一种基于HyperledgerFabric的数据高效共享方法与流程
本发明涉及区块链、物联网以及复杂网络社区划分技术领域,特别是涉及一种数据高效共享方法。
背景技术:
数据安全和中心化架构的弊端都是现实社会面临的实际问题,急需一个可行可信的解决方案,区块链应运而生。本质上来说,区块链可以看作是一个安全的数据库,和一般的数据库不同的是,首先,这个数据库添加了很多新的功能和安全保证,如权限管理、智能合约、共识机制、加密技术等等。其次,这个数据库不是由一个节点来维护的,而是加入区块链网络的所有节点或者多个节点通过共识机制来共同维护,每个参与维护的节点都存储着这个数据库的所有数据,这样便消除了完全中心化的很多弊端。社会科学和自然科学有很多规律都是相通的,可以相互借鉴的。基于这个思想,很多研究人员将人类以及人类社会的许多规律应用到了技术的各个领域。现实生活中,人们会被分成很多的社区、圈子、群组等等,从而有利于人类的生活以及信息的传播和共享。而网络是人类生活的另一种形式的载体,因此,社区划分的思想同样也可以应用到区块链网络中去。
以往的社区划分方法大多是集中式的,由中心化的服务器来直接决定社区的划分结果,某种程度上来说,这样的架构是不可信的,一旦发生节点故障或者作恶,系统就会瘫痪或者造成危害。因此,如何有效的提高架构的可用性和数据的安全性,从而避免中心化架构的缺点成为一个关键问题。另一方面,当代社会已经进入共享社会,数据共享成为热门,但是如何使共享的数据能够发挥应有的价值,不让它们成为数据垃圾同样成为一个重要问题。
针对这些问题,本发明提出了一种基于hyperledgerfabric的数据高效共享方法。
技术实现要素:
针对社区划分方法的中心化弊端以及数据共享的低效性问题,本发明旨在设计一种基于hyperledgerfabric的数据高效共享方法,将社区划分算法与区块链技术相结合,提高数据共享的有效性和安全性。
本发明的一种基于hyperledgerfabric的数据高效共享方,该方法包括以下流程:
步骤1:各个client节点将labeldata用community节点的公钥加密后和clienthash以及自身签名一起发送到community节点;
步骤2:community节点收集所有client的labeldata,用私钥解密后,验证数据,验证签名,计算roothash,并执行社区划分算法,该算法具体流程包括:
步骤2-1:读取所有节点的标签数据;
步骤2-2:设置初始k值为3,随机选取k个节点作为初始聚类中心;
步骤2-3:开始分配节点到k个社区,分配依据是将节点分配到与聚类中心节点相似度最大的社区,直到节点全部分配完毕;
步骤2-4:下一次迭代的开始,重新选取聚类中心,选取的聚类中心与其他节点的相似度和最大;
步骤2-5:重复2-3、2-4步骤,直到相似度误差平方和收敛;
步骤2-6:设置最大k值为根号n,k值逐次升高至最大k值,重复执行步骤2-2、2-3、2-4)、2-5四步,综合考虑相似度误差平凡和以及共享度评价指标,找到局部的最优社区划分结果;
步骤2-7:设置总迭代次数,重复执行步骤2-2、2-3、2-4、2-5、2-6五步,通过多轮迭代,找到全局最优的社区划分结果;
其中余弦相似度的公式具体为式(1)
式中,xi、yi分别表示两个节点标签数据映射到空间向量的坐标值;
共享度的公式具体为式(2)
式中,q表示一个client节点上传的社区公开数据条数;qtotal表示所有节点上传的社区公开数据条数;n表示一个社区中的节点总数;ui表示第i个client节点;cj表示第j个社区;
误差平方和(sse)的公式具体为式(3)
式中,k表示一共有k个社区;coss表示两个节点之间的相似度值;ci表示第i个社区;
