一种基于网格的地形特征点提取方法及处理终端与流程
本发明涉及数字地形分析技术领域,具体是一种基于网格的地形特征点提取方法及处理终端。
背景技术:
在制作海图、水深地形图或者陆地地形图时,一般都需要标注地形的特征点,特征点即是一定区域范围内的地形极值点,从而构成完整精确的地形表达图。如何提取特征点,目前常用自动选取方法可分为两类:一是等距随机选取数据点,即按照一定的规则网格间距来随机选取数据点,该方法标注的数据点整齐美观,但很容易漏标特征点,无法满足制图的要求;二是不等间距选取特征点,通常根据人工经验选取特征点,需要标注特征点的位置一般包括山顶、山脊、洼地、狭长山谷等地形突变的地方。针对第二种方法,需要依赖于制图员自己对地形的认识、知识经验、思维方式,且对自己熟悉的、常用的地形场景,其应用效果较好,而对于其他场景下的地形,往往提取的特征点并以此制作出的地形表达效果与期望存在较大偏差,其实际应用效果并不好。
目前现有的地形、海底特征点提取方法,主要存在以下两方面的不足:
1.无法处理海量数据:
以上提及的不等间距选取特征点方法,无论是基于人工智能法、delaunay三角网法、vononoi构造图法,还是基于其它算法,都需要首先将制图区域内所有的离散数据一次性读进计算机内存进行结构化处理,从而能够得到各离散点间的拓扑关系,形态分布、密度分布等重要参数。然后对所有相邻点之间的相互关系进行分析与运算,最后才能得到符合条件的地形特征点。如果数据量较小(几百mb以内),一般计算机都能够轻松处理,但如果面对海量的离散数据(例如gb级别的数据),例如多波束水深测量成果数据,一个调查区的数据量通常都达到几gb至几十gb,甚至上百gb,普通计算机因内存限制而根本无法处理。如果先将大数据分割成多个小区块数据然后再依次处理,则存在效率低下的问题。
2.dem为简化后的原始数据:
一些基于dem的特征点提取算法,虽然一般不存在数据量大小的问题,但由于dem本身就是由原始离散数据进行规则网格化而得,在网格化过程中,原始特征点的高程值与位置均发生了变化,无法精确表达真实的地形特征。地形特征点,特别是航海图的水深特征浅点,作为最重要的水深数据,其首要作用是保障航行安全,特征浅点不可轻易进行化简和删除,应原样保留,从而保证海图制图规范的基本要求,如果特征浅点出现丢失,不仅使水深反映的海底地形失真,而且更严重的是为航行安全带来隐患。因此,特征点的选取必须从原始离散数据开始,而不能从经过任何简化后的数据中提取地形特征点。
相关的参考文献如下:
[1]王家耀,田震.海图水深综合的人工神经元网络方法[j].测绘学报,1999,28(4):335-339.
[2]刘颖,翟京生,陆毅,etal.数字海图水深注记的自动综合研究[j].测绘学报,2005,34(2):179-184.
[3]缪志修,齐华,王国昌,etal.基于机载lidar数据构建的dem抽稀算法研究[j].铁道勘察,2010,36(4):39-44.
[4]徐景中,万幼川,张圣望.lidar地面点云的简化方法研究[j].测绘信息与工程,2008,33(1):32-34.
[5]冯宇瀚,殷晓冬,王少帅,etal.基于三角网构建海底dem的抽稀算法[j].海洋测绘,2012,32(6):33-35.
[6]刘春,吴杭彬.基于平面不规则三角网的dem数据压缩与质量分析[j].中国图象图形学报,2007,12(5):836-840.
[7]聂鑫.精度约束下基于机载lidar点云数据的dem压缩算法研究[d].西南交通大学,2014.
[8]钱锦锋,陈志杨,张三元,etal.点云数据压缩中的边界特征检测[j].中国图象图形学报,2005(02):34-39.
[9]黄承亮,向娟.基于三维tin的格网化点云数据特征提取[j].测绘科学,2010(s1):127-128.
