一种红外和可见光图像的融合方法与流程
本发明属于图像处理技术领域,具体涉及一种红外和可见光图像的融合方法。
背景技术:
红外和可见光融合是图像融合技术的一个重要分支,红外技术已被广泛的应用于生物、医疗、军事及安防等领域。虽然红外图像能提供较好的热辐射信息帮助人们检测诊断,但是由于其分辨率较低、缺少大量的纹理信息使其在应用层面的价值大打折扣,因此人们希望利用图像融合技术将可见光图像的纹理空间信息注入到红外图像中使得融合图像既保留红外辐射信息又持有丰富的纹理信息,从而提高其应用价值。
目前最为常见的红外和可见光图像融合方法是基于多尺度变换的融合方法,它需要确定基函数和分解层次。然而如何灵活选择基函数使得源图像能够被最佳表示和如何自适应的选择分解层次仍然是待解决的问题。基于稀疏表示的融合方法采用基于块的方法,但是忽略了块间相关性,往往会导致细节信息的丢失。随着深度学习的兴起,许多基于深度学习的融合方法被提出,利用卷积神经网络(cnn)获得图像特征,并对融合后的图像进行重构。在这些基于cnn的融合方法中,一般性策略是利用特征提取网络的最后一层结果作为图像特征,这种策略会丢失网络中间层所包含的大量信息,影响融合结果。
香港理工大学zhetongliang等人提出混合l1-l0分解模型对基础层使用l1约束使得基础层可以保留较大梯度,且是分段光滑的,对细节层使用l0范数约束强制细节层的小纹理梯度为零,同时保持主要结构梯度不变,是一种鲁棒的层分解模型。自编码器是前馈非循环神经网络,具有非常好的提取数据特征表示的能力,利用编码器提取特征,利用解码器重构,天然的适合做特征级的融合实现。基于此,本发明提出基于混合l1-l0分解模型与自编码器的红外和可见光图像融合方法。
技术实现要素:
本发明的目的在于提供一种基于混合l1-l0分解模型与自编码器的红外和可见光图像融合方法,将热辐射信息和纹理信息的提取和融合拆分到不同网络中进行,使得融合策略更具有针对性,进而实现更好的融合效果。
本发明的技术方案为:一种红外和可见光图像的融合方法,包括以下步骤:
s1、获取训练数据集:采用混合l1-l0分解模型将网络输入图像s分解为基础层b和细节层s-b,作为训练数据集:
其中p表示像素点,n表示像素总数,
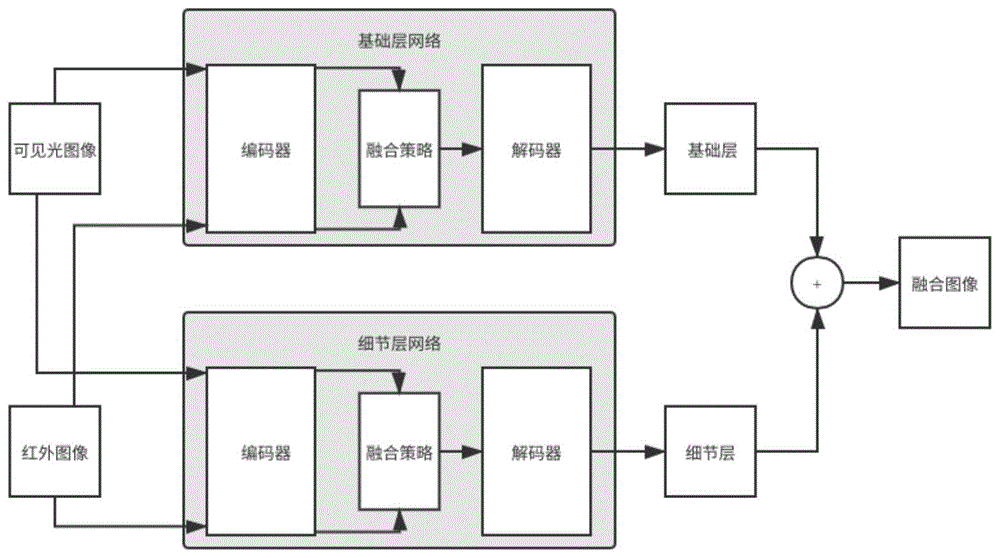
s2、构建自编码融合网络模型,如图1所示,具体为:
s11、自编码融合网络模型包括两个独立且结构相同的自编码器,分别定义为basenet和detailnet,如图2所示,自编码器的编码器由4层卷积层构成,卷积核大小都为(3,3),卷积核个数都为16,第一层卷积层后添加relu激活层,每层卷积层都会和后面所有卷积层作级联;自编码器的解码器由4层卷积层构成,卷积核大小都为(3,3),卷积核个数依次为64、32、16和1,前三层卷积层后添加relu激活层;为了避免信息损失,自编码器中不包含下采样层。
