互联网金融小微贷款的信用风险识别方法及装置与流程
本发明涉及计算机技术领域,尤其涉及一种互联网金融小微贷款的信用风险识别方法及装置。
背景技术:
目前,现有的信用审核多采用规则引擎与人工授信相集合的方式,规则引擎的规则是刚性设置,这种刚性设置无法全面衡量用户的信用数据,一旦用户的某些特征不满足某条规则就很有可能会被拒绝授信,这种方式会丢失掉很多潜在的用户,同时很多规则不具备自学习功能,无法根据数据的积累进行调整。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种互联网金融小微贷款的信用风险识别方法及装置,旨在根据用户的信用数据,得到用户的信用评分,根据信用评分来决定最终的授信结果。
为实现上述目的,本发明的技术方案如下:
一种互联网金融小微贷款的信用风险识别方法,所述方法包括以下步骤:
1)获取用户信用数据;
2)根据用户的借款行为来划分用户样本;
3)通过获取的用户信用数据以及划分的用户样本得到一个原始的数据集;
4)将数据集分为训练集和测试集,在训练集上实现特征工程,然后将这些操作还原到测试集上,利用在测试集上的效果来衡量最终的表现;
5)根据实际情况选择算法,算法包括逻辑回归模型和xgboost两种信用评分模型;
6)信用评分模型根据用户信息对用户进行信用评分。
具体地,在步骤1)中,用户信用数据包括用户第三方数据,用户个人信息以及一些用户行为数据。
具体地,在步骤2)中,用户样本划分标准通过用户信用数据分析得到。
具体地,在步骤3)中,对全量的数据集需要进行数据清洗和数据预处理。
具体地,在步骤6)中,信用评分模型标准采用auc评分。
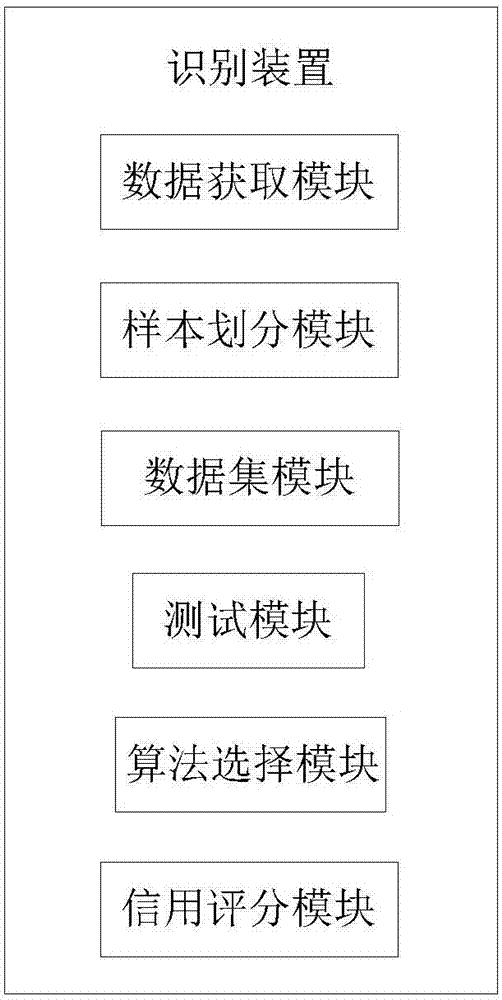
一种互联网金融小微贷款的信用风险识别装置,所述识别装置包括:
数据获取模块,用于获取用户信用数据;
样本划分模块,用于根据用户的借款行为来划分用户样本;
数据集模块,用于将获取的用户信用数据以及划分的用户样本得到一个原始的数据集,该数据集包括训练集和测试集;
测试模块,用于在训练集和测试集上实现特征工程,利用在测试集上的效果来衡量最终的表现;
算法选择模块,用于根据实际情况选择算法,算法包括逻辑回归模型和xgboost两种信用评分模型;
信用评分模块,用于选择的信用评分模型根据用户信息对用户进行信用评分。
进一步地,所述用户信用数据包括用户第三方数据,用户个人信息以及一些用户行为数据。
进一步地,所述样本划分模块的用户样本划分标准通过用户信用数据分析得到。
进一步地,全量的数据集通过数据清洗和数据预处理后划分为训练集和测试集。
进一步地,所述信用评分模块的信用评分标准采用auc评分。
相对于现有技术,本发明的有益效果在于:
1)相对于人工信用审核,加快了用户授信审核的速度,同时也减少了人力成本的开支,在大户量的情况下,该优势会更加显著;
2)与传统的风控规则相对比,从大数据和机器学习的角度来对用户进行授信审核,具备科学性,同时随着数据的积累,模型能够不断的迭代升级,其评分的准确性会越来越高。
附图说明
图1为本发明实施例一互联网金融小微贷款的信用风险识别方法的流程示意图;
图2为本发明实施例二互联网金融小微贷款的信用风险识别装置的结构框图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚、明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例一
本发明提供一种互联网金融小微贷款的信用风险识别方法。
参照图1,图1为本发明互联网金融小微贷款的信用风险识别方法的流程示意图。
该互联网金融小微贷款的信用风险识别方法包括以下步骤:
1)获取用户信用数据,主要包括用户第三方数据,用户个人信息以及一些用户行为数据;
