面向边缘服务器的高效任务调度方法、系统及电子设备
1.本发明涉及机器学习技术和深度学习的技术领域,具体涉及一种面向边缘服务器的高效任务调度方法、系统及电子设备。
背景技术:
2.云计算作为目前互联网企业提供的众多业务中最重要部分之一,可以根据用户的需求随时向其提供无限的计算资源,而用户只需要为使用的计算服务付费。同时,云数据中心还能够提供各种容器管理服务,资源池服务,托管服务等等。
3.然而近些年来随着5g技术和智能物联网(iiot)的飞速发展,诞生了大量的终端设备,据有关数据机构idc的统计于2020年底就有不下500亿的智能终端设备连入互联网。在这样的场景下,传统的云计算框架受限于地域、带宽等因素将无法满足这些海量设备对计算服务实时性的要求,出现数据传输慢、计算延迟高等一系列问题。特别是像vr游戏,无人驾驶,智能家居等对计算延迟要求非常高的计算任务让云计算框架变得不在适用。
4.为此,众多互联网企业提供了一套新的计算体系-云边端协同计算架构。该体系主张算力下沉,在云数据中心与智能终端之间添加了由众多边缘节点组成的边缘网络,拉近计算资源与客户的距离。与传统云计算框架不同,此架构下的智能终端不再需要将计算任务和数据全部上传到云端,只需通过部署在网络边缘的边缘节点就能快速处理计算任务,云端则只需要定期对众多边缘节点进行调度、管理、协同统一等工作,进而大幅度的减轻了网络带宽的压力,也大大降低了计算延迟。
5.尽管边缘服务器,例如华为atlas系列目前在理论上能够在降低计算服务延迟方面有很大的突破,但边缘服务器仍然因为其本身搭载的计算资源极度有限、计算资源利用率低、异构计算资源不能协同统一、边缘节点太多需要维护的人工成本高等原因,实际情况下还是会出现数据传输慢、计算延迟高等一系列问题。为此,近些年技术人员基于深度学习和强化学习技术提出了如优化服务器的资源利用率,计算任务的平均等待时间,服务器能耗等指标的任务调度模型来供服务器使用。例如电子科技大学提出的基于深度蒙特卡洛树搜索(dnn,mcts,lstm相互协作)的边缘计算任务分配方法,以支持边缘服务器对资源分配的优化;国防科技大学提出的一种强化学习的深度学习任务调度方法,面向深度学习多任务调度场景,基于任务在线性能反馈,自适应学习并调整调度策略;重庆工程学院提出的边缘计算的物联网深度学习及任务卸载调度策略,优化网络性能,保护数据上传中的用户隐私;陕西师范大学等单位合作提出的面向边缘设备的高能效深度学习任务调度策略,通过协同移动设备与边缘服务器,充分利用智能移动终端的便捷性和边缘服务器能力,完成深度学习模型在2种设备上的动态部署。
6.理论上,上述模型实现服务器性能升级的同时却忽略了这些模型过于复杂本身对机器的算力有着高要求和消耗。例如华为atlas200dk上仅仅只搭载了2张npu推理卡,如果调度程序本身就需要占用一张npu推理卡,那留给计算任务的计算资源就会非常紧张,仍然会造成计算任务计算延迟高的问题,而例如基于启发式学习的传统调度模型的性能又不能
满足边缘服务器的性能需求,这些问题都是边缘服务器所不能承担的。
技术实现要素:
7.本发明的主要目的在于克服现有技术的缺点与不足,提供一种面向边缘服务器的高效任务调度方法、系统及电子设备,在边缘服务器资源有限的条件下,无需特殊ai芯片的支持就能快速准确的完成任务调度和资源分配,提高边缘服务器计算资源的利用率。
8.为了达到上述目的,本发明采用以下技术方案:
9.本发明一方面提供了一种面向边缘服务器的高效任务调度方法,包括下述步骤:
10.当计算任务队列传输到调度程序时,提前获取当前任务队列中每个计算任务的属性特征信息job以及当前边缘服务器的环境信息cluster,所述属性特征信息job包括:计算任务在不同计算芯片上运行的时间、计算任务在不同芯片上运行所造成的能耗、计算任务在不同芯片上运行所需要的内存大小以及计算任务在不同芯片上运行所需要的计算节点个数;所述环境信息cluster包括:服务器上不同计算芯片的空闲计算节点、服务器上不同计算芯片的空闲内存以及服务器当前时间段的能耗;
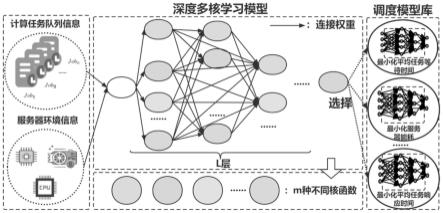
11.将任务队列中的每个任务的属性特征信息job进行统计得出的值x1与服务器环境信息的值x2作为预先设立的深度多核学习模型m的输入值x,其中x={x1,x2};所述预先设立的深度多核学习模型m的拓扑结构呈网络状,由输入层、l层隐层以及输出层组成,每一层隐层最多包含了m个基础核函数,所述基础核函数用于计算从上层以及之前层传来的数据,并将计算结果输出给后续隐层;输出层为基于m个基础核函数中的某一个核函数训练而成的svm分类器,由前往后,基础核函数之间带权重相连,并存在跨层连接;