s12、构建损失函数,将图像s分别送入basenet和detailnet,得到对应的输出
其中
将
其中ssim表示结构相似度,它表示两图像的结构相似性。这种方式是对分层解码的一次校正,使得整体框架具有正常的解码功能;利用像素损失和结构损失构建最终损失函数:
loss=losspixel+λlossssim
其中λ为结构损失的权值参数,用以调整两项损失在训练过程中的数量级差异;
s3、采用训练数据集对构建的自编码融合网络模型进行训练,如图3所示,训练方法为通过反向传播算法最小化损失函数进行,获得训练好的自编码融合网络模型;
s4、将需要融合的红外和可见光图像送入训练好的自编码融合网络模型,即basenet和detailnet编码器,编码器对图像的分解如图4所示,从左至右依次为源图像、基础层、细节层,分别对basenet和detailnet提取的特征做特征融合,具体为:
s41、基础层特征融合,引入显著性检测得到红外图像的显著图sm,得到basenet的初步特征融合策略:
φm(x,y)=sm×φirm(x,y)+(1-sm)×φvism(x,y)
式中vis表示可见光图像,ir表示红外图像,其中
利用l1范数策略弥补显著性检测忽略的热辐射信息,修正basenet的特征融合策略;
l1范数融合策略:
其中
修正后的融合策略:
s42、细节层特征融合,采用加权平均融合策略融合detailnet特征:
其中
s5、将步骤s4得到的两层网络特征融合结果经各自的解码器解码后相加得到最终融合图像:
本发明的有益效果是:
本发明提供的基于混合l1-l0分解模型与自编码器的红外和可见光图像融合方法,使用混合l1-l0分解模型将图像分解结果作为双层自编码网络的输出,使得双层自编码网络自备层分解能力。将图像特征分解到基础层特征和细节层特征,对不同层次定制不同的融合策略能够保有更多的纹理信息和热辐射信息。利用l1范数策略补偿显著性检测忽略的热辐射信息,提高了基础层融合的鲁棒性。网络采用端到端的方式简化训练过程,降低了模型复杂度。通过矩阵运算,降低了特征融合处理时耗,进而提升融合框架的响应速度。
附图说明
图1为本发明的双层自编码融合网络模型结构示意图;
图2为本发明的自编码器结构示意图;
图3为本发明的基于混合l1-l0分解模型的训练框架示意图;
图4为本发明的双层自编码图像分解结果示意图;
图5为本发明最终融合结果图。
具体实施方式
在发明内容部分已经对本发明的方案进行了详细描述,下面结合测试以进一步证明本发明的实用性。
采用本发明的方案,对标准红外和可见光图像做融合测试,其部分融合结果如图5所示,从左至右依次为红外图像、可见光图像、融合图像;使用本发明的融合方法以及其他6种融合算法对20对标准红外和可见光融合测试图像做融合,使用信息熵、互信息和结构相似度等指标进行量化评估,结果如表1:
表1量化评估
测试表明,得益于分层融合思想和提出的融合策略,本发明的融合方法具有更好的融合效果与量化指标。
- 还没有人留言评论。精彩留言会获得点赞!