[10]刘建军,赵文豪,蒯希,etal.一种基于tin的地形特征点生成方法[j].地理信息世界,2015(1):91-94.
[11]周扬.一种适用于山区dem生产的地形特征点自动提取技术研究与应用[j].科技风,2018,no.350(18):142-143.
[12]王沫,张立华,于彩霞,刘涛.一种基于水深点坡向关系的特征浅点提取方法[j].武汉大学学报:信息科学版(2期):208-213.
[13]黄亚锋,艾廷华,张航峰.数字海图水深注记的自动选取[j].测绘科学,2016(41):33.
[14]朱雪坚,叶远智,汤国安.运用三维douglas-peucker算法提取dem地形特征[j].测绘通报,2014(03):125-128.
[15]刘晓红,李树军.矢量数据压缩的角度分段道格拉斯算法研究[j].测绘,2005,28(2):51-52.
[16]费立凡,何津,马晨燕,etal.3维douglas-peucker算法及其在dem自动综合中的应用研究[j].测绘学报,2006,35(3):278-284.
[17]何津,费立凡.再论三维douglas-peucker算法及其在dem综合中的应用[j].武汉大学学报:信息科学版,2008,33(2):160-163.
技术实现要素:
针对现有技术的不足,本发明的目的之一提供一种基于网格的地形特征点提取方法,其能够解决地形特征点提取的问题;
本发明的目的之二提供一种处理终端,其能够解决地形特征点提取的问题。
实现本发明的目的之一的技术方案为:一种基于网格的地形特征点提取方法,包括如下步骤:
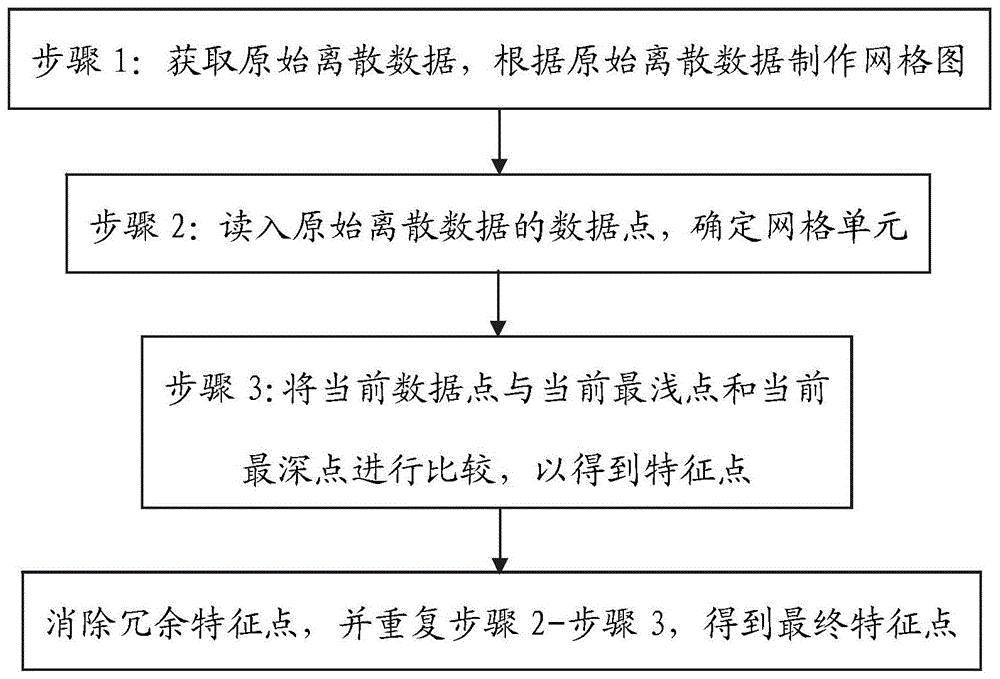
步骤1:获取表征实际地形特征的原始离散数据,根据原始离散数据制作由若干网格单元组成的网格图;
步骤2:依次读入原始离散数据的数据点,若该数据点落入网格图范围内,则确定该数据点位于网格图中的网格单元,否则,舍弃该数据点;
步骤3:将当前数据点与所在网格单元的当前最浅点和当前最深点进行比较,如果当前数据点的水深值z小于所在网格单元的当前最浅点,或,如果当前数据点的水深值z大于所在网格单元的当前最深点,则当前数据点为特征点。
进一步地,所述步骤3之后,还包括消除冗余特征点,冗余特征点是指相邻的两个网格单元分布有邻近特征点,邻近特征点是指其两者距离小于等于预设距离;
将所有冗余特征点均消除,将步骤3中所有的特征点进行合并得到新的数据组,依次读入新的数据组的数据点,并按步骤2确定各个数据点所在的网格单元,随后,按步骤3依次对所有数据点进行处理,得到最终的特征点,从而提取出特征点。
进一步地,消除冗余特征点包括如下步骤:
步骤4:将初始网格图向左整体平移半个网格间距,得到新的网格图,以消除左右相邻的冗余特征点;
步骤5:将经过步骤4后的网格图向下整体平移半个网格间距,以消除上下相邻的冗余特征点;
步骤6:将经过步骤5后的网格图向左向下整体平移半个网格间距,以消除四周相邻的冗余特征点。
进一步地,所述根据原始离散数据制作由若干网格单元组成的网格图的具体实现过程,包括如下步骤:
根据原始离散数据确定边界参数(xmin,xmax,ymin,ymax),以使得原始离散数据中的每一个数据点均落入由边界参数确定的网格图内,其中,数据点包括包括表征经度坐标的x、表征纬度坐标的y和表征水深的z,