12.将输入值x输入到所述深度多核学习模型m进行分类,该深度多核学习模型m的输出为调度模型库中最适合当前环境下的最优任务调度模型best
model
;
13.将当前任务队列的调度任务属性特征信息job输入到最优任务调度模型best
model
,完成当前计算任务的调度工作。
14.优选的,所述任务队列中的每个任务的属性特征信息job进行统计得出的值x1包括:
15.任务队列中所有任务在不同芯片上单独运行所造成的能耗平均值avge,最大值maxe,方差vare;
16.任务队列中所有任务在不同芯片上所需要的计算节点平均值avgn,最大值maxn,方差varn;
17.任务队列中所有任务在不同芯片上所需要的计算内存平均值avgm,最大值maxm,方差varm。
18.优选的,所述基础核函数包括线性核函数、高斯核函数、多项式核函数和sigmoid核函数。
19.优选的,所述调度模型库通过预先训练建立,基于启发式学习、传统机器学习以及轻量级神经网络针对边缘服务器环境信息cluster和属性特征信息job训练出各种轻量级调度模型,形成调度模型库。
20.优选的,所述针对边缘服务器环境信息cluster和属性特征信息job训练出各种调度模型,其中训练目标主要为:
21.最小化平均任务等待时间wait、最小化服务器能耗energy、最小化平均任务响应时间response以及最大化服务器资源利用率usage。
22.优选的,所述深度多核学习模型m为预先训练好的,训练方式如下:
23.(1)将服务器的历史任务队列数据统计形成训练数据history
x
={x1,x2,x3,
…
,xh},其中h为历史数据的个数,表示h个时段;
24.(2)通过人为判断从调度模型库中选择最适合xi的调度模型,并将其序号作为标签yi对应出每一个时段的数据xi,形成标签historyy={y1,y2,y3,
…
,yh};
25.(3)将history
x
与historyy作为深度多核学习模型的训练数据;
26.(4)网络中的每个基础核函数的参数优化,采取网格搜索和随机搜索的方式;
27.(5)通过遗传算法对深度多核学习模型的拓扑结构和网络连接权重进行优化;
28.(6)生成模型。
29.优选的,最适合当前任务队列信息和服务器环境信息的任务调度模型序号的采用评分的方式,评分准则如下所示:
30.score=λ1wait+λ2energy+λ3response+λ4usage
31.λ1+λ2+λ3+λ4=1.0
32.其中参数λ
1-λ4通过具体服务器本身的硬件状态和计算任务对计算时延的硬性要求作为约束。
33.优选的,所述通过遗传算法对深度多核学习模型的拓扑结构和网络连接权重进行优化,包括下述步骤:
34.随机生成1个m
×
(l-1)位的二进制数对应模型拓扑结构,1和0分别代表相应层数对应的核函数是否被激活,激活则表示该核函数参与计算,没有激活则表示该层没有这个核函数;
35.根据所述的拓扑结构随机生成p组权重;
36.通过选择、变异、交叉方式对p组权重进行优化,找到对应拓扑结构的最优权重;
37.重复随机生成n个拓扑结构带不同最优权重的模型model;
38.再次通过选择、变异、交叉方式对model进行优化,得到拓扑结构最优,权重最优的模型。
39.本发明又一方面提供了一种面向边缘服务器的高效任务调度系统,应用于所述的面向边缘服务器的高效任务调度方法,包括获取信息模块、深度多核学习模块、最优调度模块、以及生成调度模块;
40.所述获取信息模块,用于当计算任务队列传输到调度程序时,提前获取当前任务队列中每个计算任务的属性特征信息job以及当前边缘服务器的环境信息cluster,所述属性特征信息job包括:计算任务在不同计算芯片上运行的时间、计算任务在不同芯片上运行所造成的能耗、计算任务在不同芯片上运行所需要的内存大小以及计算任务在不同芯片上运行所需要的计算节点个数;所述环境信息cluster包括:服务器上不同计算芯片的空闲计算节点、服务器上不同计算芯片的空闲内存以及服务器当前时间段的能耗;
41.所述深度多核学习模块,用于将任务队列中的每个任务的属性特征信息job进行统计得出的值x1与服务器环境信息的值x2作为预先设立的深度多核学习模型m的输入值x,其中x={x1,x2};所述预先设立的深度多核学习模型m的拓扑结构呈网络状,由输入层、l层
隐层以及输出层组成,每一层隐层最多包含了m个基础核函数,所述基础核函数用于计算从上层以及之前层传来的数据,并将计算结果输出给后续隐层;输出层为基于m个基础核函数中的某一个核函数训练而成的svm分类器,由前往后,基础核函数之间带权重相连,并存在跨层连接;
42.所述最优调度模块,用于输入值x输入到所述深度多核学习模型m进行分类,该深度多核学习模型m的输出为调度模型库中最适合当前环境下的最优任务调度模型best
model
;
