本发明属于自然语言处理中文本分类领域,是对textcnn(convolutionalneuralnetworksforsentenceclassification)文本分类方法基于卷积层深度的改进。
背景技术:
cnn模型最开始被广泛应用于图像处理任务上,cnn模型后来经过研究发现在自然语言处理领域也行之有效,并在机器翻译,文本分类,搜索查询领域取得了不错的效果。卷积神经网络首次应用于文本分类可以说是在2004年kim在“convolutionalneuralnetworksforsentenceclassification”一文中提出的,主要包括输入层,卷积层,池化层,全连接层。
1.输入层。输入层需要输入一个定长的文本序列l,也就是语句最长包含单词数为l,长度小于l的语句序列需要填充(一般用零填充),长于l的需要截取。在深度学习中一般使用embedding来处理词向量。embedding层在上文获得的词编码的基础上,对单词进行one-hot编码,每个词都会以一个固定维度的向量m保存;然后通过神经网络的训练迭代更新得到一个合适的权重矩阵,最终整个语句序列将转换成一个l*m的固定大小的矩阵形式。
2.卷积层。针对图像任务,cnn卷积核的宽度与高度在处理图像数据时,cnn使用的卷积核的宽度和高度的一样的,但是在textcnn中,卷积核的宽度是与词向量的维度一致。这是因为输入的每一行向量代表一个词,在抽取特征的过程中,词作为文本的最小粒度,如果使用卷积核的宽度小于词向量的维度就已经不是以词作为最小粒度了。而高度和cnn一样,可以自行设置(通常取值2,3,4,5)。由于输入是一个句子,句子中相邻的词之间关联性很高,因此,当用卷积核进行卷积时,不仅考虑了词义而且考虑了词序及其上下文。(类似于skip-gram和cbow模型的思想)。
3.池化层。因为在卷积层过程中使用了不同高度的卷积核,使得通过卷积层后得到的向量维度会不一致,所以在池化层中,使用1-max-pooling对每个特征向量池化成一个值,即抽取每个特征向量的最大值表示该特征,而且认为这个最大值表示的是最重要的特征。当对所有特征向量进行1-max-pooling之后,还需要将每个值给拼接起来。得到池化层最终的特征向量。在池化层到全连接层之前可以加上dropout防止过拟合。
4.全连接层。全连接层跟其他模型一样,假设有两层全连接层,第一层可以加上’relu’作为激活函数,第二层则使用softmax激活函数得到属于每个类的概率。如果处理的数据集为二分类问题,如情感分析的正负面时,第二层也可以使用sigmoid作为激活函数,然后损失函数使用对数损失函数’binary_crossentropy’。
5.输出层。该层的输入为全连接层的输出,经过softmax层作为输出层,进行分类。对于多分类问题可以使用softmax层,对于二分类问题可以使用一个含有sigmoid激活函数的神经元作为输出层。
技术实现要素:
textcnn只选取不同尺寸卷积核对矩阵进行一维卷积,比如选取的窗口大小为2,3,4,那么卷积核的大小就是2*n、3*n、4*n,卷积层的深度只有一层,那么只能获得相邻近的这几词语之间的一个特征关系。因此可以通过增加网络的深度,获得单词与单词之间的特征关系,增加特征维度。使改进后的textcnn的特征可以抽取长距离的文本依赖关系,从而提高文本分类的准确性。
本发明采用的技术方案为一种基于textcnn改进的文本分类方法,本方法采用改进后的textcnn,改进后的textcnn包括输入层,循环的卷积与半池化层,全局池化层,输出层。
1)、输入层通过:词向量wordembeddings,将自然语言中的字词转为计算机理解的稠密向量densevector。假设定义词向量的维度是n,定义句子最大限度包含单词数量为m,构成一张m*n的二维矩阵。
2)、循环的卷积与半池化层:
(1)等长卷积层:为了保持整个语句的长度不被改变,会使用等长卷积。假设卷积核的尺寸为l,那么就意味着那就是将输入语句的每个词位和其左右((l-1)/2)个词的上下文信息压缩为该词位的embedding,也就是说,产生了每个词位的被上下文信息修饰过的更高级别更加准确的语义。
(2)残差连接:将该层的输入层与等长卷积后的卷积层相加。由于在初始化深度cnn时,往往各层权重都是初始化为一个很小的值,这就导致最开始的网络中,后续几乎每层的输入都是接近0,这时网络的输出自然是没意义的,而这些小权重同时也阻碍了梯度的传播,使得网络的初始训练阶段往往要迭代多层才能启动。同时,就算网络启动完成,由于深度网络中仿射矩阵即每两层间的连接边近似连乘,训练过程中网络也非常容易发生梯度爆炸或弥散问题。既然每个参加循环的单元即卷积层与半池化层的输入在初始阶段容易是0而无法激活,那么直接用一条线把上一层的输出层连接到每个循环单元的输入乃至最终的池化层/输出层。这时的残差连接由于连接到了各个循环的单元的输入,当然为了匹配输入维度,要事先经过对应次数的1/2池化操作。有了残差连接后,梯度就能够忽略卷积层权重的削弱,从残差连接一路无损的传递到各个循环的单元,直至网络前端,从而极大的缓解了梯度消失问题。
(3)半池化层:在池化层每经过一个大小为3,步长为2的池化层(以下简称半池化层),序列的长度就被压缩成了原来的一半。这样,同样是size=3的卷积核,每经过一个1/2池化层后,其能感知到的文本片段就比之前长了一倍。由于半池化层的存在,文本序列的长度会随着循环单元数量的增加呈指数级减少。
(4)循环叠加卷积与半池化:通过增加网络的深度,获得单词与单词之间的特征关系,增加特征维度。随着网络深度的增加可以抽取长距离的文本依赖关系,从而提高文本分类的准确性。
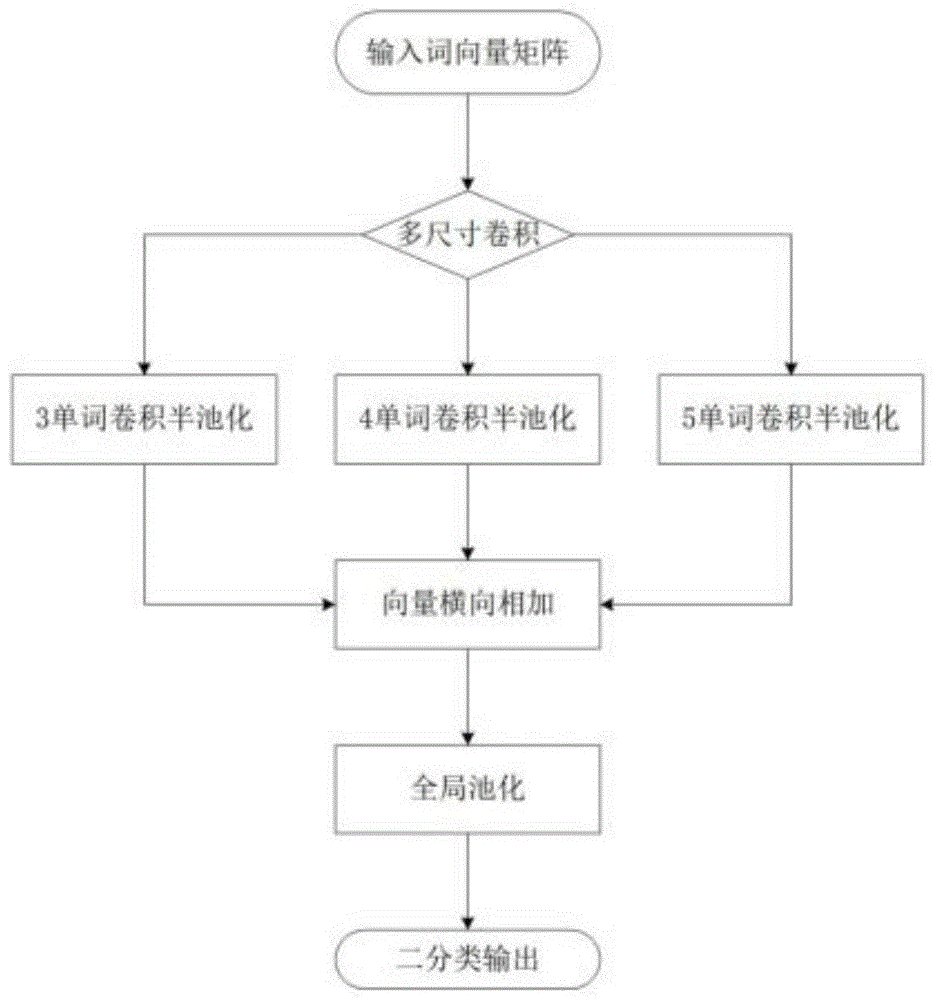
3)、全局池化层:将以3,4,5个单词为单位同时进行卷积池化后的向量横向相加,增加特征的维度。全连接层存在限制输入维度大小,参数过多的问题。全连接层需将所有特征图转成向量拼接后再全连接。而globalpooling思想基于全连接后最终还是输出一个固定大小向量的特点,直接对每个featuremap进行处理。比如3个1*64的featuremap,对每个featuremap取最大值直接得到一个1*3维的特征向量。