步骤3:community节点将社区划分结果、roothash以及自身的签名广播发送到所有endorsedpeer节点;
步骤4:endorsedpeer节点通过roothash和clienthash验证labeldata的真实性,然后对结果进行验证,验证通过后对该笔交易背书;
步骤5:community节点收到足够数量的,并且得到了重要节点的背书之后,将社区划分结果和自身签名发送到order节点;
步骤6:order节点验证签名,将社区划分结果排序并打包成区块,广播到commitpeer节点;
步骤7:commitpeer节点进行最后的验证,验证成功后区块上链;
步骤8:client节点从peer节点获取自身的社区信息以及被共享的数据。
本发明所获得的积极的技术效果包括:
(1)本发明将hyperlederfabric应用于社区划分,使社区划分结果得到去中心化的安全性保证;
(2)本发明改进了区块结构,并将社区划分算法应用于区块链,使区块链中的数据可以得到高效的共享。
附图说明
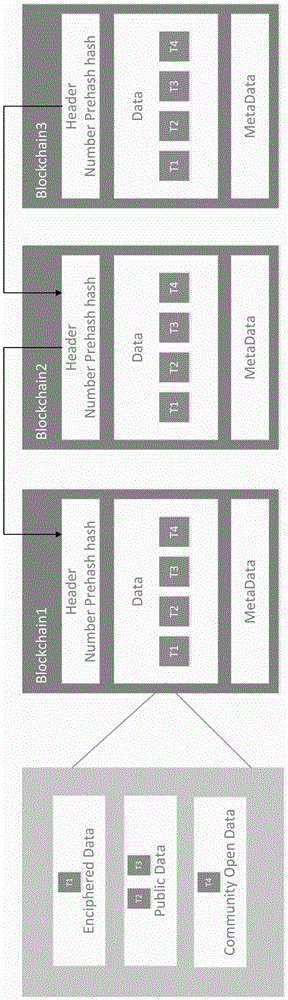
图1为本发明改进后的区块结构示意图;
图2为merkle的树状结构示意图;
图3为本发明的一种基于hyperledgerfabric的数据高效共享框架示意图;
图4为本发明的一种基于hyperledgerfabric的数据高效共享方法整体流程图。
具体实施方式
以下结合附图,对依据本发明设计的框架的结构、功能及作用详细说明如下详细说明如下。
如图1所示,为本发明改进后的区块结构示意图。我们将区块链中存储的交易按照隐私级别进行了分类,隐私级别从低到高依次是:公开数据,社区公开数据以及加密数据。其中,公开数据是指所有节点都可以看到的数据,社区公开数据是指同属一个社区的所有节点可以看到的数据,加密数据主要是指隐私数据以及想要买卖的数据。社区划分的主要目的就是使社区公开数据让更多的节点高效的共享。
我们首次将区块链技术、物联网技术和社区划分算法相结合,将农业物联网中的温室大棚作为数据的源头,用区块链的最新技术架构hyperledgerfabric来保证数据安全,将不可信的中心化架构转变为可信的需要共识结果上链的去中心化架构。最后,根据实际环境中数据的特点,对区块链网络中的节点进行社区划分,从而实现区块链中高效的数据共享。
如图3所示,为本发明的一种基于hyperledgerfabric的数据高效共享框架示意图。将区块链技术和社区划分算法有效结合,既结合了区块链本身的安全性,又实现了数据的高效共享。系统主要由以下几个部分组成:
client节点:该节点主要用于交易的发起,是外界网络和区块链网络的数据桥梁。
peer节点:该节点分为背书节点和确认节点。其中,背书节点主要用于交易的背书,确认节点主要用于区块的验证和上链。
order节点:该节点主要用于交易的排序以及区块的打包。
community节点:该节点主要用于社区划分算法的执行以及交易的发起。
本发明的一种基于hyperledgerfabric的数据高效共享方法提出了一个在区块链架构下进行社区划分,从而有效提高区块链中的数据共享程度的方法。假设这样一个场景,区块链中的节点按照兴趣数据划分成了不同的社区,每一个社区中的所有节点都有共同的喜好,这会方便我们进行信息的有效传播。1、我想要交易的数据是大家感兴趣的。2、我共享的数据是大家感兴趣的。3、我推荐的信息是大家感兴趣的。
如图4所示,为本发明的一种基于hyperledgerfabric的数据高效共享方法整体流程图。
步骤1:各个client节点将labeldata用community节点的公钥加密后和clienthash以及自身签名一起发送到community节点;