43.所述生成调度模块,用于将当前任务队列的调度任务属性特征信息job输入到最优任务调度模型best
model
,完成当前计算任务的调度工作。
44.本发明又一方面提供了一种电子设备,其特征在于,所述电子设备包括:
45.至少一个处理器;以及,
46.与所述至少一个处理器通信连接的存储器;其中,
47.所述存储器存储有可被所述至少一个处理器执行的计算机程序指令,所述计算机程序指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行所述的面向边缘服务器的高效任务调度方法。
48.本发明的有益效果是:
49.本发明提出的一种面向边缘服务器的高效任务调度方法,利用深度多核学习模型m对模型库的调度模型进行选择,在边缘服务器计算资源有限的情况下,不占用边缘服务器的高算力推理卡,进一步提升边缘服务器的计算资源利用率,降低服务器能耗等指标,推进云边端计算体系的发展;另外,本发明深度多核学习模型m相较于普通的深度神经网络,无需大量的训练样本、不需要特殊计算芯片的支持、能够对网络结构进行自我训练和优化,面对不复杂的样本分布时能快速的计算并保持和深度神经网络一样的优越性能,在不和计算任务争抢高算力计算资源的情况下,实现边缘服务器性能的进一步突破。
附图说明
50.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
51.图1为本发明实施例面向边缘服务器的高效任务调度模型示意图。
52.图2为本发明实施例面向边缘服务器的高效任务调度方法的任务和服务器属性信息示意图。
53.图3为本发明实施例面向边缘服务器的高效任务调度方法的整体流程图。
54.图4为本发明实施例面向边缘服务器的高效任务调度方法网络模型的拓扑结构设计与权重设置示意图。
55.图5为本发明实施例面向边缘服务器的高效任务调度方法网络模型拓扑结构优化示意图。
56.图6为本发明实施例面向边缘服务器的高效任务调度方法前期模型的准备流程图。
57.图7为本发明实施例面向边缘服务器的高效任务调度系统的构成示意图。
58.图8为本发明实施例电子设备的结构图。
具体实施方式
59.为了使本技术领域的人员更好地理解本技术方案,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行详细地描述。对于本发明实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定。基于本技术中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
60.在本技术中提及“实施例”意味着,结合实施例描述的特定特征、结构或特性可以包含在本技术的至少一个实施例中。在说明书中的各个位置出现该短语并不一定均是指相同的实施例,也不是与其它实施例互斥的独立的或备选的实施例。本领域技术人员显式地和隐式地理解的是,本技术所描述的实施例可以与其它实施例相结合。
61.如图1所示、图3所示,本技术的一个实施例中提供了一种面向边缘服务器的高效任务调度方法,包括下述步骤:
62.s1、当计算任务队列传输到调度程序时,提前获取当前任务队列中每个计算任务的属性特征信息job以及当前边缘服务器的环境信息cluster,所述属性特征信息job包括:计算任务在不同计算芯片上运行的时间、计算任务在不同芯片上运行所造成的能耗、计算任务在不同芯片上运行所需要的内存大小以及计算任务在不同芯片上运行所需要的计算节点个数;所述环境信息cluster包括:服务器上不同计算芯片的空闲计算节点、服务器上不同计算芯片的空闲内存以及服务器当前时间段的能耗,如图2所示。
63.s2、将任务队列中的每个任务的属性特征信息job进行统计得出的值x1与服务器环境信息的值x2作为预先设立的深度多核学习模型m的输入值x,其中x={x1,x2};所述预先设立的深度多核学习模型m的拓扑结构呈网络状,由输入层、l层隐层以及输出层组成,每一层隐层最多包含了m个基础核函数,所述基础核函数用于计算从上层以及之前层传来的数据,并将计算结果输出给后续隐层;输出层为基于m个基础核函数中的某一个核函数训练而成的svm分类器,由前往后,基础核函数之间带权重相连,并存在跨层连接。
64.进一步的,所述任务队列中的每个任务的属性特征信息job进行统计得出的值x1包括:
65.任务队列中所有任务在不同芯片上单独运行所造成的能耗平均值avge,最大值maxe,方差vare;
66.任务队列中所有任务在不同芯片上所需要的计算节点平均值avgn,最大值maxn,方差varn;
67.任务队列中所有任务在不同芯片上所需要的计算内存平均值avgm,最大值maxm,方差varm。
68.更进一步的,所述基础核函数包括线性核函数、高斯核函数、多项式核函数和sigmoid核函数,具体公式如下:
69.lineark(x,y)=x
ty70.rbf
71.polyk(x,y)=(ax
t
y+c)d72.sigmoidk(x,y)=tanh(ax
t
y+c)
73.s3、将输入值x输入到所述深度多核学习模型m进行分类,该深度多核学习模型m的输出为调度模型库中最适合当前环境下的最优任务调度模型best
model
。
74.进一步的,所述调度模型库通过预先训练建立,基于启发式学习、传统机器学习以及轻量级神经网络针对边缘服务器环境信息cluster和属性特征信息job训练出各种轻量级调度模型,形成调度模型库。
75.更进一步的,所述针对边缘服务器环境信息cluster和属性特征信息job训练出各种调度模型,其中训练目标主要为:
76.最小化平均任务等待时间wait、最小化服务器能耗energy、最小化平均任务响应时间response以及最大化服务器资源利用率usage。
77.具体的,所述深度多核学习模型m为预先训练好的,训练方式如下:
78.(1)将服务器的历史任务队列数据统计形成训练数据history
x
={x1,x2,x3,
…
,xh},其中h为历史数据的个数,表示h个时段;
79.(2)通过人为判断从调度模型库中选择最适合xi的调度模型,并将其序号作为标签yi对应出每一个时段的数据xi,形成标签historyy={y1,y2,y3,
…
,yh};
80.(3)将history
x
与historyy作为深度多核学习模型的训练数据;
81.(4)网络中的每个基础核函数的参数优化,采取网格搜索和随机搜索的方式;
82.(5)通过遗传算法对深度多核学习模型的拓扑结构和网络连接权重进行优化;
83.(6)生成模型。
84.所述最适合当前任务队列信息和服务器环境信息的任务调度模型序号的采用评分的方式,评分准则如下所示:
85.score=λ1wait+λ2energy+λ3response+λ4usage
86.λ1+λ2+λ3+λ4=1.0
87.其中参数λ
1-λ4通过具体服务器本身的硬件状态和计算任务对计算时延的硬性要求作为约束。
88.所述通过遗传算法对深度多核学习模型的拓扑结构和网络连接权重进行优化,包括下述步骤:
89.随机生成1个m
×
(l-1)位的二进制数对应模型拓扑结构,1和0分别代表相应层数对应的核函数是否被激活,激活则表示该核函数参与计算,没有激活则表示该层没有这个核函数;
90.根据所述的拓扑结构随机生成p组权重,如图4所示;
91.通过选择、变异、交叉方式对p组权重进行优化,找到对应拓扑结构的最优权重;
92.重复随机生成n个拓扑结构带不同最优权重的模型model;
93.再次通过选择、变异、交叉方式对model进行优化,得到拓扑结构最优,权重最优的模型,如图5所示。
94.s4、将当前任务队列的调度任务属性特征信息job输入到最优任务调度模型best
model
,完成当前计算任务的调度工作。
95.如图6所示,在本技术的另一实施例中,提供了一种面向边缘服务器的高效任务调
度方法在atlas200dk边缘设备上的实现,包括下述步骤:
96.s1、提前在atlas200dk上部署自动获取不同计算任务在npu和cpu运行时所产生的属性特征信息job以及不同时间段服务器环境信息cluster的脚本。
97.s2、随机生成各种不同计算任务在atlas200dk上运行,并通过脚本获取到历史数据信息trace。
98.s3、基于启发式学习、传统机器学习以及轻量级神经网络算法针对历史数据信息trace中边缘服务器环境信息cluster和计算任务属性特征信息job使用cpu训练各种调度模型,形成调度模型库。
99.s4、设置深度多核学习模型m的自动训练脚本,确定m个基础核函数,以及隐层的l层的大小,剩下的参数都由进化算法自动得到。
100.s5、基于历史数据trace统计的数据信息,调度模型库与自动训练脚本通过cpu训练出深度多核学习模型m。
101.s6、由于历史数据信息trace的获得和深度多核学习模型的训练都有自动脚本的存在且训练过程无需ai芯片的支持,因此深度多核学习模型可以在不用人工干预、不占用有限ai计算芯片的情况下,不干扰其他计算任务而定期进行自动训练更新模型,至此,前期模型的准备工作完成。
102.s7、当计算任务队列传输到调度程序时,提前获取当前任务队列中每个计算任务的属性特征信息job以及当前atlas200dk边缘设备环境信息cluster,所述的属性特征信息包括:计算任务分别在cpu,npu芯片上运行的时间、计算任务分别在cpu,npu芯片上运行所造成的能耗、计算任务分别在cpu,npu芯片上运行所需要的内存大小以及计算任务分别在cpu,npu芯片上运行所需要的计算节点个数;所述的边缘服务器环境信息包括:atlas200dk上两块npu与cpu的空闲计算节点、空闲内存以及当前时间段的能耗。