4)、输出层:该层的输入为全局池化层,经过softmax层作为输出层,进行分类。对于多分类问题使用softmax层,对于二分类问题使用一个含有sigmoid激活函数的神经元作为输出层。
附图说明
图1是本发明中改进textcnn流程图。
图2是本发明中改进textcnn结构图。
图3是本发明中改进textcnn模型用于文本分类的流程图。
具体实施方式
结合说明书附图对发明的实施方式进行描述,中文文本分类主要分为以下步骤,
1、中文分词
中文的是指将一个由汉字和其他常规字符组成的连续序列,按照中文理解方法,将其划分为单个的词语,在实施过程中可以使用jieba分词工具对文本进行分词可以看到这个句子被分割成了单个的词语。
2、去停用词
在正常的中文文本中通常会包含句号,逗号,分号等特殊符号,在分词完成后,这些标点符号就不需要继续存在,其次句子中包含了一些对句子重要度影响很小的词语,如的,了,不仅,而且,等词语,在后续步骤中不需要使用,因此在预处理对其进行删除处理。
3、构建词向量
词向量(wordembeddings),将自然语言中的字词转为计算机可以理解的稠密向量(densevector)。word2vec能够将词映射成一个固定长度的短向量,所以生成了文档集合词语的向量表示。由于向量的距离代表了词语之间的相似性,可以通过聚类的方法(譬如k-means)把相似的词语合并到一个维度,重新计算该维度的特征向量权值。相比于传统统计方法,使用词向量能在一定程度保留了文档的信息。此外,word2vec作为无监督学习方法的一个实现,能够允许它从无标注的文本进行训练,能进一步提升系统的性能。假设定义词向量的维度是n,定义句子最大限度包含单词数量为m,构成一张m*n的二维矩阵。
4、使用改进textcnn文本分类
假设定义词向量的维度是n,定义句子最大限度包含单词数量为m,构成一张m*n的二维矩阵,在输入层保持与textcnn相同的词向量输入结构,即对一片文本区域进行一组卷积后生成embadding。在卷积层一般为了保持整个语句的长度不被改变,通常会使用等长卷积。假设卷积核的尺寸为l,那么就意味着那就是将输入语句的每个词位和其左右((l-1)/2)个词的上下文信息压缩为该词位的embedding,也就是说,产生了每个词位的被上下文信息修饰过的更高级别更加准确的语义。在池化层每经过一个大小为3,步长为2的池化层(以下简称半池化层),序列的长度就被压缩成了原来的一半)。这样同样是size=3的卷积核,每经过一个1/2池化层后,其能感知到的文本片段就比之前长了一倍。通过不断叠加网络结构中的卷积层以及池化层,以抽取长距离的文本依赖关系,从而提高文本分类的准确性。
5.分类结果对比评估
使用查准率,查全率,roc_auc曲线来对比使用深度学习中文本分类中常见的模型,如textcnn,textrnn,textrnn+attention,textrcnn等,验证改进的textcnn提高文本分类的准确性。