2)根据用户的借款行为来划分用户样本,划分标准可以通过用户信用数据分析得到;
3)通过获取的用户信用数据以及划分的用户样本得到一个原始的数据集,此时针对全量的数据集需要做一些数据清洗和数据预处理的工作,例如对一些范畴有序变量做哑变量处理,对范畴非有序型做热编码处理,对连续数值型数据需要做缺失值处理,对于缺失率过高的维度可以选择删除,对缺失率较低的维度可以做一些填充,例如均值填充和中位数填充,离散型变量则采用众数填充的方式;
4)将全量的数据集分为训练集和测试集,在训练集上实现特征工程,然后将这些操作还原到测试集上,利用在测试集上的效果来衡量最终的表现;
5)根据实际情况选择算法,算法包括逻辑回归模型和xgboost两种信用评分模型,逻辑回归模型是高偏差低方差的模型,具有较强的泛化能力,适用于数据量较少的时候,而像xgboost属于高方差低偏差的模型,相比于逻辑回归,xgboost具有更强的学习能力,但是对数据量的要求高于逻辑回归,如果数据量足够大,也可以考虑引入深度学习和强化学习来进一步提高信用评分的准确性;
6)信用评分模型根据用户信息对用户进行信用评分,评价标准采用auc评分,因为模型是信用评分模型,信用评分模型是希望尽量将好用户排在坏用户的前面,而auc评分正好是衡量这种排序好坏的一个标准。因为模型是信用评分模型,因此在上线时需要与一些反欺诈的强规则一起配合使用,反欺诈强规则主要用户验证用户信息的真实性与有效性。
实施例二
本发明提供一种互联网金融小微贷款的信用风险识别装置。
参照图2,图2为本发明互联网金融小微贷款的信用风险识别装置的结构框图。
该互联网金融小微贷款的信用风险识别装置包括:
数据获取模块,用于获取用户信用数据,所述用户信用数据主要包括用户第三方数据,用户个人信息以及一些用户行为数据;
样本划分模块,用于根据用户的借款行为来划分用户样本,划分标准可通过用户信用数据分析得到;
数据集模块,用于将获取的用户信用数据以及划分的用户样本得到一个原始的数据集,此时针对全量的数据集需要做一些数据清洗和数据预处理的工作,例如对一些范畴有序变量做哑变量处理,对范畴非有序型做热编码处理,对连续数值型数据需要做缺失值处理,对于缺失率过高的维度可以选择删除,对缺失率较低的维度可以做一些填充,例如均值填充和中位数填充,离散型变量则采用众数填充的方式,全量的数据集通过数据清洗和数据预处理后划分为训练集和测试集;
测试模块,用于在训练集和测试集上实现特征工程,利用在测试集上的效果来衡量最终的表现;
算法选择模块,用于根据实际情况选择算法,算法包括逻辑回归模型和xgboost两种信用评分模型,逻辑回归模型是高偏差低方差的模型,具有较强的泛化能力,适用于数据量较少的时候,而像xgboost属于高方差低偏差的模型,相比于逻辑回归,xgboost具有更强的学习能力,但是对数据量的要求高于逻辑回归,如果数据量足够大,也可以考虑引入深度学习和强化学习来进一步提高信用评分的准确性;
信用评分模块,用于选择的信用评分模型根据用户信息对用户进行信用评分,信用评分模型的评价标准采用auc评分,因为模型是信用评分模型,信用评分模型是希望尽量将好用户排在坏用户的前面,而auc评分正好是衡量这种排序好坏的一个标准。因为模型是信用评分模型,因此在上线时需要与一些反欺诈的强规则一起配合使用,反欺诈强规则主要用户验证用户信息的真实性与有效性。
综上所述,本发明相对于人工信用审核,加快了用户授信审核的速度,同时也减少了人力成本的开支;与传统的风控规则相对比,从大数据和机器学习的角度来对用户进行授信审核,具备科学性,同时随着数据的积累,模型能够不断的迭代升级,其评分的准确性会越来越高。
以上仅为本发明的较佳实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!