103.s8、将任务队列中的每个任务的属性特征矩阵job进行统计得出的值x1与服务器信息的值x2作为预先设立的深度多核学习模型m的输入值x={x1,x2};所述预先设立的深度多核学习模型m的拓扑结构呈网络状,由输入层、l层隐层以及输出层组成,每一层隐层最多包含了m个基础核函数,所述基础核函数用于计算从上层以及之前层传来的数据,并将计算结果输出给后续隐层;输出层为基于m个基础核函数中的某一个核函数训练而成的svm分类器,由前往后,基础核函数之间带权重相连,并存在跨层连接。
104.进一步的,所述任务队列中的每个任务的属性特征信息job进行统计得出的值x1包括:
105.任务队列中所有任务在cpu,npu上运行所造成的能耗平均值avge,最大值maxe,方差vare;
106.任务队列中所有任务在cpu,npu上所需要的计算节点平均值avgn,最大值maxn,方差varn;
107.任务队列中所有任务在cpu,npu上所需要的计算内存平均值avgm,最大值maxm,方差varm。
108.更进一步的,所述基础核函数包括线性核函数、高斯核函数、多项式核函数和sigmoid核函数,具体公式如下:
109.lineark(x,y)=x
ty110.rbf
111.polyk(x,y)=(ax
t
y+c)d112.sigmoidk(x,y)=tanh(ax
t
y+c)
113.s9、将输入值x输入到深度多核学习模型m进行分类,该深度多核学习模型的输出为调度模型库中最适合当前环境下的任务调度模型best
model
。
114.进一步的,所述调度模型库通过预先训练建立,基于启发式学习、传统机器学习以及轻量级神经网络针对边缘服务器环境信息cluster和属性特征信息job训练出各种轻量级调度模型,形成调度模型库。
115.更进一步的,所述针对边缘服务器环境信息cluster和属性特征信息job训练出各种调度模型,其中训练目标主要为:
116.最小化平均任务等待时间wait、最小化服务器能耗energy、最小化平均任务响应时间response以及最大化服务器资源利用率usage。
117.具体的,所述深度多核学习模型m为预先训练好的,训练方式如下:
118.(1)将服务器的历史任务队列数据统计形成训练数据history
x
={x1,x2,x3,
…
,xh},其中h为历史数据的个数,表示h个时段;
119.(2)通过人为判断从调度模型库中选择最适合xi的调度模型,并将其序号作为标签yi对应出每一个时段的数据xi,形成标签historyy={y1,y2,y3,
…
,yh};
120.(3)将history
x
与historyy作为深度多核学习模型的训练数据;
121.(4)网络中的每个基础核函数的参数优化,采取网格搜索和随机搜索的方式;
122.(5)通过遗传算法对深度多核学习模型的拓扑结构和网络连接权重进行优化;
123.(6)生成模型。
124.所述最适合当前任务队列信息和服务器环境信息的任务调度模型序号的采用评分的方式,评分准则如下所示:
125.score=λ1wait+λ2energy+λ3response+λ4usage
126.λ1+λ2+λ3+λ4=1.0
127.其中参数λ
1-λ4通过具体服务器本身的硬件状态和计算任务对计算时延的硬性要求作为约束。
128.所述通过遗传算法对深度多核学习模型的拓扑结构和网络连接权重进行优化,包括下述步骤:
129.随机生成1个m
×
(l-1)位的二进制数对应模型拓扑结构,1和0分别代表相应层数对应的核函数是否被激活,激活则表示该核函数参与计算,没有激活则表示该层没有这个核函数;
130.根据所述的拓扑结构随机生成p组权重;
131.通过选择、变异、交叉方式对p组权重进行优化,找到对应拓扑结构的最优权重;
132.重复随机生成个拓扑结构带不同最优权重的模型model;
133.再次通过选择、变异、交叉方式对model进行优化,得到拓扑结构最优,权重最优的模型。
134.s10、将当前任务队列的调度任务属性特征信息job输入到最优任务调度模型
best
model
,生成调度策略,完成当前计算任务的调度工作,提升边缘服务器的计算资源利用率,降低服务器能耗等指标的同时降低计算任务的反馈时延。
135.本发明又一实施例中还提供了一种在atlas200dk与浪潮边缘计算服务器ne5260m5两台边缘设备上使用一种面向边缘服务器的高任务调度方法进行协同调度,包括下述步骤:
136.s1、提前在atlas200dk,ne5260m5上部署自动获取不同计算任务在npu、gpu和cpu运行时所产生的属性特征信息job以及不同时间段服务器环境信息cluster的脚本。
