本技术涉及云盘操作,特别是涉及一种可实时存储资料的云盘操作系统。
背景技术:
1、随自动存储电脑资料对企业的管理人员具有重要的意义和价值。首先,它能够提高工作和生活的效率。自动存储资料的云盘能够将不同设备上的文件同步到一起,使用户可以在不同的设备上随时浏览和编辑自己的文件,大大提高了效率,因此,为了实现同步数据的一致性和完整性,亟需一种可实时存储资料的云盘操作系统。
技术实现思路
1、为解决上述技术问题,本技术提供了一种可实时存储资料的云盘操作系统,通过分析本地文件夹和云端文件夹得到第一差异数据,对差异数据制定第一同步控制策略,根据第二差异数据对第一同步控制策略进行修正,得到多个第二同步控制策略,对多个第二同步控制策略进行仿真模拟,并进行同步效果评价,根据同步效果评价得到最优同步控制策略,提高了同步效率,保证了本地文件和云端文件的一致性和完整性。
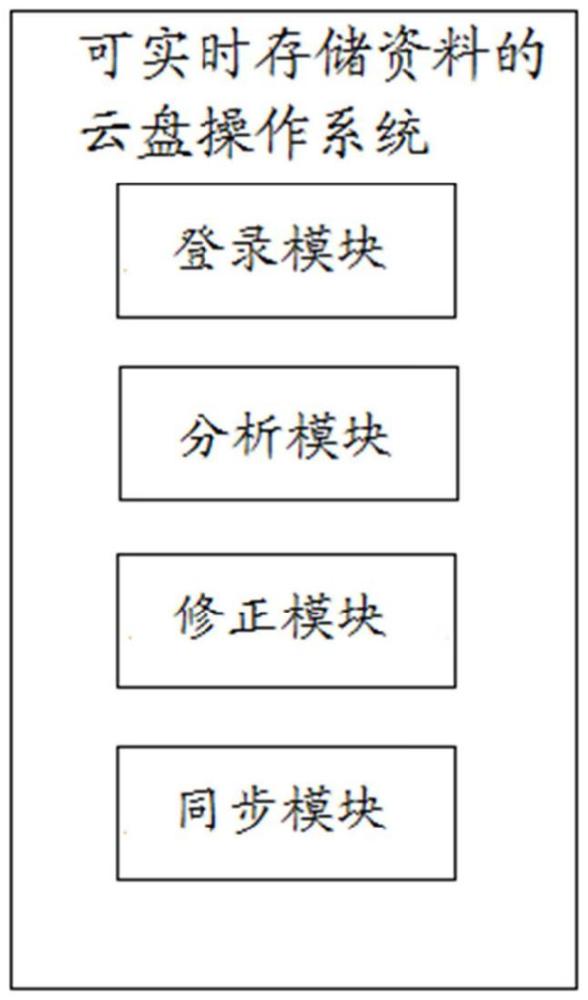
2、本技术的一些实施例中,提供了一种可实时存储资料的云盘操作系统,包括:
3、登录模块,用于登录云端客户端,并与云端服务端建立连接,实现本地文件夹与云端文件夹的绑定;
4、分析模块,用于对本地文件夹的第一数据内容和云端文件夹的第二数据内容进行分析,得到第一差异数据,对第一差异数据制定第一同步控制策略;
5、修正模块,用于按照第一同步控制策略对第一差异数据进行同步,获取第二差异数据,根据第二差异数据对第一同步控制策略进行修正,得到多个第二同步控制策略;
6、同步模块,用于对每个第二同步控制策略进行仿真模拟,得到仿真同步差异特征并进行同步效果评价,根据同步效果评价结果选定最优同步控制策略,按照最优同步控制策略对第二差异数据进行同步。
7、在本技术的一些实施例中,将本地文件夹与云端文件夹进行绑定,包括:
8、用户登录云端客户端,获取用户的登录请求以及所述登录请求对应的访问密钥;
9、基于所述访问密钥对所述登录请求进行认证,若认证通过,云端客户端与云端服务器建立连接,并将用户的登录请求并发送至云端服务器;
10、云端服务器接收所述登录请求并解析所述登录请求的登录信息,根据所述登录信息多个云端文件夹发送绑定请求,实现本地文件夹与云端文件夹的绑定。
11、在本技术的一些实施例中,对本地文件夹的第一数据内容和云端文件夹的第二数据内容进行分析,得到第一差异数据,包括:
12、实时获取本地文件夹的第一数据内容,基于cdc算法将第一数据内容切割成多个第一数据块,并设定每个第一数据块的第一边界值,根据第一数据块中的每个数据的重要系数生成每个第一数据块的第一重要系数;
13、实时获取云端文件夹的第二数据内容,基于cdc算法将第二数据内容切割成多个第二数据块,并设定每个第二数据块的第二边界值,根据第二数据块中的每个数据的重要系数生成每个第二数据块的第二重要系数;
14、将第一数据块的第一边界值与对应的第二数据块的第二边界值进行匹配,得到第一匹配结果,根据第一匹配结果得到第一差异数据块组;
15、将第一数据块的第一重要系数与对应的第二数据块的第二重要系数进行匹配,得到第二匹配结果,根据第二匹配结果得到第二差异数据块组;
16、将第一差异数据块组和第二差异数据块组进行对比,根据对比结果剔除重复的差异数据块组,对剩余的差异数据块组进行分析,得到第一差异数据,并对第一差异数据设定相应的索引标签以及索引标签编号,所述索引标签包括第一索引标签和第二索引标签。
17、在本技术的一些实施例中,对第一差异数据制定第一同步控制策略,包括:
18、获取每个第一差异数据的重要系数,基于重要系数-同步策略参考库,确定当前第一差异数据的重要系数对应的同步策略参考库,所述同步策略参考库包括当前第一差异数据的重要系数对应的多个历史同步控制策略;
19、根据第一差异数据的重要系数对应的多个历史同步控制策略的历史同步效果评价结果,筛选出每个第一差异数据对应的优选同步控制策略;
20、根据多个优选同步控制策略生成当前第一差异数据的第一同步控制策略。
21、在本技术的一些实施例中,获取第二差异数据,包括:
22、获取在第一同步控制策略后的本地文件夹的第三数据内容和云端文件夹的第四数据内容;
