一种齿轮传动装置的非概率可靠性评估方法与流程
本发明涉及齿轮传动装置可靠性评估领域,具体涉及一种齿轮传动装置的非概率可靠性评估方法。
背景技术:
齿轮传动装置是机械传动系统中最常见的传动形式之一。齿轮传动装置的可靠性将直接影响到机械系统的传动效率,而在齿轮传动装置的设计过程当中,齿轮所承受的最大应力必须小于其最大许用应力。
针对齿轮传动装置的可靠性评估与设计,现有的方法存在以下问题:
1、现有针对齿轮传动装置的设计方法,大部分是在系统参数模型处于确定性条件下展开研究的,但在实际的齿轮传动装置设计过程中,由于边界条件、初始条件、测量条件存在误差或不确定性,如果仍把这些因素看作确定性因素来对待,则将导致系统响应与实际响应产生较大的偏差。
2、针对齿轮传动装置的可靠性评估方法,现有的一些方法采用概率模型来描述不确定性设计变量,如公开号为cn105138794a的专利“一种直齿轮传动系统可靠性评估方法”,但实际的设计过程中,许多不确定变量因缺乏足够的样本数据而致使概率分布密度未知,从而导致很难精确地获得不确定性设计变量的概率分布。
3、针对齿轮传动装置的可靠性评估方法,现有的一些方法采用非概率凸集模型来描述不确定性设计变量,如公开号为cn102446239a的专利“考虑认知和随机不确定性的齿轮传动多学科可靠性分析方法”,该专利依据设计参数不确定性数据的完备性,通过概率模型和非概率凸集模型来描述不确定性设计参数,虽然描述不确定性设计参数的非概率凸集模型并不需要精确的概率分布,但由于非概率凸集模型过多的强调极端工况,从而将会造成保守设计。
4、对于齿轮传动装置这类复杂的可靠性评估问题而言,往往涉及非常耗时的数值分析模型。因此,为了克服优化效率低下的缺点,少部分现有技术使用了近似模型技术,但部分专利只是对近似模型进行了一次构建,而针对齿轮传动装置这类复杂的工程问题而言,一次近似模型的建立是无法保证可靠性评估的精度的;虽然公开号为cn107273609a的专利“一种基于kriging模型齿轮传动可靠性评估方法”通过kriging模型实现了对齿轮传动装置多次近似模型的重构,但该专利的设计参数均采用随机变量来描述,即随机变量分布类型需通过数据收集和假设检验得到,这将导致很难精确地获得随机变量的概率分布,其次该专利无论是构建近似模型还是对结构功能函数进行可靠性评估都用到了蒙特卡罗方法,这都需要采集大量的样本点,从而致使计算效率的下降。
技术实现要素:
本发明的目的是为了解决现有齿轮传动装置可靠性评估方法存在的上述问题,提出了一种齿轮传动装置的非概率可靠性评估方法。
本发明解决其技术问题所采用的技术方案是:一种齿轮传动装置的非概率可靠性评估方法,包括如下步骤:
步骤1:对齿轮传动装置设计过程中的不确定性因素进行分析,并根据样本点的信息确定证据变量的识别框架与基本可信度分配,然后根据实际问题构建如公式(1)所示的针对齿轮传动装置可靠性评估的极限状态函数g(x):
g(x)=g0公式(1)
公式(1)中,g0为许可响应值,证据变量
公式(2)中,xi表示第i个焦元,