137.s2、随机生成各种不同计算任务在atlas200dk,ne5260m5上运行,并通过脚本获取到历史数据信息trace。
138.s3、基于启发式学习、传统机器学习以及轻量级神经网络算法针对历史数据信息trace中边缘服务器环境信息cluster和计算任务属性特征信息job使用cpu训练各种调度模型,形成调度模型库。
139.s4、设置深度多核学习模型m的自动训练脚本,确定m个基础核函数,以及隐层的l层的大小,剩下的参数都由进化算法自动得到。
140.s5、基于历史数据trace统计的数据信息与调度模型库与自动训练脚本通过cpu训练出深度多核学习模型m。
141.s6、由于历史数据信息trace的获得和深度多核学习模型的训练都有自动脚本的存在且训练过程无需ai芯片的支持,因此深度多核学习模型可以在不用人工干预、不占用有限ai计算芯片的情况下,不干扰其他计算任务而定期进行自动训练更新模型,至此前期模型的准备工作完成。
142.s7、当计算任务队列传输到调度程序时,提前获取当前任务队列中每个计算任务的属性特征信息job以及当前atlas200dk,ne5260m5两台边缘设备环境信息cluster,所述的属性特征信息job包括:计算任务分别在cpu,npu,gpu芯片上运行的时间、计算任务分别在cpu,npu,gpu芯片上运行所造成的能耗、计算任务分别在cpu,npu,gpu芯片上运行所需要的内存大小、运行所需要的计算节点个数;所述的边缘服务器环境信息cluster包括:atlas200dk上两块npu,ne5260m5上两块gpu与cpu上的空闲计算节点、空闲内存、当前时间段的能耗。
143.s8、将任务队列中的每个任务的属性特征信息job进行统计得出的值x1与服务器环境信息的值x2作为预先设立的深度多核学习模型m的输入值x,其中x={x1,x2};所述预先设立的深度多核学习模型m的拓扑结构呈网络状,由输入层、l层隐层以及输出层组成,每一层隐层最多包含了m个基础核函数,所述基础核函数用于计算从上层以及之前层传来的数据,并将计算结果输出给后续隐层;输出层为基于m个基础核函数中的某一个核函数训练而成的svm分类器,由前往后,基础核函数之间带权重相连,并存在跨层连接。
144.进一步的,所述任务队列中的每个任务的属性特征信息job进行统计得出的值x1包括:
145.任务队列中所有任务在不同芯片上单独运行所造成的能耗平均值avge,最大值maxe,方差vare;
146.任务队列中所有任务在不同芯片上所需要的计算节点平均值avgn,最大值maxn,方差varn;
147.任务队列中所有任务在不同芯片上所需要的计算内存平均值avgm,最大值maxm,方差varm。
148.更进一步的,所述基础核函数包括线性核函数、高斯核函数、多项式核函数和sigmoid核函数,具体公式如下:
149.lineark(x,y)=x
ty150.rbf
151.polyk(x,y)=(ax
t
y+c)d152.sigmoidk(x,y)=tanh(ax
t
y+c)
153.s9、将输入x输入到一种深度多核学习模型m进行分类,其模型的输出为调度模型库中最适合当前环境下的任务调度模型best
model
。
154.进一步的,所述调度模型库通过预先训练建立,以两台边缘服务器的计算资源作为一个资源池进行训练,基于启发式学习、传统机器学习以及轻量级神经网络针对边缘服务器环境信息cluster和属性特征信息job训练出各种轻量级调度模型,形成调度模型库。
155.更进一步的,所述针对边缘服务器环境信息cluster和属性特征信息job训练出各种调度模型,其中训练目标主要为:
156.最小化平均任务等待时间wait、最小化服务器能耗energy、最小化平均任务响应时间response以及最大化服务器资源利用率usage。
157.具体的,所述深度多核学习模型m为预先训练好的,训练方式如下:
158.(1)将服务器的历史任务队列数据统计形成训练数据history
x
={x1,x2,x3,
…
,xh},其中h为历史数据的个数,表示h个时段;
159.(2)通过人为判断从调度模型库中选择最适合xi的调度模型,并将其序号作为标签yi对应出每一个时段的数据xi,形成标签historyy={y1,y2,y3,
…
,yh};
160.(3)将history
x
与historyy作为深度多核学习模型的训练数据;
161.(4)网络中的每个基础核函数的参数优化,采取网格搜索和随机搜索的方式;
162.(5)通过遗传算法对深度多核学习模型的拓扑结构和网络连接权重进行优化;
163.(6)生成模型。
164.所述最适合当前任务队列信息和服务器环境信息的任务调度模型序号的采用评分的方式,评分准则如下所示:
165.score=λ1wait+λ2energy+λ3response+λ4usage
166.λ1+λ2+λ3+λ4=1.0
167.其中参数λ
1-λ4通过具体服务器本身的硬件状态和计算任务对计算时延的硬性要求作为约束。
168.所述通过遗传算法对深度多核学习模型的拓扑结构和网络连接权重进行优化,包括下述步骤:
169.随机生成1个m
×
(l-1)位的二进制数对应模型拓扑结构,1和0分别代表相应层数对应的核函数是否被激活,激活则表示该核函数参与计算,没有激活则表示该层没有这个核函数;
170.根据所述的拓扑结构随机生成p组权重,如图4所示;
171.通过选择、变异、交叉方式对p组权重进行优化,找到对应拓扑结构的最优权重;
172.重复随机生成n个拓扑结构带不同最优权重的模型model;
173.再次通过选择、变异、交叉方式对model进行优化,得到拓扑结构最优,权重最优的模型。
174.s10、将当前任务队列的调度任务属性特征信息job输入到最优任务调度模型best
model
,完成当前计算任务的调度工作;提升边缘服务器的计算资源利用率,降低服务器能耗等指标的同时降低计算任务的反馈时延。
175.基于与上述实施例中的一种面向边缘服务器的高效任务调度方法相同的思想,本发明还提供了一种面向边缘服务器的高效任务调度系统,该系统可用于执行上述一种面向边缘服务器的高效任务调度方法。为了便于说明,一种面向边缘服务器的高效任务调度系统实施例的结构示意图中,仅仅示出了与本发明实施例相关的部分,本领域技术人员可以理解,图示结构并不构成对装置的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
176.如图7所示,在本技术的一个实施例中,提供了一种面向边缘服务器的高效任务调度系统100,该系统包括获取信息模块101、深度多核学习模块102、最优调度模块103、以及生成调度模块104;
177.所述获取信息模块101,用于当计算任务队列传输到调度程序时,提前获取当前任务队列中每个计算任务的属性特征信息job以及当前边缘服务器的环境信息cluster,所述属性特征信息job包括:计算任务在不同计算芯片上运行的时间、计算任务在不同芯片上运行所造成的能耗、计算任务在不同芯片上运行所需要的内存大小以及计算任务在不同芯片上运行所需要的计算节点个数;所述环境信息cluster包括:服务器上不同计算芯片的空闲计算节点、服务器上不同计算芯片的空闲内存以及服务器当前时间段的能耗;
178.所述深度多核学习模块102,用于将任务队列中的每个任务的属性特征信息job进行统计得出的值x1与服务器环境信息的值x2作为预先设立的深度多核学习模型m的输入值x,其中x={x1,x2};所述预先设立的深度多核学习模型m的拓扑结构呈网络状,由输入层、l层隐层以及输出层组成,每一层隐层最多包含了m个基础核函数,所述基础核函数用于计算从上层以及之前层传来的数据,并将计算结果输出给后续隐层;输出层为基于m个基础核函数中的某一个核函数训练而成的svm分类器,由前往后,基础核函数之间带权重相连,并存在跨层连接;
179.所述最优调度模块103,用于输入值x输入到所述深度多核学习模型m进行分类,该深度多核学习模型m的输出为调度模型库中最适合当前环境下的最优任务调度模型best
model
;
180.所述生成调度模块104,用于将当前任务队列的调度任务属性特征信息job输入到最优任务调度模型best
model
,完成当前计算任务的调度工作。
181.需要说明的是,本发明的一种面向边缘服务器的高效任务调度系统与本发明的一种面向边缘服务器的高效任务调度方法一一对应,在上述一种面向边缘服务器的高效任务调度方法的实施例阐述的技术特征及其有益效果均适用于一种面向边缘服务器的高效任务调度系统的实施例中,具体内容可参见本发明方法实施例中的叙述,此处不再赘述,特此声明。
182.此外,上述实施例的一种面向边缘服务器的高效任务调度系统的实施方式中,各程序模块的逻辑划分仅是举例说明,实际应用中可以根据需要,例如出于相应硬件的配置要求或者软件的实现的便利考虑,将上述功能分配由不同的程序模块完成,即将一种面向边缘服务器的高效任务调度系统的内部结构划分成不同的程序模块,以完成以上描述的全部或者部分功能。
183.如图8所示,在一个实施例中,提供了一种面向边缘服务器的高效任务调度方法的电子设备,所述电子设备200可以包括第一处理器201、第一存储器202和总线,还可以包括存储在所述第一存储器202中并可在所述第一处理器201上运行的计算机程序,如高效任务调度学习程序203。