x方向的网格数量grid_x=(xmax-xmin)/δx+1,y方向的网格数量grid_y=(ymax-ymin)/δy+1,则网格总数量=grid_x*grid_y,从而确定网格图,其中,δx表示网格单元的长度,δy表示网格单元的宽度。
进一步地,所述确定该数据点位于网格图中的网格单元的具体实现过程,包括如下步骤:
根据该数据点的x坐标值确定网格图中x方向的网格位置,x方向的索引号:index_x=(x-xmin)/δx+1,x表示该数据点的x坐标值;然后,根据数据点的y坐标值确定网格图中y方向的网格位置,y方向的索引号:index_y=(y-ymin)/δy+1,y表示该数据点的y坐标值;最后确定该数据点在网格图中的网格单元位置:网格索引号:index_num=(index_y-1)*grid_x+index_x,grid_x=(xmax-xmin)/δx+1,其中,δx和δy分别表示网格单元的长宽,从而确定数据点所在的网格单元。
实现本发明目的之二的技术方案为:一种处理终端,其包括,
存储器,用于存储程序指令;
处理器,用于运行所述程序指令,以执行所述基于网格的地形特征点提取方法中的步骤。
本发明的有益效果为:本发明可以从海量输入数据中(由单个文件或者多个文件组成)提取陆地地形或海底地形的特征点,不会因数据量过大而无法运算的情况;并且通过简单的算法能够实现复杂的地形特征点提取,容易推广使用,效果好。
附图说明
图1为本发明的步骤示意图;
图2为本发明冗余特征点在网格图上的示意图;
图3(包括(a)和(b))为冗余特征点指向同一个实际地形的示意图;
图4为某实际海底地形三维立体阴影图;
图5为对图4传统方法标注特征点后的效果图;
图6为按本方法对图4标注特征点后的效果图;
图7为本发明一种处理终端的结构示意图。
具体实施方案
下面,结合附图以及具体实施方案,对本发明做进一步描述:
如图1至图3所示,一种基于网格的地形特征点提取方法,包括如下步骤:
步骤1:获取表征实际地形特征的原始离散数据,原始离散数据中的每一个数据点包括表征经度坐标的x、表征纬度坐标的y和表征水深的z。根据制图的图幅范围及比例尺大小划分图上距离为1cm(厘米)的网格,实际使用中,也可以采用其他距离值的网格,例如2cm的网格,并根据图上距离确定网格间距(δx,δy),δx和δy分别表示一个网格单元的长宽。
根据原始离散数据确定边界参数(xmin,xmax,ymin,ymax),xmin和xmax分别表示网格图的x坐标的最小值和最大值,ymin和ymax分别表示网格图的y坐标的最小值和最大值,边界参数确定了整个网格图范围,原始离散数据均落入由边界参数确定的网格图内,并可根据边界参数确定二维坐标系下的x方向的网格数量和y方向的网格数量,从而确定网格总数量,其中,二维坐标系下的x方向和y方向分别代表经度和纬度。具体的,x方向的网格数量grid_x=(xmax-xmin)/δx+1,y方向的网格数量grid_y=(ymax-ymin)/δy+1,则网格总数量=grid_x*grid_y。
步骤2:依次读入原始离散数据的数据点,若该数据点未落入由边界参数确定网格图范围内,则舍弃该数据点,否则,确定该数据点位于网格图中的网格单元,从而得出该数据点位于哪个网格单元。确定一个数据点位于哪个网格单元,可通过以下步骤确定:
首先,根据该数据点的x坐标值确定网格图中x方向的网格位置,x方向的索引号:index_x=(x-xmin)/δx+1,x表示该数据点的x坐标值;然后,根据数据点的y坐标值确定网格图中y方向的网格位置,y方向的索引号:index_y=(y-ymin)/δy+1;最后确定该数据点在网格图中的网格单元位置:网格索引号:index_num=(index_y-1)*grid_x+index_x。
