一种融合词汇边界及语义信息的实体识别及关系抽取方法
1.本发明涉及自然语言处理技术领域,尤其涉及一种融合词汇边界及语义信息的实体识别及关系抽取方法。
背景技术:
2.实体识别和关系抽取作为自然语言处理中的重要任务,负责从自然语言文本中识别出实体,并抽取实体之间的语义关系。
3.基于深度学习的流水线方法下的实体识别及关系抽取,是指先识别出句子中多个不同的实体,再将识别出的实体分别组合进行关系类型判断,前后两个过程完全分离;此类方法存在误差积累、实体冗余,交互缺失等问题,而基于联合抽取的方式可以有效缓解这些问题。
4.对于嵌套实体的情况,基于片段排列的方式,显示的提取所有可能的片段排列,由于选择的每一个片段都是独立的,因此可以直接提取片段级别的特征去解决该问题。
技术实现要素:
5.针对现有算法的不足,本发明考虑到实体识别模型和关系抽取模型的输出之间存在着一定的约束,采用联合抽取的方式识别实体和实体对之间的语义关系;并融入词汇边界以及相关语义信息,充分利用语句中不同词语之间的位置关系信息,同时通过输入预训练语言模型前将样本语句组合待预测实体片段的形式,一次可同时识别多个待预测实体片段,提高模型计算效率,另外基于片段分类的形式,能有效解决实体嵌套的情况;利用实体识别及关系抽取方法,能够高效地识别出实体及其类型,并且准确地揭示出实体之间的语义关系,为构建知识图谱、智能问答系统等提供有效辅助。
6.本发明所采用的技术方案是:一种融合词汇边界及语义信息的实体识别及关系抽取方法包括以下步骤:
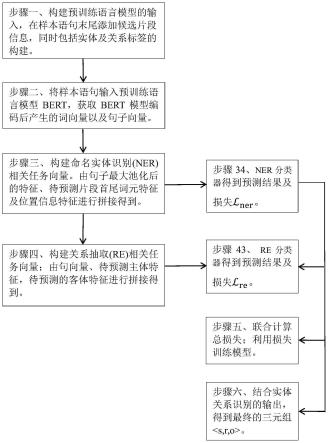
7.步骤一、构建预处理语言模型的样本输入及标签;
8.进一步的,具体包括:
9.步骤11、将文本语句进行分词,分词后的文本语句添加[cls]符号得到序列{[cls],t1,t2,t3,ti...,tn};其中,ti表示为文本语句经过分词后得到的词元token;
[0010]
步骤12、文本语句结尾组合m个待预测片段表示为{[cls];t1,t2,t3,...,tn;s1,s1,...,s1;s1,s2,s3,...,sm};其中,{s1,s1,...,s1}表示添加的待预测片段的首位置信息,{s1,s2,s3,...,sm}表示添加的待预测片段的尾位置信息,直到遍历所有的片段位置信息s1~sn,添加的待预测片段的位置信息与文本中对应的词元共享位置信息,一共得到z条拼接的待预测片段;
[0011]
进一步的,z条拼接的待预测片段的计算公式为:
[0012]
[0013]
其中,l表示待预测片段的长度,n表示分词后的文本语句中共包含n个词元。
[0014]
步骤13、构造实体标签及关系标签,实体标签由实体边界信息以及实体类型标签信息组成,关系标签包括主客实体对的边界信息以及关系类型标签组成;
[0015]
步骤二、将样本输入预训练bert模型,通过bert模型输出最后一层的特征向量;
[0016]
进一步的,特征向量包含词向量和句向量。
[0017]
步骤三、构建实体识别任务的任务特征向量由句子最大池化后的特征、预测片段边界词元特征、及样本末尾拼接的边界特征进行拼接得到,特征向量送入ner分类器得到分类结果并计算损失
[0018]
进一步的,具体包括:
[0019]
步骤31、将词向量特征信息进行最大池化得到hm,计算公式为:
[0020]hm
=maxpooling(h1,h2,...,hn);
[0021]
步骤32、对部分特征向量进行拼接得到任务特征计算公式为:
[0022][0023]
其中,cat表示concatenate操作,hi表示预测实体片段的首位置信息特征,hj表示预测实体片段的尾位置信息特征,表示为样本末尾添加的待预测片段的首位置信息特征,表示为样本末尾添加的待预测片段的尾位置信息特征,通过组合一次识别m个候选片段;
[0024]
步骤33、将送入ner分类器,得到实体类型为k的预测结果公式为:
[0025][0026]
其中,we,be表示为实体抽取和关系抽取的任务模型的可训练参数,k表示为实体的类型,ε表示为实体类型集合;
[0027]
步骤34、计算ner部分的交叉熵损失公式为:
[0028][0029]
其中,n表示样本数量,y
ij
表示是否为当前类别。
[0030]
步骤四、构建关系抽取任务相关的任务特征向量由句向量、待预测主体片段的边界特征、待预测的客体片段的边界特征特征进行拼接得到,送入re分类器得到分类结果并计算损失
[0031]
进一步的,具体包括:
[0032]
步骤41、对部分特征向量进行拼接得到任务特征计算公式为
[0033][0034]
其中,cat表示为concatenate操作,h0表示为预训练语言模型输出的[cls]句特征向量;表示为主体片段a的首位置特征,表示为主体片段a的尾位置特征,表示为候
选客体片段的首位置特征,表示为候选客体片段的尾位置特征;
[0035]
步骤s42、将送入re分类器,得到主体片段a与客体片段b之间的关系类型为l的预测结果公式为:
[0036][0037]
其中,wr,br表示为模型可训练的参数,l表示为关系的类型,表示为关系类型的集合;
[0038]
步骤43、计算re部分的交叉熵损失公式为:
[0039][0040]
其中,n表示样本数量,y
ab
表示是否为当前类别。
[0041]
步骤五、将损失与损失按照系数相加得到总损失
[0042]
进一步的,总损失的公式为:
[0043][0044]
其中,α,β为动态权重。
[0045]
步骤六、联合实体识别以及关系抽取的结果,得出最后的三元组《s,r,o》。
[0046]
本发明的有益效果:
[0047]
1、在输入预训练语言模型之前将词汇边界信息融入语句中,利用词语之间的位置关系,能够有效提升模型性能;
[0048]
2、同时对多个待预测片段进行计算,有效提高模型计算的效率;
[0049]
3、采用基于片段的分类形式,有效解决实体重叠的问题;
[0050]
4、任务模型共享预训练语言模型bert提供的词向量,并且在任务特征向量中融入相关语义信息,可进行联合抽取同时完成实体识别和关系抽取任务。
附图说明
[0051]
图1是本发明的融合词汇边界及语义信息的实体识别及关系抽取方法流程图;
[0052]
图2是本发明的预处理语言模型输入样例示意图;
[0053]
图3是本发明的实体识别任务特征向量的构建过程示意图;
[0054]
图4是本发明的关系抽取任务特征向量的构建过程示意图。
具体实施方式
[0055]
下面结合附图和实施例对本发明作进一步说明,此图为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
[0056]
如图1所示,一种融合词汇边界及语义信息的实体识别及关系抽取方法包括,以下步骤:
[0057]
步骤一、构建预处理语言模型的样本输入及标签;
[0058]
为了加速模型,在进行分词后的文本语句后拼接多个待预测片段,待预测的片段与文本语句中的片段共享位置信息,由于预处理语言模型只能一次处理有限长度的句子,
只选取m个位置相近的片段作为待预测片段拼接在句子末尾形成一条新的样本;
[0059]
具体包括:
[0060]
步骤11、先将文本语句进行分词,分词后的文本语句添加[cls]符号得到序列{[cls],t1,t2,t3,ti...,tn};其中,ti表示为文本语句经过分词后得到的词元token;
[0061]
步骤12、文本语句结尾组合m个待预测片段表示为{[cls];t1,t2,t3,...,tn;s1,s1,...,s1;s1,s2,s3,...,sm},{s1,s1,...,s1}表示添加的待预测片段的首位置信息,{s1,s2,s3,...,sm}表示添加的待预测片段的尾位置信息,直到遍历所有的片段位置信息s1~sn,添加的待预测片段的位置信息与文本中对应的词元共享位置信息,一共得到z条拼接的待预测片段;