184.其中,所述第一存储器202至少包括一种类型的可读存储介质,所述可读存储介质包括闪存、移动硬盘、多媒体卡、卡型存储器(例如:sd或dx存储器等)、磁性存储器、磁盘、光盘等。所述第一存储器202在一些实施例中可以是电子设备200的内部存储单元,例如该电子设备200的移动硬盘。所述第一存储器202在另一些实施例中也可以是电子设备200的外部存储设备,例如电子设备200上配备的插接式移动硬盘、智能存储卡(smart media card,smc)、安全数字(securedigital,sd)卡、闪存卡(flash card)等。进一步地,所述第一存储器202还可以既包括电子设备200的内部存储单元也包括外部存储设备。所述第一存储器202不仅可以用于存储安装于电子设备200的应用软件及各类数据,例如高效任务调度程序203的代码等,还可以用于暂时地存储已经输出或者将要输出的数据。
185.所述第一处理器201在一些实施例中可以由集成电路组成,例如可以由单个封装的集成电路所组成,也可以是由多个相同功能或不同功能封装的集成电路所组成,包括一个或者多个中央处理器(central processing unit,cpu)、微处理器、数字处理芯片、图形处理器及各种控制芯片的组合等。所述第一处理器201是所述电子设备的控制核心(control unit),利用各种接口和线路连接整个电子设备的各个部件,通过运行或执行存储在所述第一存储器202内的程序或者模块,以及调用存储在所述第一存储器202内的数据,以执行电子设备200的各种功能和处理数据。
186.图8仅示出了具有部件的电子设备,本领域技术人员可以理解的是,图8示出的结构并不构成对所述电子设备200的限定,可以包括比图示更少或者更多的部件,或者组合某些部件,或者不同的部件布置。
187.所述电子设备200中的所述第一存储器202存储的高效任务调度程序203是多个指令的组合,在所述第一处理器201中运行时,可以实现:
188.当计算任务队列传输到调度程序时,提前获取当前任务队列中每个计算任务的属性特征信息以及当前边缘服务器的环境信息cluster,所述属性特征信息job包括:计算任务在不同计算芯片上运行的时间、计算任务在不同芯片上运行所造成的能耗、计算任务在不同芯片上运行所需要的内存大小以及计算任务在不同芯片上运行所需要的计算节点个数;所述环境信息cluster包括:服务器上不同计算芯片的空闲计算节点、服务器上不同计算芯片的空闲内存以及服务器当前时间段的能耗;
189.将任务队列中的每个任务的属性特征信息job进行统计得出的值x1与服务器环境信息的值x2作为预先设立的深度多核学习模型m的输入值x,其中x={x1,x2};所述预先设立的深度多核学习模型m的拓扑结构呈网络状,由输入层、l层隐层以及输出层组成,每一层隐
层最多包含了m个基础核函数,所述基础核函数用于计算从上层以及之前层传来的数据,并将计算结果输出给后续隐层;输出层为基于m个基础核函数中的某一个核函数训练而成的svm分类器,由前往后,基础核函数之间带权重相连,并存在跨层连接;
190.将输入值x输入到所述深度多核学习模型m进行分类,该深度多核学习模型m的输出为调度模型库中最适合当前环境下的最优任务调度模型best
model
;
191.将当前任务队列的调度任务属性特征信息job输入到最优任务调度模型best
model
,完成当前计算任务的调度工作。
192.进一步地,所述电子设备200集成的模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个非易失性计算机可读取存储介质中。所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、u盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(rom,read-only memory)。
193.本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一非易失性计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以多种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(synchlink)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
194.以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
195.以上是对本发明的较佳实施进行了具体说明,但本发明并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本技术权利要求所限定的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1