步骤3:将当前数据点与所在网格单元的当前最浅点和当前最深点进行比较,如果当前数据点的水深值z小于所在网格单元的当前最浅点,其中各个网格单元的当前最浅点的初始值为999999,则将该数据点的x坐标值、y坐标值和水深值z分别保存至以下变量中:
min_lon[index_num]:用于保存index_num网格单元极小值的经度坐标;
min_lat[index_num]:用于保存index_num网格单元极小值的纬度坐标;
min_z[index_num]:用于保存index_num网格单元的极小值。
这样每读入一个符合上述要求的数据点后,当前最浅点的值即为最新读入的数据点的水深值z。
同样的,如果当前数据点的水深值z大于所在网格单元的当前最深点,其中各个网格单元的当前最深点的初始值为-999999,则将该数据点的x坐标值、y坐标值和水深值z分别保存至以下变量中:
max_lon[index_num]:用于保存索引值为index_num网格极大值的经度坐标;
max_lat[index_num]:用于保存index_num网格极大值的纬度坐标;
max_z[index_num]:用于保存index_num网格的极大值。
这样每读入一个符合上述要求的数据点后,当前最深点的值即为最新读入的数据点的水深值z。
从而得到任意一个网格单元内的极小值的经度坐标、纬度坐标和极小值,分别记为min_lon、min_lat、min_z,其是数组变量,其中网格单元编号为index_num的极小值的经度坐标、纬度坐标和极小值分别为min_lon[index_num]、min_lat[index_num]、min_z[index_num];同样的,也得到任意一个网格单元的极大值的经度坐标、纬度坐标和极大值,分别记为max_lon、max_lat、max_z。将同一个网格单元的min_lon[index_num]和max_lon[index_num]进行合并得到data_lon,min_lat[index_num]和max_lat[index_num]合并得到data_lat,min_z[index_num]和max_z[index_num]合并得到max_z,从而得到所有网格单元内的极小值和极大值,以及极小值对应的坐标值,极大值对应的坐标值。
这样得到符合上述两种情况之一的数据点即成为特征点,而不符合上述两种情况的其余数据点均不作为特征点,可以舍弃或不作任何操作。遍历原始离散数据的所有数据点,从而初步选取出原始离散数据中的所有特征点。
经过上述步骤后,即可初步得到所有特征点,但可能会出现多个相邻特征点,这些相邻特征点分布于两个相邻网格内,但均靠近相邻网格之间的网格线上而非常接近,相邻特征点也可以称之为邻近特征点,所谓邻近特征点是指两个特征点的距离≤预设距离,在图上看,其两者非常接近,当然也可以由制图员直接指定其为相邻特征点。如图2所示,分布在1号网格单元、2号网格单元、4号网格单元、5号网格单元的四个特征点位置非常接近,以及7号网格单元和8号网格单元的两个特征点也非常接近,6号网格单元和9号网格单元的两个特征点也非常接近,这些相邻特征点实际上是指向同一个特征地形,也即这些相邻特征点是冗余特征点,如图3所示,同一个特征地形上有两个或多个相邻特征点,其中,图3(a)是分布在上下左右四个网格单元的四个相邻特征点指向的同一个实际地形的示意图,图3(b)是分布左右两个网格单元的两个相邻特征点指向的同一个实际地形的示意图。图3(a)和图3(b)实质上均只需要一个特征点即可表示该地形,因此,需要进一步将靠近的相邻特征点钟提取出一个特征点。