步骤2:基于拉丁超立方采样技术在证据变量的识别框架内获得“构建组”和“测试组”两组样本点,并给定近似模型的允许误差ε>0,置加密次数s=0;
步骤3:利用“构建组”样本点构建极限状态函数的近似模型
步骤4:基于“构建组”获得的近似模型
步骤5:计算误差
步骤6:将
公式(3)中,
步骤7:应用一阶近似可靠性分析方法对每个联合焦元在一阶泰勒展开函数
公式(4)中,ax为联合焦元,m(ax)为联合焦元ax的基本可信度分配,
优选的,所述步骤3中用径向基函数来构造极限状态函数的近似模型。
优选的,所述步骤7中极值分析过程如下式所示:
在进行上述极值分析时,若
本发明的有益效果是:
1、针对背景技术提出的第1点,本发明采用证据理论对齿轮传动装置的不确定性设计变量进行建模,从而考虑了不确定性因素对设计结果的影响。
2、针对背景技术第2点,本发明采用的证据理论对齿轮传动装置的不确定性设计变量进行建模,在建模过程中仅需要知道每个不确定性变量所包含焦元(基本可信度,类似于概率理论中的概率密度函数)的区间与质量,这些焦元的区间和质量可通过有限的样本来获得,而并不需要大量的样本点来构建精确的概率模型,从而大大降低了不确定性设计变量模型构建的难度。
3、针对背景技术提出的第3点,本发明采用的证据变量对齿轮传动装置的不确定性设计变量进行建模,因每个不确定性变量所包含的焦元因具备区间和质量两个要素,而非概率凸集模型仅用区间来描述,因此采用的证据变量进行可靠性评估时能有效避免保守设计。
4、针对背景技术提出的第4点,本发明将局部加密近似模型方法引入齿轮传动装置的可靠性评估,通过大幅度减少实际模型的计算次数来提高求解效率,同时对近似模型进行多次重构来保证近似模型和可靠性分析的精度;另外本发明采用一阶近似可靠性分析方法对近似极限状态函数进行求解,从而获得衡量齿轮传动装置可靠性的可信度和似真度,从本质上提高可靠性评估的计算效率和求解质量,从而真正发挥非概率可靠性评估方法在齿轮传动装置应用方面的优势。
注:上述设计不分先后,每一条都使得本发明相对现有技术具有区别和显著的进步。
附图说明
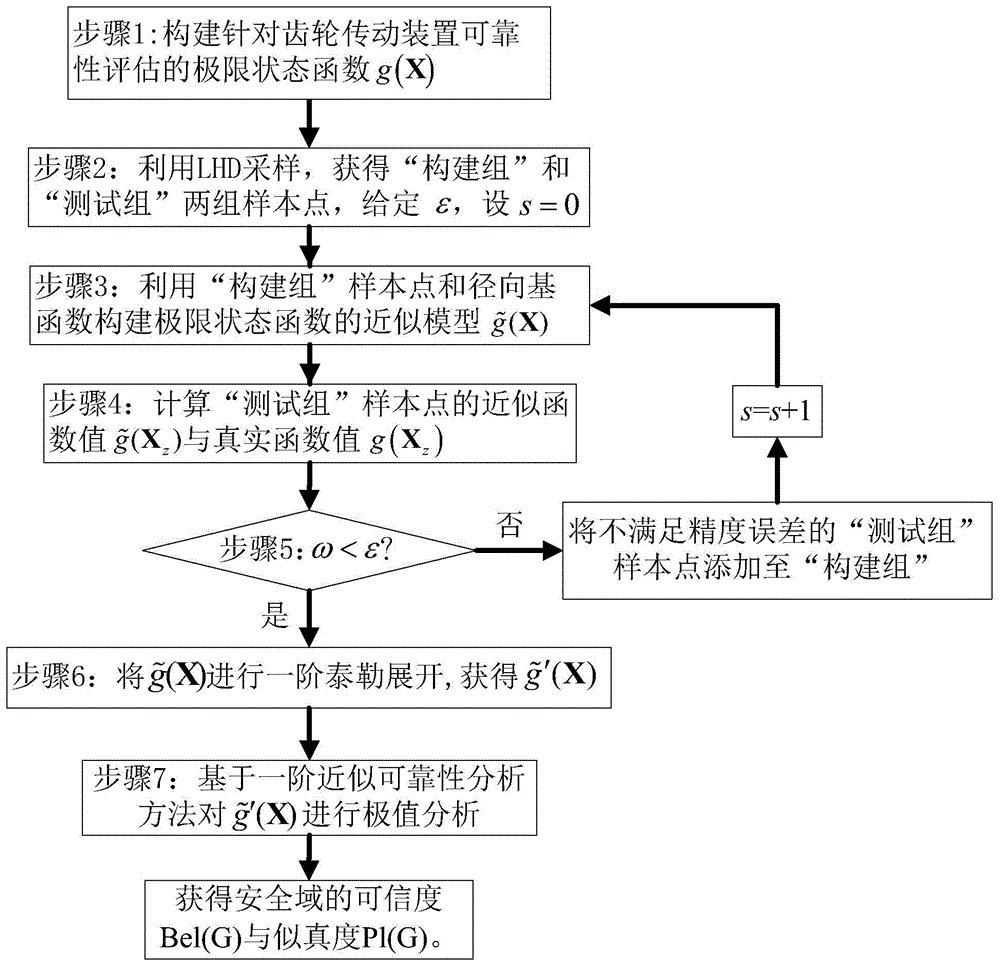
图1是本发明齿轮传动装置的非概率可靠性评估方法的流程图
图2是具体实施例中齿轮传动装置的模型示意图
图中,附图标记如下:
1、大齿轮2、小齿轮3、轮辐厚度4、轮辐宽度5、轴孔半径
具体实施方式
下面结合附图对本发明的通用方法进行说明:
如图1所示,一种齿轮传动装置的非概率可靠性评估方法,包括如下步骤:
步骤1:对齿轮传动装置设计过程中的不确定性因素进行分析,并根据样本点的信息确定证据变量的识别框架与基本可信度分配,然后根据实际问题构建如公式(1)所示的针对齿轮传动装置可靠性评估的极限状态函数g(x):
g(x)=g0公式(1)
公式(1)中,g0为许可响应值,证据变量
公式(2)中,xi表示第i个焦元,
步骤2:基于拉丁超立方采样技术在证据变量的识别框架内获得“构建组”和“测试组”两组样本点,并给定近似模型的允许误差ε>0,置加密次数s=0;