[0062]
z的计算公式为:
[0063][0064]
其中,l表示待预测片段的长度,n表示分词后的文本语句中共包含n个词元,待预测片段长度l小于文本语句的长度n,输入bert的样本语句构建如图2所示,图中待预测片段的最大长度设置为4,最大长度可以根据具体应用场景自定义设置,指一个实体片段最大长度不超过4,最大长度可按照实际情况调节,取相邻的片段进行组合;
[0065]
步骤13、构造实体标签及关系标签,实体标签由实体边界(首尾)信息以及实体类型标签信息组成,关系标签由主客实体对的边界(首尾)信息以及关系类型标签组成;
[0066]
步骤二、将样本语句输入预训练bert模型,获取bert模型编码后产生的词向量以及[cls]句子向量;
[0067]
步骤三、构建实体识别任务(ner)相关的任务特征向量其中i,j表示为预测实体片段的首、尾标记;
[0068]
步骤31、将词向量特征信息进行最大池化得到hm,计算公式为:
[0069]hm
=maxpooling(h1,h2,...,hn);
[0070]
步骤32、对部分特征向量进行拼接得到任务特征计算公式为:
[0071][0072]
其中,cat表示concatenate操作,hi表示预测实体片段的首位置信息特征,hj表示预测实体片段的尾位置信息特征,表示为样本末尾添加的待预测片段的首位置信息特征,表示为样本末尾添加的待预测片段的尾位置信息特征,通过组合可以一次识别m个候选片段,如图3所示;
[0073]
步骤33、将送入ner分类器,得到实体类型为k的预测结果公式为:
[0074][0075]
其中,we,be表示为实体抽取和关系抽取的任务模型的可训练参数,k表示为实体的类型,ε表示为实体类型集合,则将结果加入集合e;
[0076]
步骤34、计算ner部分的交叉熵损失公式为:
[0077][0078]
其中,n表示样本数量,y
ij
表示是否为当前类别;
[0079]
步骤四、构建关系抽取任务(re)相关的任务特征向量其中a,b表示为待预测主体片段a、待预测客体片段b,片段a,b来自集合e,并且筛选出文本语句末尾拼接的待预测片段只含有片段b的样本;
[0080]
步骤41、对部分特征向量进行拼接得到任务特征计算公式为
[0081][0082]
其中,cat表示为concatenate操作,h0表示为预训练语言模型输出的[cls]句特征向量;表示为主体片段a的首位置特征,表示为主体片段a的尾位置特征,表示为候选客体片段的首位置特征,表示为候选客体片段的尾位置特征,如图4所示;
[0083]
步骤s42、将送入re分类器,得到主体片段a与客体片段b之间的关系类型为l的预测结果公式为:
[0084][0085]
其中,wr,br表示为模型可训练的参数,l表示为关系的类型,表示为关系类型的集合;
[0086]
步骤43、计算re部分的交叉熵损失公式为:
[0087][0088]
其中,n表示样本数量,y
ab
表示是否为当前类别;
[0089]
步骤五、将步骤34得到的损失与步骤43得到的损失按照系数相加得到实体识别和关系抽取的任务模型的总损失公式为:
[0090][0091]
其中,α,β为动态权重,随着训练的过程,权重α逐步递减,权重β逐步递增,通过最终得到的损失训练模型,选择adam优化器优化模型参数;
[0092]
步骤六、保存在验证集上效果最好的模型,在待预测样本中进行测试,得到最终测试结果,将步骤33得到的结果进行阈值筛选,结果大于0.5则表示预测实体片段属于某类实体类型,将步骤42得到的结果进行阈值筛选,结果大于0.5则表示预测片段a,b属于某类关系标签,联合预测的结果,得到最终三元组《s,r,o》。
[0093]
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1