23、若第一差异数据的索引标签为第一索引标签,则在云端文件夹的第四数据内容中检索对应第一差异数据的索引标签编号,若检索结果为存在,则将对应的第一差异数据设定为同步数据,若检索结果为不存在,则将对应的第一差异数据设定为第二差异数据;
24、若第一差异数据的索引标签为第二索引标签,则在本地文件夹的第三数据内容中检索对应第一差异数据的索引标签编号,若检索结果为存在,则将对应的第一差异数据设定为同步数据,若检索结果为不存在,则将对应的第一差异数据设定为第二差异数据。
25、在本技术的一些实施例中,根据第二差异数据对第一同步控制策略进行修正,得到多个第二同步控制策略,包括:
26、预先设定有若干重要程度评价区间,每一重要程度评价区间映射有特定的修正系数区间;
27、根据第二差异数据的重要系数进行重要程度评价,并基于重要程度评价对应的重要程度评价区间,确定相应的修正系数区间;
28、基于相应的修正系数区间,对第一同步控制策略中的同步控制参数进行修正,生成多个修正方案,基于每个修正方案,对第一同步控制策进行修正,得到多个第二同步控制策略。
29、在本技术的一些实施例中,对每个第二同步控制策略进行仿真模拟,得到仿真同步差异特征,包括:
30、针对每一第二同步控制策略进行仿真模拟,生成仿真云盘同步控制模型;
31、将每一仿真云盘同步控制模型中的仿真同步结果与预设标准同步结果进行对比分析,确定出仿真同步差异特征,所述仿真同步差异特征包括仿真同步差异数据以及仿真同步时长差异。
32、在本技术的一些实施例中,对仿真同步差异特征进行同步效果评价,包括:
33、根据仿真同步差异数据确定仿真同步差异数据的个数以及对应的索引标签编号,对相应的索引标签编号进行赋值,得到多个索引标签编号的赋值系数;
34、根据仿真同步时长差异得到每个仿真同步数据的仿真同步时长与相应的标准同步时长的时长差值;
35、根据仿真同步差异数据的个数以及对应的赋值系数、仿真同步时长差异中的时长差值进行对应仿真云盘同步控制模型的同步效果评价;
36、所述同步效果评价的计算公式为:
37、
38、其中,k为同步效果评价结果,r1为第一转换系数,r2为第二转换系数,a1为仿真同步差异数据的权重系数,a2为仿真同步时长差异的权重系数,gi为第i个仿真同步差异数据的赋值系数,n为仿真同步差异数据的数量,tv为第v个仿真同步数据的仿真同步时长,t0v为第v个仿真同步数据的标准同步时长,s为仿真同步数据的数量。
39、在本技术的一些实施例中,根据同步效果评价结果选定最优同步控制策略,按照最优同步控制策略对第二差异数据进行同步,包括:
40、根据同步效果评价结果对仿真云盘同步控制模型进行排序,并按照排序第一的仿真云盘同步控制模型对应的第二同步控制策略对第二差异数据进行同步,实时采集同步结果,并计算当前同步结果与排序第一的仿真云盘同步控制模型的仿真同步结果的相似程度;
41、若相似程度大于预设相似程度阈值,则将排序第一的仿真云盘同步控制模型对应的第二同步控制策略设定为最优同步控制策略。
42、在本技术的一些实施例中,计算当前同步结果与排序第一的仿真云盘同步控制模型的仿真同步结果的相似程度,包括:
43、根据当前同步结果进行同步效果评价,并与排序第一的仿真云盘同步控制模型的同步效果评价结果进行作差,得到同步效果差值;
44、预先设定同步效果差值阈值;
45、若同步效果差值小于预设同步效果差值阈值,则判断前同步结果与排序第一的仿真云盘同步控制模型的仿真同步结果的相似程度大于预设相似程度阈值;
46、若同步效果差值大于预设同步效果差值阈值,则判断前同步结果与排序第一的仿真云盘同步控制模型的仿真同步结果的相似程度小于预设相似程度阈值。
47、本技术实施例的一种可实时存储资料的云盘操作系统,与现有技术相比,其有益效果在于:
48、通过分析本地文件夹和云端文件夹得到第一差异数据,对差异数据制定第一同步控制策略,根据第二差异数据对第一同步控制策略进行修正,得到多个第二同步控制策略,对多个第二同步控制策略进行仿真模拟,并进行同步效果评价,根据同步效果评价得到最优同步控制策略,提高了同步效率,保证了本地文件和云端文件的一致性和完整性。