为了从相邻特征点钟的各个特征点提取出一个特征点,还包括如下步骤:
步骤4:将初始网格图向左整体平移半个网格间距,因此得到新的网格图,也即xmin=xmin-δx/2、ymin=ymin,从而可以消除左右相邻的冗余特征点;
步骤5:将经过步骤4后的网格图向下整体平移半个网格间距,并得到新的网格图,即xmin=xmin,ymin=ymin-δx/2,利用该参数运行后,将消除上下相邻的冗余特征点;
步骤6:将经过步骤5后的网格图向左向下整体平移半个网格间距,即xmin=xmin-δx/2,ymin=ymin-δx/2,利用该参数运行后,将消除四周相邻的冗余特征点。
步骤7:经过步骤4-步骤6后将所有冗余特征点均消除,并得到新的边界参数,从而根据新的边界参数和网格间隔确定新的网格图的网格数量,具体方法与步骤1相同。
步骤8:将data_lon、data_lat、data_z依次读入数据点,并按步骤2确定各个数据点所在的网格单元,随后,按步骤3依次对所有数据点进行处理,得到最终的特征点,从而提取出特征点。
以下例举一个实例,以解释上述过程对实际的海底地形提取的特征点的结果。如图4-图6所示,图中的白点表示特征点。图4为某海洋工程多波束海底地形测量获得的海底地形三维立体阴影图(局部),制图比例尺为1:5000。此区域水深范围为203—240米左右,海底地形复杂,沙波、沟壑非常发育,地形特征点分布密集,按常规特征提取方法,标注特征点难度大。图5为按照传统的方式以图上距离约1厘米(实际距离为50米)的间距提取水深点,然后叠加在三维阴影图上的效果。由图5可见,众多的水深点虽然能够提供丰富准确的水深信息,但基本都无法准确提供每个特征地形的水深极值信息,况且密密麻麻的水深点反而起到了遮挡背景的三维立体阴影图副作用,影响了阅图效果。实际成图时,白色水深点应以文字的形式标注该处的水深,遮挡效果更为明显,很难达到制图的要求。
而图6位应用本实施例方法得到的海底地形特征点的效果图,将提取到的特征点叠加在相同的三维阴影图上的效果。提取时,网格间距参数为50米,输出的极浅特征点(或极深特征点)之间的实际距离为50-100米,但极浅特征点与极深特征点的距离可能会小于50米。与图5相比,该图特征点分布均匀合理,在地形变化复杂的地方,标注的极浅点与极深点较密集;在地形变化缓慢的地方,特征点标注则较为稀疏。6图能够提供丰富精确的水深信息的同时,可阅读性与简洁美观度还得到了进一步的提升,完全能够满足制图的要求。
如图7所示,本发明还涉及基于网格的地形特征点提取方法的实体实现处理终端100,其包括,
存储器101,用于存储程序指令;
处理器102,用于运行所述程序指令,以执行所述基于网格的地形特征点提取方法的步骤。
本说明书所公开的实施例只是对本发明单方面特征的一个例证,本发明的保护范围不限于此实施例,其他任何功能等效的实施例均落入本发明的保护范围内。对于本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及变形,而所有的这些改变以及变形都应该属于本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!