如图2所示,为merkle的树状结构示意图。merkle主要用来保证本步骤中节点标签数据(labeldata)的真实性,防止标签数据在传输过程中被篡改。首先计算各个节点标签数据的节点哈希值,然后再根据这些节点哈希值求出根哈希值。验证节点只需要验证根哈希与由原始数据计算得出的根哈希是否相同,就可以知道原始数据有没有被篡改。
步骤2:community节点收集所有client的labeldata,用私钥解密后,验证数据,验证签名,计算roothash,并执行社区划分算法,该算法具体流程包括:
(1)读取所有节点的标签数据;
(2)设置初始k值为3,随机选取k个节点作为初始聚类中心;
(3)开始分配节点到k个社区,分配依据是将节点分配到与聚类中心节点相似度最大的社区,直到节点全部分配完毕;
(4)下一次迭代的开始,重新选取聚类中心,选取的聚类中心与其他节点的相似度和最大;
(5)重复(3)、(4)步骤,直到相似度误差平方和收敛;
(6)设置最大k值为根号n,k值逐次升高至最大k值,重复执行(2)、(3)、(4)、(5)四步,综合考虑相似度误差平凡和以及共享度评价指标,找到局部的最优社区划分结果;
(7)设置总迭代次数,重复执行(2)、(3)、(4)、(5)、(6)五步,通过多轮迭代,找到全局最优的社区划分结果;
社区划分方法使用k-medoids聚类算法实现的,聚类算法的评测指标主要有两种,分别为误差平方和以及轮廓系数法。但是由于轮廓系数法的评测方法不稳定,所以选择误差平方和来评价聚类效果的好坏。在本发明中,sse是通过计算其他节点与中心节点的相似度的误差平方和得到的。
通过节点的标签数据进行相似度计算,选择余弦相似度来计算。其中余弦相似度的公式具体为式(1)
式中,xi、yi分别表示两个节点标签数据映射到空间向量的坐标值。
聚类效果用sse来评价并得出最优的聚类结果,但是该结果并不一定可以使数据得到高效共享。共享度的定义:所有节点的社区公开数据在所有社区中的共享程度。
共享度可以评价一次划分结果中,一条社区公开数据可以被平均共享给多少个节点。以此,来得出可以让数据高效共享的社区划分结果。因此,综合考虑sse和共享度两个评价指标。采取的方案如下:在保证社区划分结果准确性的基础之上,尽可能的提高共享度。因为要保证每一个节点所共享的社区公开数据都是同一个社区中其他节点所感兴趣的,这样才能保证数据的高效共享。单一的考虑共享度,只会使结果不尽人意,共享效率低。本发明利用共享度,用来评价社区划分的好坏,同时也作为社区划分算法迭代方向的判断依据。共享度的公式具体为式(2)
式中,q表示一个client节点上传的社区公开数据条数;qtotal表示所有节点上传的社区公开数据条数;n表示一个社区中的节点总数;ui表示第i个client节点;cj表示第j个社区。
误差平方和(sse)的公式具体为式(3)
式中,k表示一共有k个社区;coss表示两个节点之间的相似度值;ci表示第i个社区;
步骤3:community节点将社区划分结果、roothash以及自身的签名广播发送到所有endorsedpeer节点;
社区划分结果产生之后,首先要生成交易并发送到所有的背书节点进行背书,验证通过并且得到大量背书签名,交易才会生效。验证的内容主要有如下几点:1)验证社区划分节点的身份,是否是联盟链成员,节点角色是否是社区划分节点。2)根据clienthash和roothash验证标签数据的真实性。
步骤4:endorsedpeer节点通过roothash和clienthash验证labeldata的真实性,然后对结果进行验证(社区划分结果是否符合条件,用community节点的公钥来验证签名是否是联盟批准的community节点),防止中心服务器作恶,对结果进行篡改,保证结果的安全性,验证通过后对该笔交易背书。
- 还没有人留言评论。精彩留言会获得点赞!