要相对大的循环上限与点群数较多的聚类参数才能得到最优解,相比其他算法在小规模数据下能够快速地,稳定地得到最优解,不足明显。然而在数据规模较大的情况下,本算法的聚类优势体现出来,计算时间相对大大减少,又由于其他启发式算法在后面越来越难以收敛的情况下,在相同的计算时间下,本算法的解的优秀性与计算时间都优于其他算法,体现了本算法的在大规模数据下的优秀性。
如图7所示为本发明实施例提供的遗传退火算法流程图,所述方法包括以下步骤:
符号的说明及示意图:
j:车的数量
n:种群规模
m:供应地和需求地的数量之和
δm:第m个供应点或需求点的初始物资量
r:最大迭代次数
如图8为第一次迭代后第一条染色体的示意图,图中有(1,1),(2,8)两个供应点,有(2,4),(3,7),(6,7)三个需求点,并且只有一辆小车。供应点(1,1)有2个单位的供应量可记为+2,需求点(2,4)有2个单位的需求量可记为-2。
故当
当
当
模型的建立:
首先设第i个染色体最晚结束的小车的行驶路长
pr即为目标函数值
设α为随时间增长的惩罚系数(α>1)
则
算法思想及具体步骤:
相比较正常的遗传算法,改进的遗传退火算法在常见的遗传算法步骤上增加了不可行解判断和惩罚系数自增两步。
通过交配和变异生成的新一代的种群中很可能存在不可行解,所以需要通过不可行解的判断加以识别,并在下轮求解染色体适应度的环节中借助罚函数体现出来。不可行解判断就是对于每一条染色体依照时间顺序(即此时的行驶路程)判断每一个城市是否出现物资不足却仍往外面送物资,以及最后仍未被满足两种情况。
惩罚函数自增就是α在每次迭代后自增,体现在实际中就是程序越来越不能容忍不可行解的存在。
通过有效的判断不可行解的算法,引入罚函数的机制,可以避免过多的不可行解对后代的影响,从而解决了完全打乱实现充分交配变异的后顾之忧。具体gm的值由不可行的程度,即多少城市不满足约束条件来决定,在下一轮评估函数时调用罚函数,避免不可行解对种群的不良影响。
算例分析:
8个供应地,8个需求地,4辆小车
表168个供应地信息
表178个需求地信息
表184辆小车的信息
运行30次,以下为一组可行解:
卡车1路径:[571,138]->m5(-2)->m12(+1)->m15(+1)->m1(-2)->m14(+2)
即卡车1从起点开始到第5个供应地装了2个单位货物,再到第4个需求地卸下1个单位货物,再到第7个需求地卸下1个单位货物,再到第1个供应地装2个单位货物,再到第6个需求地卸下两个单位货物。
卡车2路径:
[359,239]->m1(-2)->m13(+2)->m1(-2)->m13(+2)->m1(-2)->m9(+2)
卡车3路径:
[411,363]->m8(-2)->m12(+2)->m5(-2)->m15(+2)>m2(-2)->m9(+2)->m2(-2)->m9(+2)
卡车4路径:
[584,55]->m6(-1)->m13(+1)->m3(-2)->m11(+2)->m7(-1)->m11(+1)->m3(-2)->m11(+2)->m3(-2)->m14(+2)
d=1354.1
为了验证算法的有效性和高效性,分别选取不同数量的供应地,需求地和车辆数,在同一台机器上实验20次试验取平均值,得下表数据。
表1920次实验数据
算例运行环境为2个64位的e5-2620v32.40ghz(6核)cpu,物理内存16gb。本文中采用的交配率:0.8变异率:0.2.
为了研究不同的交配率对于程序结果的影响,我们针对(8,8,4)样例,采用相同的迭代次数,在同一个机器上重复30次,得下表
表20不同的交配率对于程序结果的影响
由上表可知,随着交配率的增加,程序所得的最优解是在逐渐优秀的,大概在0.8左右解就比较优秀了,但是运行所花费的时间并没有明显变化,故我们应该采用较大的交配率。
数据输出单元103又包括计算最短路径模块、发送邮件模块和数据存储模块,所述计算最短路径模块填写运行次数和用户邮箱之后,获取选择数据模块的具体输入数据,用智能算法单元102确定的算法计算,生成一个输出数据的文本文件,最后在发送邮件模块将计算结果发送到用户邮箱,邮箱内容包括数据量、最短路径的平均值、最优解、最优解出现的次数、本次数据运行的次数、平均运行时间和提供动画演示的链接,同时将计算结果在数据存储模块存储并在前端展示,存储数据包括数据量、智能算法名称、智能算法所用语言、运行时间、最短路径长度和数据存储时间。
仿真运行单元104又包括动画演示模块和路径图展示模块,所述动画演示模块根据计算最短路径模块得到的输出数据进行车辆调度物资的仿真实验,实验演示过程中显示供应地与需求地物资的减少与增加的数量,用虚线标明当前运行路径,并在演示结束时显示本次车辆路径规划的最短路径和最短路径的计算时间。
绿色实心圆表示供应地,红色空心圆表示需求地,蓝色实心小圆表示车辆,同时供应物资的数量、需求物资数量和车辆运载量也会在相应的圆下显示,并随着物资的运送动态增加与减少。
所述路径图展示模块与动画演示模块同步,显示了每一辆车的运行路径以及在动画演示过程中的当前运行路径,黄点表示出发地,绿点为供应地,红点为需求地,每辆车运送结束后对应的该辆车的路径图左侧的标记会由灰变绿。
由上述的实施例可见,本发明的这种基于多种智能算法的车辆路径规划仿真实验平台,专门用于车辆路径规划的仿真,能够方便、快捷地运用多种智能算法进行最短路径的计算,并对这些算法进行大量的测试和比较,从而提高所设计车辆路径规划仿真实验平台的质量,更好地达到仿真的目的,同时也可应用于救灾、物流等多种场景下的车辆路径规划。
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!