步骤3:利用“构建组”样本点和径向基函数构建极限状态函数的近似模型
步骤4:基于“构建组”获得的近似模型
步骤5:计算误差
步骤6:将
公式(3)中,
步骤7:应用一阶近似可靠性分析方法对每个联合焦元在一阶泰勒展开函数
公式(4)中,ax为联合焦元,m(ax)为联合焦元ax的基本可信度分配,
在进行上述极值分析时,若
为了进一步的对本发明做进一步详细说明,下面再结合一具体实施例对本发明的方案做一个说明。本实施例以齿轮传动装置的可靠性评估为实施例,在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
如图2所示,为本发明方法所针对的齿轮传动装置的模型示意图。按照图1所示的流程进行实施。一种齿轮传动装置的非概率可靠性评估方法,针对如图2所示的齿轮传动装置,其具体步骤为:
步骤1:对齿轮传动装置设计过程中的不确定性因素进行分析,同时考虑到齿轮传动结构的设计过程当中,齿轮所承受的最大应力必须小于其最大许用应力。因此,以大齿轮为设计对象,选取大齿轮轮辐的厚度x1、大齿轮轮辐的宽度x2和大齿轮轴孔的半径x3为证据变量,其相应的基本可信度分配如表1所示,从而构建如下所示的极限状态函数:
g(x)=fσ-fmax(x)公式(6)
x=(x1,x2,x3)t
5mm≤x1≤10mm
20mm≤x2≤80mm
40mm≤x3≤65mm
公式(6)中:fσ为最大许用应力,fmax为大齿轮所承受的最大应力;
表1证据变量x1、x2、x3的基本可信度分配(bpa)
步骤2:基于拉丁超立方采样技术在证据变量x1、x2、x3的识别框架内获得“构建组”和“测试组”两组样本点,其中,“构建组”和“测试组”分别采样30个样本点,并给定近似模型的允许误差ε=8%,置加密次数s=0;
步骤3:利用“构建组”样本点和径向基函数构建极限状态函数的近似模型
步骤4:基于“构建组”获得的近似模型
步骤5:计算误差
本实施例通过2次样本点局部加密和50个样本点(30个初始样本点,20个局部加密样本点),获得了满足精度要求的极限状态函数近似模型
表2样本点局部加密过程表
步骤6:将
公式(7)中,
步骤7:应用一阶近似可靠性分析方法对每个联合焦元在一阶泰勒展开函数
公式(8)中,ax为联合焦元,m(ax)为联合焦元ax的基本可信度分配,
在进行上述极值分析时,若
本实施例将大齿轮结构的近似极限状态函数与一阶近似可靠性分析方法相结合对其进行可靠性评估,最终得到的可靠性结果如表3所示。当大齿轮结构的屈服极限为200mp时,其可信度与似真度分别为0.5054和0.993,此时大齿轮结构的可靠性较差,不满足工程设计要求;而当大齿轮结构的屈服极限提高到287mp时,其可信度、似真度分别达到0.999和1,说明此时大齿轮结构已具有较高的可靠性,满足工程设计的要求。
表3大齿轮可信度和似真度计算结果
上列详细说明是针对本发明可行实施例的具体说明,该实施例并非用以限制本发明的专利范围,凡未脱离本发明所为的等效实施或变更,均应包含于本案的专利范围中。
- 还没有人留言评论。精彩留言会获得点赞!